 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Uplift Modeling under Structural Biases: Insights into Metric Stability and Model Robustness
Mar 21, 2026In personalized marketing, uplift models estimate incremental effects by modeling how customer behavior changes under alternative treatments. However, real-world data often exhibit biases - such as selection bias, spillover effects, and unobserved confounding - which adversely affect both estimation accuracy and metric validity. Despite the importance of bias-aware assessment, a lack of systematic studies persists. To bridge this gap, we design a systematic benchmarking framework. Unlike standard predictive tasks, real-world uplift datasets lack counterfactual ground truth, rendering direct metric validation infeasible. Therefore, a semi-synthetic approach serves as a critical enabler for systematic benchmarking, effectively bridging the gap by retaining real-world feature dependencies while providing the ground truth needed to isolate structural biases. Our investigations reveal that: (i) uplift targeting and prediction can manifest as distinct objectives, where proficiency in one does not ensure efficacy in the other; (ii) while many models exhibit inconsistent performance under diverse biases, TARNet shows notable robustness, providing insights for subsequent model design; (iii) evaluation metric stability is linked to mathematical alignment with the ATE, suggesting that ATE-approximating metrics yield more consistent model rankings under structural data imperfections. These findings suggest the need for more robust uplift models and metrics. Code will be released upon acceptance.
Hierarchy of extreme-event predictability in turbulence revealed by machine learning
Mar 14, 2026Extreme-event predictability in turbulence is strongly state dependent, yet event-by-event predictability horizons are difficult to quantify without access to governing equations or costly perturbation ensembles. Here we train an autoregressive conditional diffusion model on direct numerical simulations of the two-dimensional Kolmogorov flow and use a CRPS-based skill score to define an event-wise predictability horizon. Enstrophy extremes exhibit a pronounced hierarchy: forecast skill persists from $\approx 1$ to $> 4$ Lyapunov times across events. Spectral filtering shows that these horizons are controlled predominantly by large-scale structures. Extremes are preceded by intense strain cores organizing quadrupolar vortex packets, whose lifetime sharply separates long- from short-horizon events. These results identify coherent-structure persistence as a governing mechanism for the predictability of turbulence extremes and provide a data-driven route to diagnose predictability limits from observations.
Hepato-LLaVA: An Expert MLLM with Sparse Topo-Pack Attention for Hepatocellular Pathology Analysis on Whole Slide Images
Feb 26, 2026Hepatocellular Carcinoma diagnosis relies heavily on the interpretation of gigapixel Whole Slide Images. However, current computational approaches are constrained by fixed-resolution processing mechanisms and inefficient feature aggregation, which inevitably lead to either severe information loss or high feature redundancy. To address these challenges, we propose Hepato-LLaVA, a specialized Multi-modal Large Language Model designed for fine-grained hepatocellular pathology analysis. We introduce a novel Sparse Topo-Pack Attention mechanism that explicitly models 2D tissue topology. This mechanism effectively aggregates local diagnostic evidence into semantic summary tokens while preserving global context. Furthermore, to overcome the lack of multi-scale data, we present HepatoPathoVQA, a clinically grounded dataset comprising 33K hierarchically structured question-answer pairs validated by expert pathologists. Our experiments demonstrate that Hepato-LLaVA achieves state-of-the-art performance on HCC diagnosis and captioning tasks, significantly outperforming existing methods. Our code and implementation details are available at https://pris-cv.github.io/Hepto-LLaVA/.
Single-View Shape Completion for Robotic Grasping in Clutter
Dec 18, 2025



In vision-based robot manipulation, a single camera view can only capture one side of objects of interest, with additional occlusions in cluttered scenes further restricting visibility. As a result, the observed geometry is incomplete, and grasp estimation algorithms perform suboptimally. To address this limitation, we leverage diffusion models to perform category-level 3D shape completion from partial depth observations obtained from a single view, reconstructing complete object geometries to provide richer context for grasp planning. Our method focuses on common household items with diverse geometries, generating full 3D shapes that serve as input to downstream grasp inference networks. Unlike prior work, which primarily considers isolated objects or minimal clutter, we evaluate shape completion and grasping in realistic clutter scenarios with household objects. In preliminary evaluations on a cluttered scene, our approach consistently results in better grasp success rates than a naive baseline without shape completion by 23% and over a recent state of the art shape completion approach by 19%. Our code is available at https://amm.aass.oru.se/shape-completion-grasping/.
