 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-IDM: Grounding Video Generation for Executable Zero-shot Robot Motion
Jan 26, 2026The vision-language-action (VLA) paradigm has enabled powerful robotic control by leveraging vision-language models, but its reliance on large-scale, high-quality robot data limits its generalization. Generative world models offer a promising alternative for general-purpose embodied AI, yet a critical gap remains between their pixel-level plans and physically executable actions. To this end, we propose the Tool-Centric Inverse Dynamics Model (TC-IDM). By focusing on the tool's imagined trajectory as synthesized by the world model, TC-IDM establishes a robust intermediate representation that bridges the gap between visual planning and physical control. TC-IDM extracts the tool's point cloud trajectories via segmentation and 3D motion estimation from generated videos. Considering diverse tool attributes, our architecture employs decoupled action heads to project these planned trajectories into 6-DoF end-effector motions and corresponding control signals. This plan-and-translate paradigm not only supports a wide range of end-effectors but also significantly improves viewpoint invariance. Furthermore, it exhibits strong generalization capabilities across long-horizon and out-of-distribution tasks, including interacting with deformable objects. In real-world evaluations, the world model with TC-IDM achieves an average success rate of 61.11 percent, with 77.7 percent on simple tasks and 38.46 percent on zero-shot deformable object tasks. It substantially outperforms end-to-end VLA-style baselines and other inverse dynamics models.
Learning from Prompt itself: the Hierarchical Attribution Prompt Optimization
Jan 06, 2026Optimization is fundamental across numerous disciplines, typically following an iterative process of refining an initial solution to enhance performance. This principle is equally critical in prompt engineering, where designing effective prompts for large language models constitutes a complex optimization challenge. A structured optimization approach requires automated or semi-automated procedures to develop improved prompts, thereby reducing manual effort, improving performance, and yielding an interpretable process. However, current prompt optimization methods often induce prompt drift, where new prompts fix prior failures but impair performance on previously successful tasks. Additionally, generating prompts from scratch can compromise interpretability. To address these limitations, this study proposes the Hierarchical Attribution Prompt Optimization (HAPO) framework, which introduces three innovations: (1) a dynamic attribution mechanism targeting error patterns in training data and prompting history, (2) semantic-unit optimization for editing functional prompt segments, and (3) multimodal-friendly progression supporting both end-to-end LLM and LLM-MLLM workflows. Applied in contexts like single/multi-image QA (e.g., OCRV2) and complex task analysis (e.g., BBH), HAPO demonstrates enhanced optimization efficiency, outperforming comparable automated prompt optimization methods and establishing an extensible paradigm for scalable prompt engineering.
TableGPT-R1: Advancing Tabular Reasoning Through Reinforcement Learning
Dec 23, 2025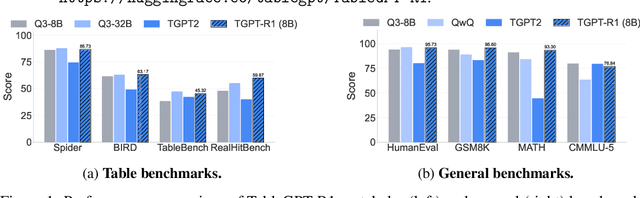
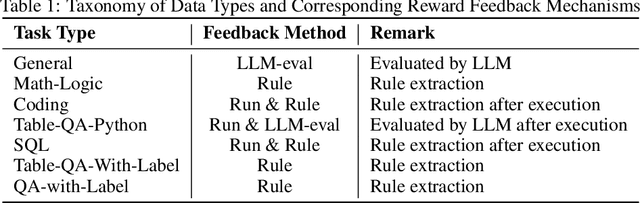
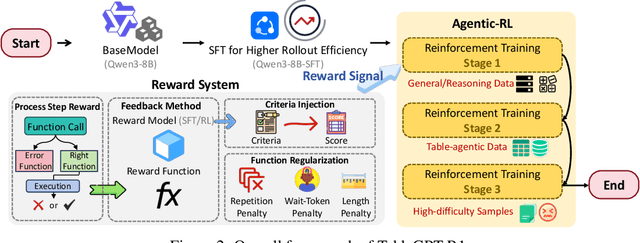
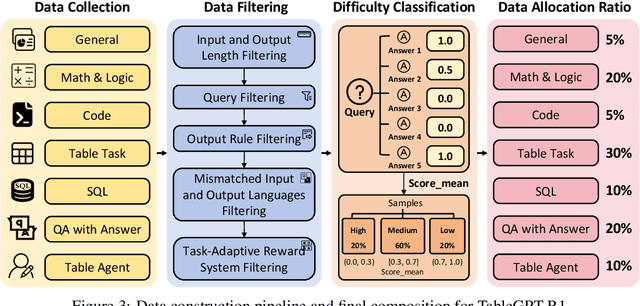
Tabular data serves as the backbone of modern data analysis and scientific research. While Large Language Models (LLMs) fine-tuned via Supervised Fine-Tuning (SFT) have significantly improved natural language interaction with such structured data, they often fall short in handling the complex, multi-step reasoning and robust code execution required for real-world table tasks. Reinforcement Learning (RL) offers a promising avenue to enhance these capabilities, yet its application in the tabular domain faces three critical hurdles: the scarcity of high-quality agentic trajectories with closed-loop code execution and environment feedback on diverse table structures, the extreme heterogeneity of feedback signals ranging from rigid SQL execution to open-ended data interpretation, and the