 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Classification and Reconstruction: Cooperative Time Series Anomaly Detection
May 28, 2026Time series anomaly detection (TSAD) has long been a hot research topic in data mining due to its various applications. Recent studies challenge the effectiveness of popular deep learning methods for TSAD, suggesting their failure in detecting subtle and prolonged anomalies. Outlier Exposure (OE) and Masked Autoencoder (MAE) emerge as two promising paradigms (classification and reconstruction) for solving the above problems. However, OE-based methods are constrained by poor generalization, while MAE-based methods are limited by masking misalignment issues. To address these limitations, this paper proposes a novel framework, CoAD, which unifies the two paradigms to leverage their complementary strengths while mitigating their respective weaknesses. In this framework, the classification module generates probability-informed soft masks for the reconstruction module, which in turn alleviates the generalization problem of the classification module. This cooperative design enables CoAD to effectively detect subtle and complex anomalies that are often overlooked by existing methods. Additionally, the classification module is carefully designed to resolve issues related to improper classification granularity and the neglect of frequency information. Extensive experiments on high-quality benchmark datasets, conducted under rigorous evaluation protocols, demonstrate that CoAD significantly outperforms both state-of-the-art deep learning and traditional data mining methods, highlighting the potential of deep learning in TSAD. Moreover, CoAD is lightweight and substantially faster than existing SOTA methods, demonstrating its practical value for large-scale, real-time applications.
AccLock: Unlocking Identity with Heartbeat Using In-Ear Accelerometers
May 12, 2026The widespread use of earphones has enabled various sensing applications, including activity recognition, health monitoring, and context-aware computing. Among these, earphone-based user authentication has become a key technique by leveraging unique biometric features. However, existing earphone-based authentication systems face key limitations: they either require explicit user interaction or active speaker output, or suffer from poor accessibility and vulnerability to environmental noise, which hinders large-scale deployment. In this paper, we propose a passive authentication system, called AccLock, which leverages distinctive features extracted from in-ear BCG signals to enable secure and unobtrusive user verification. Our system offers several advantages over previous systems, including zero-involvement for both the device and the user, ubiquitous, and resilient to environmental noise. To realize this, we first design a two-stage denoising scheme to suppress both inherent and sporadic interference. To extract user-specific features, we then propose a disentanglement-based deep learning model, HIDNet, which explicitly separates user-specific features from shared nuisance components. Lastly, we develop a scalable authentication framework based on a Siamese network that eliminates the need for per-user classifier training. We conduct extensive experiments with 33 participants, achieving an average FAR of 3.13% and FRR of 2.99%, which demonstrates the practical feasibility of AccLock.
Can LLMs Fool Graph Learning? Exploring Universal Adversarial Attacks on Text-Attributed Graphs
Mar 22, 2026Text-attributed graphs (TAGs) enhance graph learning by integrating rich textual semantics and topological context for each node. While boosting expressiveness, they also expose new vulnerabilities in graph learning through text-based adversarial surfaces. Recent advances leverage diverse backbones, such as graph neural networks (GNNs) and pre-trained language models (PLMs), to capture both structural and textual information in TAGs. This diversity raises a key question: How can we design universal adversarial attacks that generalize across architectures to assess the security of TAG models? The challenge arises from the stark contrast in how different backbones-GNNs and PLMs-perceive and encode graph patterns, coupled with the fact that many PLMs are only accessible via APIs, limiting attacks to black-box settings. To address this, we propose BadGraph, a novel attack framework that deeply elicits large language models (LLMs) understanding of general graph knowledge to jointly perturb both node topology and textual semantics. Specifically, we design a target influencer retrieval module that leverages graph priors to construct cross-modally aligned attack shortcuts, thereby enabling efficient LLM-based perturbation reasoning. Experiments show that BadGraph achieves universal and effective attacks across GNN- and LLM-based reasoners, with up to a 76.3% performance drop, while theoretical and empirical analyses confirm its stealthy yet interpretable nature.
Beyond Fixed Variables: Expanding-variate Time Series Forecasting via Flat Scheme and Spatio-temporal Focal Learning
Feb 21, 2025



