 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum for Reasoning: Dense Intrinsic Signals in Policy Optimization
Jun 07, 2026Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for eliciting long-chain reasoning in large language models. However, existing methods based on Group Relative Policy Optimization (GRPO) rely on a binary outcome reward, which induces two structural failure modes: Zero-Advantage Collapse, in which all rollouts in a group share the same outcome and the gradient vanishes, and Hallucinated Certainty, in which the model becomes increasingly confident on incorrect rollouts late in training. We address both modes by densifying the reward with intrinsic signals computed entirely from the policy's own conditional probabilities, and propose ISPO (Intrinsic Signal Policy Optimization, which combines a sequence-level signal measuring how informative the thinking trajectory is for the final answer, with a token-level directional reward whose hallucinated-certainty hinge penalizes confidently-wrong predictions at critical decision tokens. Across three base models and five mathematical reasoning benchmarks, ISPO consistently outperforms competitive baselines, with the largest gains on the hardest benchmarks where zero-advantage collapse is most frequent, and training-dynamics diagnostics confirm that both failure modes are decreased.
FLaG: Fine-Grained Latent Grouping for Hallucination Detection
May 29, 2026Hallucinations in large language models (LLMs) arise from heterogeneous failure mechanisms, making reliable detection difficult for any single global uncertainty score. In this work, we formulate hallucination detection as a mechanism-aware evidence aggregation problem, where diverse representation- and token-level signals must be interpreted under multiple latent explanations. We propose FLaG, a lightweight hallucination detection framework that models correctness through a set of latent evidence groups. Each instance is softly associated with multiple groups via an energy-based routing mechanism, and group-conditional reliability signals are combined through a principled log-marginal aggregation. This design enables FLaG to capture heterogeneous hallucination patterns while remaining invariant to decision thresholds and evaluation metrics. The framework operates as a frozen-model head, requires no modification to the underlying language model, and incurs minimal computational overhead. We further provide a theoretical perspective that connects FLaG to optimal evidence aggregation under heterogeneous error mechanisms, showing that the Bayes-optimal test statistic necessarily admits a log-marginal form and that FLaG constitutes a tractable approximation with a controllable error bound. Extensive experiments across multiple benchmarks and LLM backbones demonstrate that FLaG consistently achieves SOTA performance, while exhibiting robust transfer across datasets and models, and remaining effective under limited supervision.
From Parameters to Data: A Task-Parameter-Guided Fine-Tuning Pipeline for Efficient LLM Alignment
May 20, 2026Adapting Large Language Models (LLMs) to specialized domains typically incurs high data and computational overhead. While prior efficiency efforts have largely treated data selection and parameter-efficient fine-tuning as isolated processes, our empirical analysis suggests they may be intrinsically coupled. We posit the Strong Map Hypothesis: a sparse subset of attention heads plays a dominant role in task-specific adaptation, acting as keys that unlock specific data patterns. Building on this observation, we propose From Parameters to Data (P2D), a unified framework that leverages these task-sensitive attention heads as a dual compass for both sample mining and structural pruning. To rigorously quantify the total pipeline cost, we introduce the Alignment Efficiency Ratio (AER) metric for both selection latency and training time. Mechanistically, P2D identifies critical heads via a lightweight proxy and uses them as a functional filter to curate high-affinity data, establishing a synergistic pipeline. Empirically, by updating merely 10% of attention heads on 10% of the data, P2D achieves an 8.3 pp performance gain over strong baselines and delivers a 7.0x end-to-end time speedup. These results validate that precise parameter-data synchronization eliminates redundancy, offering a new paradigm for efficient alignment.