risk of catastrophic forgetting of general knowledge during vertical specialization. To overcome these challenges and unlock advanced reasoning on complex tables, we introduce \textbf{TableGPT-R1}, a specialized tabular model built on a systematic RL framework. Our approach integrates a comprehensive data engineering pipeline that synthesizes difficulty-stratified agentic trajectories for both supervised alignment and RL rollouts, a task-adaptive reward system that combines rule-based verification with a criteria-injected reward model and incorporates process-level step reward shaping with behavioral regularization, and a multi-stage training framework that progressively stabilizes reasoning before specializing in table-specific tasks. Extensive evaluations demonstrate that TableGPT-R1 achieves state-of-the-art performance on authoritative benchmarks, significantly outperforming baseline models while retaining robust general capabilities. Our model is available at https://huggingface.co/tablegpt/TableGPT-R1.
RTFF: Random-to-Target Fabric Flattening Policy using Dual-Arm Manipulator
Oct 01, 2025Robotic fabric manipulation in garment production for sewing, cutting, and ironing requires reliable flattening and alignment, yet remains challenging due to fabric deformability, effectively infinite degrees of freedom, and frequent occlusions from wrinkles, folds, and the manipulator's End-Effector (EE) and arm. To address these issues, this paper proposes the first Random-to-Target Fabric Flattening (RTFF) policy, which aligns a random wrinkled fabric state to an arbitrary wrinkle-free target state. The proposed policy adopts a hybrid Imitation Learning-Visual Servoing (IL-VS) framework, where IL learns with explicit fabric models for coarse alignment of the wrinkled fabric toward a wrinkle-free state near the target, and VS ensures fine alignment to the target. Central to this framework is a template-based mesh that offers precise target state representation, wrinkle-aware geometry prediction, and consistent vertex correspondence across RTFF manipulation steps, enabling robust manipulation and seamless IL-VS switching. Leveraging the power of mesh, a novel IL solution for RTFF-Mesh Action Chunking Transformer (MACT)-is then proposed by conditioning the mesh information into a Transformer-based policy. The RTFF policy is validated on a real dual-arm tele-operation system, showing zero-shot alignment to different targets, high accuracy, and strong generalization across fabrics and scales. Project website: https://kaitang98.github.io/RTFF_Policy/
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
CoIFNet: A Unified Framework for Multivariate Time Series Forecasting with Missing Values
Jun 16, 2025Multivariate time series forecasting (MTSF) is a critical task with broad applications in domains such as meteorology, transportation, and economics. Nevertheless, pervasive missing values caused by sensor failures or human errors significantly degrade forecasting accuracy. Prior efforts usually employ an impute-then-forecast paradigm, leading to suboptimal predictions due to error accumulation and misaligned objectives between the two stages. To address this challenge, we propose the Collaborative Imputation-Forecasting Network (CoIFNet), a novel framework that unifies imputation and forecasting to achieve robust MTSF in the presence of missing values. Specifically, CoIFNet takes the observed values, mask matrix and timestamp embeddings as input, processing them sequentially through the Cross-Timestep Fusion (CTF) and Cross-Variate Fusion (CVF) modules to capture temporal dependencies that are robust to missing values. We provide theoretical justifications on how our CoIFNet learning objective improves the performance bound of MTSF with missing values. Through extensive experiments on challenging MSTF benchmarks, we demonstrate the effectiveness and computational efficiency of our proposed approach across diverse missing-data scenarios, e.g., CoIFNet outperforms the state-of-the-art method by $\underline{\textbf{24.40}}$% ($\underline{\textbf{23.81}}$%) at a point (block) missing rate of 0.6, while improving memory and time efficiency by $\underline{\boldsymbol{4.3\times}}$ and $\underline{\boldsymbol{2.1\times}}$, respectively.