Multivariate Time Series Forecasting (MTSF) has long been a key research focus. Traditionally, these studies assume a fixed number of variables, but in real-world applications, Cyber-Physical Systems often expand as new sensors are deployed, increasing variables in MTSF. In light of this, we introduce a novel task, Expanding-variate Time Series Forecasting (EVTSF). This task presents unique challenges, specifically (1) handling inconsistent data shapes caused by adding new variables, and (2) addressing imbalanced spatio-temporal learning, where expanding variables have limited observed data due to the necessity for timely operation. To address these challenges, we propose STEV, a flexible spatio-temporal forecasting framework. STEV includes a new Flat Scheme to tackle the inconsistent data shape issue, which extends the graph-based spatio-temporal modeling architecture into 1D space by flattening the 2D samples along the variable dimension, making the model variable-scale-agnostic while still preserving dynamic spatial correlations through a holistic graph. We introduce a novel Spatio-temporal Focal Learning strategy that incorporates a negative filter to resolve potential conflicts between contrastive learning and graph representation, and a focal contrastive loss as its core to guide the framework to focus on optimizing the expanding variables. We benchmark EVTSF performance using three real-world datasets and compare it against three potential solutions employing SOTA MTSF models tailored for EVSTF. Experimental results show that STEV significantly outperforms its competitors, particularly on expanding variables. Notably, STEV, with only 5% of observations from the expanding period, is on par with SOTA MTSF models trained with complete observations. Further exploration of various expanding strategies underscores the generalizability of STEV in real-world applications.
Not All Data are Good Labels: On the Self-supervised Labeling for Time Series Forecasting
Feb 21, 2025



Time Series Forecasting (TSF) is a crucial task in various domains, yet existing TSF models rely heavily on high-quality data and insufficiently exploit all available data. This paper explores a novel self-supervised approach to re-label time series datasets by inherently constructing candidate datasets. During the optimization of a simple reconstruction network, intermediates are used as pseudo labels in a self-supervised paradigm, improving generalization for any predictor. We introduce the Self-Correction with Adaptive Mask (SCAM), which discards overfitted components and selectively replaces them with pseudo labels generated from reconstructions. Additionally, we incorporate Spectral Norm Regularization (SNR) to further suppress overfitting from a loss landscape perspective. Our experiments on eleven real-world datasets demonstrate that SCAM consistently improves the performance of various backbone models. This work offers a new perspective on constructing datasets and enhancing the generalization of TSF models through self-supervised learning.
DarkFarseer: Inductive Spatio-temporal Kriging via Hidden Style Enhancement and Sparsity-Noise Mitigation
Jan 06, 2025



With the rapid growth of the Internet of Things and Cyber-Physical Systems, widespread sensor deployment has become essential. However, the high costs of building sensor networks limit their scale and coverage, making fine-grained deployment challenging. Inductive Spatio-Temporal Kriging (ISK) addresses this issue by introducing virtual sensors. Based on graph neural networks (GNNs) extracting the relationships between physical and virtual sensors, ISK can infer the measurements of virtual sensors from physical sensors. However, current ISK methods rely on conventional message-passing mechanisms and network architectures, without effectively extracting spatio-temporal features of physical sensors and focusing on representing virtual sensors. Additionally, existing graph construction methods face issues of sparse and noisy connections, destroying ISK performance. To address these issues, we propose DarkFarseer, a novel ISK framework with three key components. First, we propose the Neighbor Hidden Style Enhancement module with a style transfer strategy to enhance the representation of virtual nodes in a temporal-then-spatial manner to better extract the spatial relationships between physical and virtual nodes. Second, we propose Virtual-Component Contrastive Learning, which aims to enrich the node representation by establishing the association between the patterns of virtual nodes and the regional patterns within graph components. Lastly, we design a Similarity-Based Graph Denoising Strategy, which reduces the connectivity strength of noisy connections around virtual nodes and their neighbors based on their temporal information and regional spatial patterns. Extensive experiments demonstrate that DarkFarseer significantly outperforms existing ISK methods.
LibEER: A Comprehensive Benchmark and Algorithm Library for EEG-based Emotion Recognition
Oct 13, 2024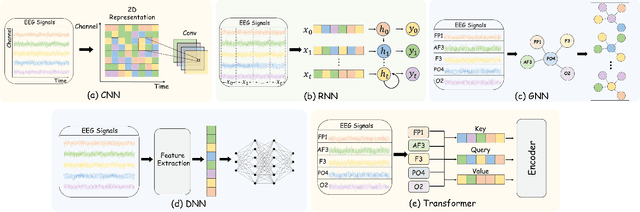
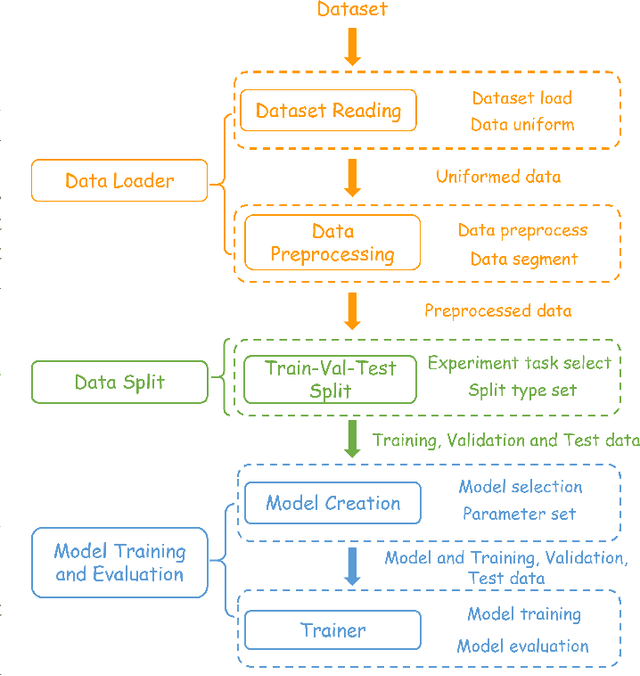
EEG-based emotion recognition (EER) is garnering increasing attention due to its potential in understanding and analyzing human emotions. Recently, significant advancements have been achieved using various deep learning-based techniques to address the EER problem. However, the absence of a convincing benchmark and open-source codebase complicates fair comparisons between different models and poses reproducibility challenges for practitioners. These issues considerably impede progress in this field. In light of this, we propose a comprehensive benchmark and algorithm library (LibEER) for fair comparisons in EER by making most of the implementation details of different methods consistent and using the same single codebase in PyTorch. In response to these challenges, we propose LibEER, a comprehensive benchmark and algorithm library for fair comparisons in EER, by ensuring consistency in the implementation details of various methods and utilizing a single codebase in PyTorch. LibEER establishes a unified evaluation framework with standardized experimental settings, enabling unbiased evaluations of over ten representative deep learning-based EER models across the four most commonly used datasets. Additionally, we conduct an exhaustive and reproducible comparison of the performance and efficiency of popular models, providing valuable insights for researchers in selecting and designing EER models. We aspire for our work to not only lower the barriers for beginners entering the field of EEG-based emotion recognition but also promote the standardization of research in this domain, thereby fostering steady development. The source code is available at \url{https://github.com/ButterSen/LibEER}.
Conditional Lagrangian Wasserstein Flow for Time Series Imputation
Oct 10, 2024