TableGPT-R1: Advancing Tabular Reasoning Through Reinforcement Learning
Dec 23, 2025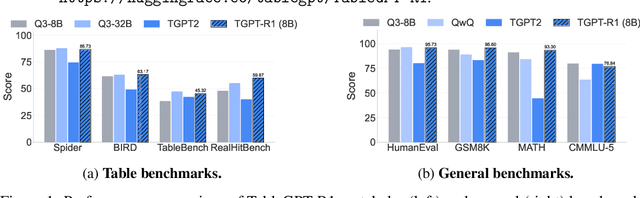
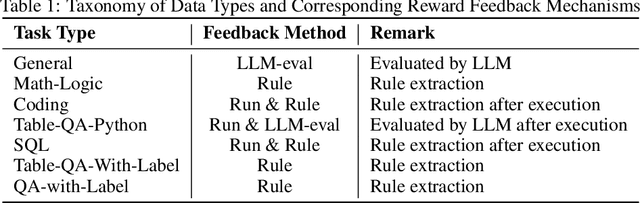
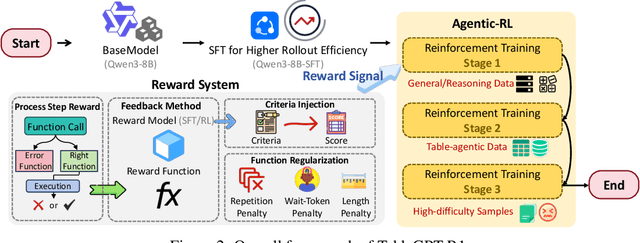
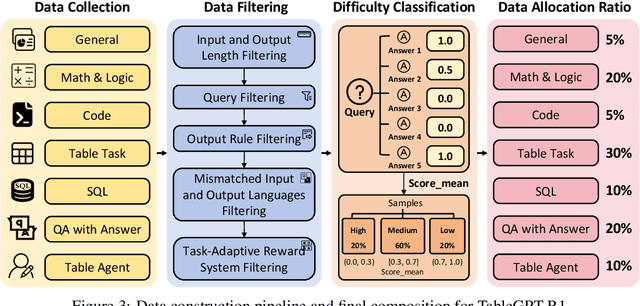
Tabular data serves as the backbone of modern data analysis and scientific research. While Large Language Models (LLMs) fine-tuned via Supervised Fine-Tuning (SFT) have significantly improved natural language interaction with such structured data, they often fall short in handling the complex, multi-step reasoning and robust code execution required for real-world table tasks. Reinforcement Learning (RL) offers a promising avenue to enhance these capabilities, yet its application in the tabular domain faces three critical hurdles: the scarcity of high-quality agentic trajectories with closed-loop code execution and environment feedback on diverse table structures, the extreme heterogeneity of feedback signals ranging from rigid SQL execution to open-ended data interpretation, and the risk of catastrophic forgetting of general knowledge during vertical specialization. To overcome these challenges and unlock advanced reasoning on complex tables, we introduce \textbf{TableGPT-R1}, a specialized tabular model built on a systematic RL framework. Our approach integrates a comprehensive data engineering pipeline that synthesizes difficulty-stratified agentic trajectories for both supervised alignment and RL rollouts, a task-adaptive reward system that combines rule-based verification with a criteria-injected reward model and incorporates process-level step reward shaping with behavioral regularization, and a multi-stage training framework that progressively stabilizes reasoning before specializing in table-specific tasks. Extensive evaluations demonstrate that TableGPT-R1 achieves state-of-the-art performance on authoritative benchmarks, significantly outperforming baseline models while retaining robust general capabilities. Our model is available at https://huggingface.co/tablegpt/TableGPT-R1.
TableGPT2: A Large Multimodal Model with Tabular Data Integration
Nov 04, 2024The emergence of models like GPTs, Claude, LLaMA, and Qwen has reshaped AI applications, presenting vast new opportunities across industries. Yet, the integration of tabular data remains notably underdeveloped, despite its foundational role in numerous real-world domains. This gap is critical for three main reasons. First, database or data warehouse data integration is essential for advanced applications; second, the vast and largely untapped resource of tabular data offers immense potential for analysis; and third, the business intelligence domain specifically demands adaptable, precise solutions that many current LLMs may struggle to provide. In response, we introduce TableGPT2, a model rigorously pre-trained and fine-tuned with over 593.8K tables and 2.36M high-quality query-table-output tuples, a scale of table-related data unprecedented in prior research. This extensive training enables TableGPT2 to excel in table-centric tasks while maintaining strong general language and coding abilities. One of TableGPT2's key innovations is its novel table encoder, specifically designed to capture schema-level and cell-level information. This encoder strengthens the model's ability to handle ambiguous queries, missing column names, and irregular tables commonly encountered in real-world applications. Similar to visual language models, this pioneering approach integrates with the decoder to form a robust large multimodal model. We believe the results are compelling: over 23 benchmarking metrics, TableGPT2 achieves an average performance improvement of 35.20% in the 7B model and 49.32% in the 72B model over prior benchmark-neutral LLMs, with robust general-purpose capabilities intact.