Mitigating Hallucinations via Inter-Layer Consistency Aggregation in Large Vision-Language Models
May 18, 2025Despite the impressive capabilities of Large Vision-Language Models (LVLMs), they remain susceptible to hallucinations-generating content that is inconsistent with the input image. Existing training-free hallucination mitigation methods often suffer from unstable performance and high sensitivity to hyperparameter settings, limiting their practicality and broader adoption. In this paper, we propose a novel decoding mechanism, Decoding with Inter-layer Consistency via Layer Aggregation (DCLA), which requires no retraining, fine-tuning, or access to external knowledge bases. Specifically, our approach constructs a dynamic semantic reference by aggregating representations from previous layers, and corrects semantically deviated layers to enforce inter-layer consistency. The method allows DCLA to robustly mitigate hallucinations across multiple LVLMs. Experiments on hallucination benchmarks such as MME and POPE demonstrate that DCLA effectively reduces hallucinations while enhancing the reliability and performance of LVLMs.
STAR: Stage-Wise Attention-Guided Token Reduction for Efficient Large Vision-Language Models Inference
May 18, 2025Although large vision-language models (LVLMs) leverage rich visual token representations to achieve strong performance on multimodal tasks, these tokens also introduce significant computational overhead during inference. Existing training-free token pruning methods typically adopt a single-stage strategy, focusing either on visual self-attention or visual-textual cross-attention. However, such localized perspectives often overlook the broader information flow across the model, leading to substantial performance degradation, especially under high pruning ratios. In this work, we propose STAR (Stage-wise Attention-guided token Reduction), a training-free, plug-and-play framework that approaches token pruning from a global perspective. Instead of pruning at a single point, STAR performs attention-guided reduction in two complementary stages: an early-stage pruning based on visual self-attention to remove redundant low-level features, and a later-stage pruning guided by cross-modal attention to discard task-irrelevant tokens. This holistic approach allows STAR to significantly reduce computational cost while better preserving task-critical information. Extensive experiments across multiple LVLM architectures and benchmarks show that STAR achieves strong acceleration while maintaining comparable, and in some cases even improved performance.
Beyond Fixed Variables: Expanding-variate Time Series Forecasting via Flat Scheme and Spatio-temporal Focal Learning
Feb 21, 2025Multivariate Time Series Forecasting (MTSF) has long been a key research focus. Traditionally, these studies assume a fixed number of variables, but in real-world applications, Cyber-Physical Systems often expand as new sensors are deployed, increasing variables in MTSF. In light of this, we introduce a novel task, Expanding-variate Time Series Forecasting (EVTSF). This task presents unique challenges, specifically (1) handling inconsistent data shapes caused by adding new variables, and (2) addressing imbalanced spatio-temporal learning, where expanding variables have limited observed data due to the necessity for timely operation. To address these challenges, we propose STEV, a flexible spatio-temporal forecasting framework. STEV includes a new Flat Scheme to tackle the inconsistent data shape issue, which extends the graph-based spatio-temporal modeling architecture into 1D space by flattening the 2D samples along the variable dimension, making the model variable-scale-agnostic while still preserving dynamic spatial correlations through a holistic graph. We introduce a novel Spatio-temporal Focal Learning strategy that incorporates a negative filter to resolve potential conflicts between contrastive learning and graph representation, and a focal contrastive loss as its core to guide the framework to focus on optimizing the expanding variables. We benchmark EVTSF performance using three real-world datasets and compare it against three potential solutions employing SOTA MTSF models tailored for EVSTF. Experimental results show that STEV significantly outperforms its competitors, particularly on expanding variables. Notably, STEV, with only 5% of observations from the expanding period, is on par with SOTA MTSF models trained with complete observations. Further exploration of various expanding strategies underscores the generalizability of STEV in real-world applications.
Monocular Event-Inertial Odometry with Adaptive decay-based Time Surface and Polarity-aware Tracking
Sep 21, 2024Event cameras have garnered considerable attention due to their advantages over traditional cameras in low power consumption, high dynamic range, and no motion blur. This paper proposes a monocular event-inertial odometry incorporating an adaptive decay kernel-based time surface with polarity-aware tracking. We utilize an adaptive decay-based Time Surface to extract texture information from asynchronous events, which adapts to the dynamic characteristics of the event stream and enhances the representation of environmental textures. However, polarity-weighted time surfaces suffer from event polarity shifts during changes in motion direction. To mitigate its adverse effects on feature tracking, we optimize the feature tracking by incorporating an additional polarity-inverted time surface to enhance the robustness. Comparative analysis with visual-inertial and event-inertial odometry methods shows that our approach outperforms state-of-the-art techniques, with competitive results across various datasets.