Statistically Assuring Safety of Control Systems using Ensembles of Safety Filters and Conformal Prediction
Nov 11, 2025Safety assurance is a fundamental requirement for deploying learning-enabled autonomous systems. Hamilton-Jacobi (HJ) reachability analysis is a fundamental method for formally verifying safety and generating safe controllers. However, computing the HJ value function that characterizes the backward reachable set (BRS) of a set of user-defined failure states is computationally expensive, especially for high-dimensional systems, motivating the use of reinforcement learning approaches to approximate the value function. Unfortunately, a learned value function and its corresponding safe policy are not guaranteed to be correct. The learned value function evaluated at a given state may not be equal to the actual safety return achieved by following the learned safe policy. To address this challenge, we introduce a conformal prediction-based (CP) framework that bounds such uncertainty. We leverage CP to provide probabilistic safety guarantees when using learned HJ value functions and policies to prevent control systems from reaching failure states. Specifically, we use CP to calibrate the switching between the unsafe nominal controller and the learned HJ-based safe policy and to derive safety guarantees under this switched policy. We also investigate using an ensemble of independently trained HJ value functions as a safety filter and compare this ensemble approach to using individual value functions alone.
Can Context Bridge the Reality Gap? Sim-to-Real Transfer of Context-Aware Policies
Nov 06, 2025Sim-to-real transfer remains a major challenge in reinforcement learning (RL) for robotics, as policies trained in simulation often fail to generalize to the real world due to discrepancies in environment dynamics. Domain Randomization (DR) mitigates this issue by exposing the policy to a wide range of randomized dynamics during training, yet leading to a reduction in performance. While standard approaches typically train policies agnostic to these variations, we investigate whether sim-to-real transfer can be improved by conditioning the policy on an estimate of the dynamics parameters -- referred to as context. To this end, we integrate a context estimation module into a DR-based RL framework and systematically compare SOTA supervision strategies. We evaluate the resulting context-aware policies in both a canonical control benchmark and a real-world pushing task using a Franka Emika Panda robot. Results show that context-aware policies outperform the context-agnostic baseline across all settings, although the best supervision strategy depends on the task.
Designing Latent Safety Filters using Pre-Trained Vision Models
Sep 18, 2025Ensuring safety of vision-based control systems remains a major challenge hindering their deployment in critical settings. Safety filters have gained increased interest as effective tools for ensuring the safety of classical control systems, but their applications in vision-based control settings have so far been limited. Pre-trained vision models (PVRs) have been shown to be effective perception backbones for control in various robotics domains. In this paper, we are interested in examining their effectiveness when used for designing vision-based safety filters. We use them as backbones for classifiers defining failure sets, for Hamilton-Jacobi (HJ) reachability-based safety filters, and for latent world models. We discuss the trade-offs between training from scratch, fine-tuning, and freezing the PVRs when training the models they are backbones for. We also evaluate whether one of the PVRs is superior across all tasks, evaluate whether learned world models or Q-functions are better for switching decisions to safe policies, and discuss practical considerations for deploying these PVRs on resource-constrained devices.