Time series imputation is important for numerous real-world applications. To overcome the limitations of diffusion model-based imputation methods, e.g., slow convergence in inference, we propose a novel method for time series imputation in this work, called Conditional Lagrangian Wasserstein Flow. The proposed method leverages the (conditional) optimal transport theory to learn the probability flow in a simulation-free manner, in which the initial noise, missing data, and observations are treated as the source distribution, target distribution, and conditional information, respectively. According to the principle of least action in Lagrangian mechanics, we learn the velocity by minimizing the corresponding kinetic energy. Moreover, to incorporate more prior information into the model, we parameterize the derivative of a task-specific potential function via a variational autoencoder, and combine it with the base estimator to formulate a Rao-Blackwellized sampler. The propose model allows us to take less intermediate steps to produce high-quality samples for inference compared to existing diffusion methods. Finally, the experimental results on the real-word datasets show that the proposed method achieves competitive performance on time series imputation compared to the state-of-the-art methods.
GLADformer: A Mixed Perspective for Graph-level Anomaly Detection
Jun 02, 2024Graph-Level Anomaly Detection (GLAD) aims to distinguish anomalous graphs within a graph dataset. However, current methods are constrained by their receptive fields, struggling to learn global features within the graphs. Moreover, most contemporary methods are based on spatial domain and lack exploration of spectral characteristics. In this paper, we propose a multi-perspective hybrid graph-level anomaly detector namely GLADformer, consisting of two key modules. Specifically, we first design a Graph Transformer module with global spectrum enhancement, which ensures balanced and resilient parameter distributions by fusing global features and spectral distribution characteristics. Furthermore, to uncover local anomalous attributes, we customize a band-pass spectral GNN message passing module that further enhances the model's generalization capability. Through comprehensive experiments on ten real-world datasets from multiple domains, we validate the effectiveness and robustness of GLADformer. This demonstrates that GLADformer outperforms current state-of-the-art models in graph-level anomaly detection, particularly in effectively capturing global anomaly representations and spectral characteristics.
E2USD: Efficient-yet-effective Unsupervised State Detection for Multivariate Time Series
Mar 01, 2024



We propose E2USD that enables efficient-yet-accurate unsupervised MTS state detection. E2USD exploits a Fast Fourier Transform-based Time Series Compressor (FFTCompress) and a Decomposed Dual-view Embedding Module (DDEM) that together encode input MTSs at low computational overhead. Additionally, we propose a False Negative Cancellation Contrastive Learning method (FNCCLearning) to counteract the effects of false negatives and to achieve more cluster-friendly embedding spaces. To reduce computational overhead further in streaming settings, we introduce Adaptive Threshold Detection (ADATD). Comprehensive experiments with six baselines and six datasets offer evidence that E2USD is capable of SOTA accuracy at significantly reduced computational overhead. Our code is available at https://github.com/AI4CTS/E2Usd.