Navigate Complex Physical Worlds via Geometrically Constrained LLM
Oct 23, 2024
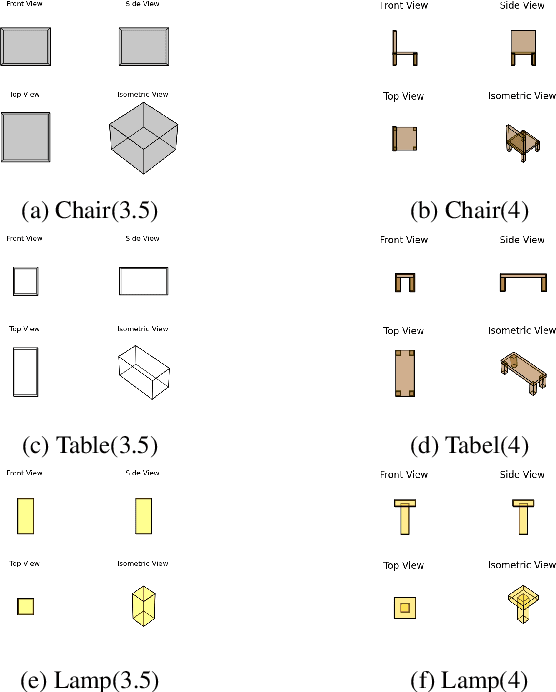
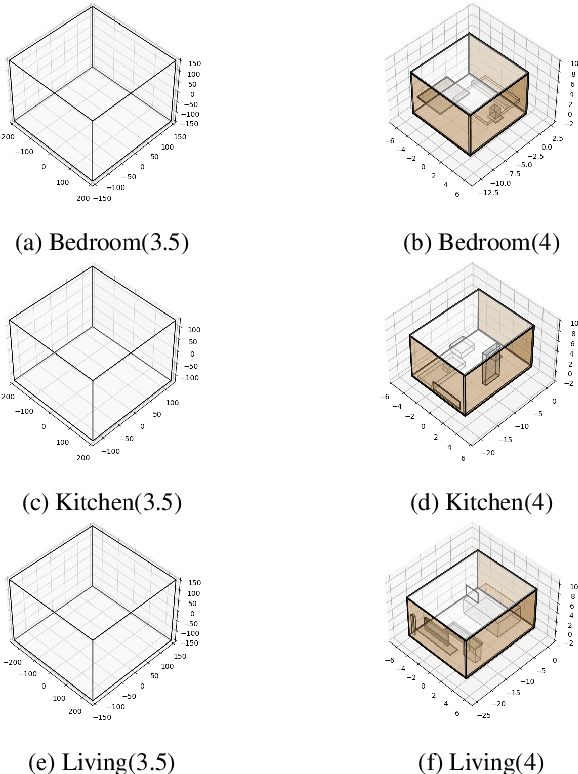

This study investigates the potential of Large Language Models (LLMs) for reconstructing and constructing the physical world solely based on textual knowledge. It explores the impact of model performance on spatial understanding abilities. To enhance the comprehension of geometric and spatial relationships in the complex physical world, the study introduces a set of geometric conventions and develops a workflow based on multi-layer graphs and multi-agent system frameworks. It examines how LLMs achieve multi-step and multi-objective geometric inference in a spatial environment using multi-layer graphs under unified geometric conventions. Additionally, the study employs a genetic algorithm, inspired by large-scale model knowledge, to solve geometric constraint problems. In summary, this work innovatively explores the feasibility of using text-based LLMs as physical world builders and designs a workflow to enhance their capabilities.
Data Contamination Calibration for Black-box LLMs
May 20, 2024


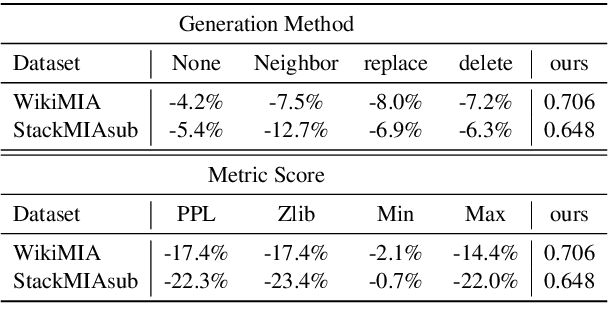
The rapid advancements of Large Language Models (LLMs) tightly associate with the expansion of the training data size. However, the unchecked ultra-large-scale training sets introduce a series of potential risks like data contamination, i.e. the benchmark data is used for training. In this work, we propose a holistic method named Polarized Augment Calibration (PAC) along with a new to-be-released dataset to detect the contaminated data and diminish the contamination effect. PAC extends the popular MIA (Membership Inference Attack) -- from machine learning community -- by forming a more global target at detecting training data to Clarify invisible training data. As a pioneering work, PAC is very much plug-and-play that can be integrated with most (if not all) current white- and black-box LLMs. By extensive experiments, PAC outperforms existing methods by at least 4.5%, towards data contamination detection on more 4 dataset formats, with more than 10 base LLMs. Besides, our application in real-world scenarios highlights the prominent presence of contamination and related issues.
TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT
Aug 07, 2023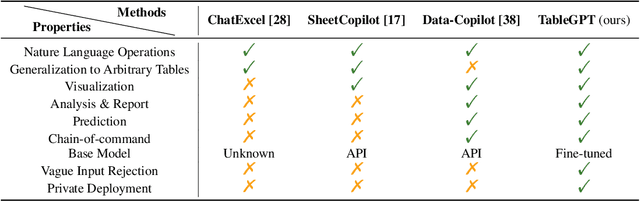



Tables are prevalent in real-world databases, requiring significant time and effort for humans to analyze and manipulate. The advancements in large language models (LLMs) have made it possible to interact with tables using natural language input, bringing this capability closer to reality. In this paper, we present TableGPT, a unified fine-tuned framework that enables LLMs to understand and operate on tables using external functional commands. It introduces the capability to seamlessly interact with tables, enabling a wide range of functionalities such as question answering, data manipulation (e.g., insert, delete, query, and modify operations), data visualization, analysis report generation, and automated prediction. TableGPT aims to provide convenience and accessibility to users by empowering them to effortlessly leverage tabular data. At the core of TableGPT lies the novel concept of global tabular representations, which empowers LLMs to gain a comprehensive understanding of the entire table beyond meta-information. By jointly training LLMs on both table and text modalities, TableGPT achieves a deep understanding of tabular data and the ability to perform complex operations on tables through chain-of-command instructions. Importantly, TableGPT offers the advantage of being a self-contained system rather than relying on external API interfaces. Moreover, it supports efficient data process flow, query rejection (when appropriate) and private deployment, enabling faster domain data fine-tuning and ensuring data privacy, which enhances the framework's adaptability to specific use cases.
CT-BERT: Learning Better Tabular Representations Through Cross-Table Pre-training
Jul 10, 2023

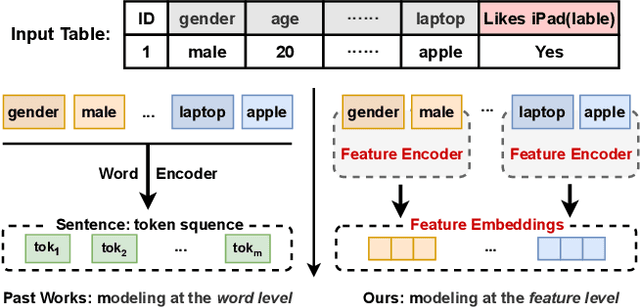
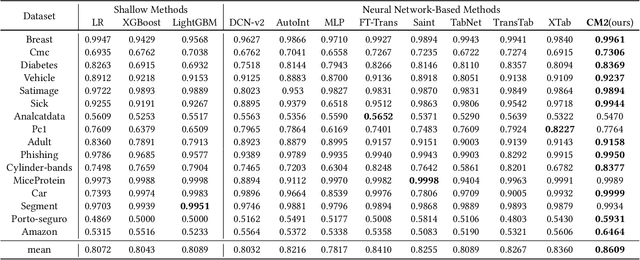
Tabular data -- also known as structured data -- is one of the most common data forms in existence, thanks to the stable development and scaled deployment of database systems in the last few decades. At present however, despite the blast brought by large pre-trained models in other domains such as ChatGPT or SAM, how can we extract common knowledge across tables at a scale that may eventually lead to generalizable representation for tabular data remains a full blank. Indeed, there have been a few works around this topic. Most (if not all) of them are limited in the scope of a single table or fixed form of a schema. In this work, we first identify the crucial research challenges behind tabular data pre-training, particularly towards the cross-table scenario. We position the contribution of this work in two folds: (i)-we collect and curate nearly 2k high-quality tabular datasets, each of which is guaranteed to possess clear semantics, clean labels, and other necessary meta information. (ii)-we propose a novel framework that allows cross-table pre-training dubbed as CT-BERT. Noticeably, in light of pioneering the scaled cross-table training, CT-BERT is fully compatible with both supervised and self-supervised schemes, where the specific instantiation of CT-BERT is very much dependent on the downstream tasks. We further propose and implement a contrastive-learning-based and masked table modeling (MTM) objective into CT-BERT, that is inspired from computer vision and natural language processing communities but sophistically tailored to tables. The extensive empirical results on 15 datasets demonstrate CT-BERT's state-of-the-art performance, where both its supervised and self-supervised setups significantly outperform the prior approaches.