Unsupervised Multi-Attention Meta Transformer for Rotating Machinery Fault Diagnosis
Sep 11, 2025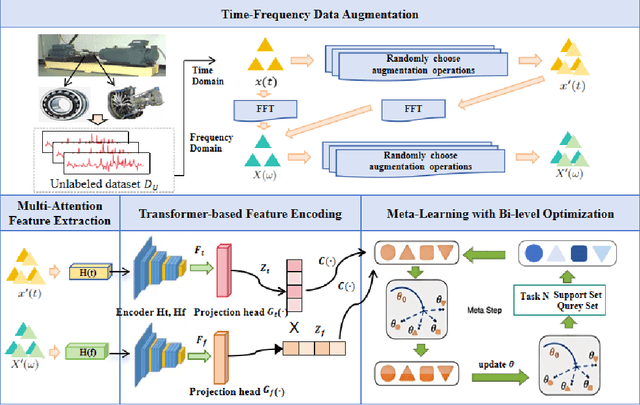

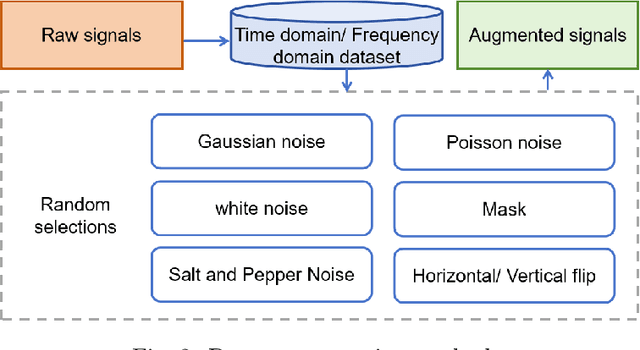
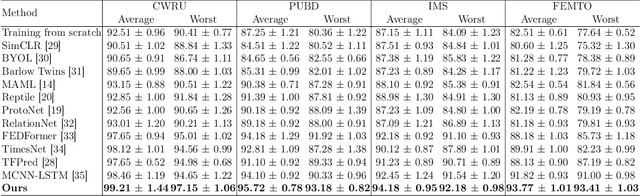
The intelligent fault diagnosis of rotating mechanical equipment usually requires a large amount of labeled sample data. However, in practical industrial applications, acquiring enough data is both challenging and expensive in terms of time and cost. Moreover, different types of rotating mechanical equipment with different unique mechanical properties, require separate training of diagnostic models for each case. To address the challenges of limited fault samples and the lack of generalizability in prediction models for practical engineering applications, we propose a Multi-Attention Meta Transformer method for few-shot unsupervised rotating machinery fault diagnosis (MMT-FD). This framework extracts potential fault representations from unlabeled data and demonstrates strong generalization capabilities, making it suitable for diagnosing faults across various types of mechanical equipment. The MMT-FD framework integrates a time-frequency domain encoder and a meta-learning generalization model. The time-frequency domain encoder predicts status representations generated through random augmentations in the time-frequency domain. These enhanced data are then fed into a meta-learning network for classification and generalization training, followed by fine-tuning using a limited amount of labeled data. The model is iteratively optimized using a small number of contrastive learning iterations, resulting in high efficiency. To validate the framework, we conducted experiments on a bearing fault dataset and rotor test bench data. The results demonstrate that the MMT-FD model achieves 99\% fault diagnosis accuracy with only 1\% of labeled sample data, exhibiting robust generalization capabilities.
MedReasoner: Reinforcement Learning Drives Reasoning Grounding from Clinical Thought to Pixel-Level Precision
Aug 11, 2025Accurately grounding regions of interest (ROIs) is critical for diagnosis and treatment planning in medical imaging. While multimodal large language models (MLLMs) combine visual perception with natural language, current medical-grounding pipelines still rely on supervised fine-tuning with explicit spatial hints, making them ill-equipped to handle the implicit queries common in clinical practice. This work makes three core contributions. We first define Unified Medical Reasoning Grounding (UMRG), a novel vision-language task that demands clinical reasoning and pixel-level grounding. Second, we release U-MRG-14K, a dataset of 14K samples featuring pixel-level masks alongside implicit clinical queries and reasoning traces, spanning 10 modalities, 15 super-categories, and 108 specific categories. Finally, we introduce MedReasoner, a modular framework that distinctly separates reasoning from segmentation: an MLLM reasoner is optimized with reinforcement learning, while a frozen segmentation expert converts spatial prompts into masks, with alignment achieved through format and accuracy rewards. MedReasoner achieves state-of-the-art performance on U-MRG-14K and demonstrates strong generalization to unseen clinical queries, underscoring the significant promise of reinforcement learning for interpretable medical grounding.
The First WARA Robotics Mobile Manipulation Challenge -- Lessons Learned
May 11, 2025The first WARA Robotics Mobile Manipulation Challenge, held in December 2024 at ABB Corporate Research in V\"aster{\aa}s, Sweden, addressed the automation of task-intensive and repetitive manual labor in laboratory environments - specifically the transport and cleaning of glassware. Designed in collaboration with AstraZeneca, the challenge invited academic teams to develop autonomous robotic systems capable of navigating human-populated lab spaces and performing complex manipulation tasks, such as loading items into industrial dishwashers. This paper presents an overview of the challenge setup, its industrial motivation, and the four distinct approaches proposed by the participating teams. We summarize lessons learned from this edition and propose improvements in design to enable a more effective second iteration to take place in 2025. The initiative bridges an important gap in effective academia-industry collaboration within the domain of autonomous mobile manipulation systems by promoting the development and deployment of applied robotic solutions in real-world laboratory contexts.