 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePandora's Box or Aladdin's Lamp: A Comprehensive Analysis Revealing the Role of RAG Noise in Large Language Models
Aug 24, 2024



Retrieval-Augmented Generation (RAG) has emerged as a crucial method for addressing hallucinations in large language models (LLMs). While recent research has extended RAG models to complex noisy scenarios, these explorations often confine themselves to limited noise types and presuppose that noise is inherently detrimental to LLMs, potentially deviating from real-world retrieval environments and restricting practical applicability. In this paper, we define seven distinct noise types from a linguistic perspective and establish a Noise RAG Benchmark (NoiserBench), a comprehensive evaluation framework encompassing multiple datasets and reasoning tasks. Through empirical evaluation of eight representative LLMs with diverse architectures and scales, we reveal that these noises can be further categorized into two practical groups: noise that is beneficial to LLMs (aka beneficial noise) and noise that is harmful to LLMs (aka harmful noise). While harmful noise generally impairs performance, beneficial noise may enhance several aspects of model capabilities and overall performance. Our analysis offers insights for developing more robust, adaptable RAG solutions and mitigating hallucinations across diverse retrieval scenarios.
What to Remember: Self-Adaptive Continual Learning for Audio Deepfake Detection
Dec 15, 2023The rapid evolution of speech synthesis and voice conversion has raised substantial concerns due to the potential misuse of such technology, prompting a pressing need for effective audio deepfake detection mechanisms. Existing detection models have shown remarkable success in discriminating known deepfake audio, but struggle when encountering new attack types. To address this challenge, one of the emergent effective approaches is continual learning. In this paper, we propose a continual learning approach called Radian Weight Modification (RWM) for audio deepfake detection. The fundamental concept underlying RWM involves categorizing all classes into two groups: those with compact feature distributions across tasks, such as genuine audio, and those with more spread-out distributions, like various types of fake audio. These distinctions are quantified by means of the in-class cosine distance, which subsequently serves as the basis for RWM to introduce a trainable gradient modification direction for distinct data types. Experimental evaluations against mainstream continual learning methods reveal the superiority of RWM in terms of knowledge acquisition and mitigating forgetting in audio deepfake detection. Furthermore, RWM's applicability extends beyond audio deepfake detection, demonstrating its potential significance in diverse machine learning domains such as image recognition.
Do You Remember? Overcoming Catastrophic Forgetting for Fake Audio Detection
Aug 07, 2023



Current fake audio detection algorithms have achieved promising performances on most datasets. However, their performance may be significantly degraded when dealing with audio of a different dataset. The orthogonal weight modification to overcome catastrophic forgetting does not consider the similarity of genuine audio across different datasets. To overcome this limitation, we propose a continual learning algorithm for fake audio detection to overcome catastrophic forgetting, called Regularized Adaptive Weight Modification (RAWM). When fine-tuning a detection network, our approach adaptively computes the direction of weight modification according to the ratio of genuine utterances and fake utterances. The adaptive modification direction ensures the network can effectively detect fake audio on the new dataset while preserving its knowledge of old model, thus mitigating catastrophic forgetting. In addition, genuine audio collected from quite different acoustic conditions may skew their feature distribution, so we introduce a regularization constraint to force the network to remember the old distribution in this regard. Our method can easily be generalized to related fields, like speech emotion recognition. We also evaluate our approach across multiple datasets and obtain a significant performance improvement on cross-dataset experiments.
TO-Rawnet: Improving RawNet with TCN and Orthogonal Regularization for Fake Audio Detection
May 23, 2023



Current fake audio detection relies on hand-crafted features, which lose information during extraction. To overcome this, recent studies use direct feature extraction from raw audio signals. For example, RawNet is one of the representative works in end-to-end fake audio detection. However, existing work on RawNet does not optimize the parameters of the Sinc-conv during training, which limited its performance. In this paper, we propose to incorporate orthogonal convolution into RawNet, which reduces the correlation between filters when optimizing the parameters of Sinc-conv, thus improving discriminability. Additionally, we introduce temporal convolutional networks (TCN) to capture long-term dependencies in speech signals. Experiments on the ASVspoof 2019 show that the Our TO-RawNet system can relatively reduce EER by 66.09\% on logical access scenario compared with the RawNet, demonstrating its effectiveness in detecting fake audio attacks.
Detection of Cross-Dataset Fake Audio Based on Prosodic and Pronunciation Features
May 23, 2023



Existing fake audio detection systems perform well in in-domain testing, but still face many challenges in out-of-domain testing. This is due to the mismatch between the training and test data, as well as the poor generalizability of features extracted from limited views. To address this, we propose multi-view features for fake audio detection, which aim to capture more generalized features from prosodic, pronunciation, and wav2vec dimensions. Specifically, the phoneme duration features are extracted from a pre-trained model based on a large amount of speech data. For the pronunciation features, a Conformer-based phoneme recognition model is first trained, keeping the acoustic encoder part as a deeply embedded feature extractor. Furthermore, the prosodic and pronunciation features are fused with wav2vec features based on an attention mechanism to improve the generalization of fake audio detection models. Results show that the proposed approach achieves significant performance gains in several cross-dataset experiments.
Awesome-META+: Meta-Learning Research and Learning Platform
Apr 24, 2023

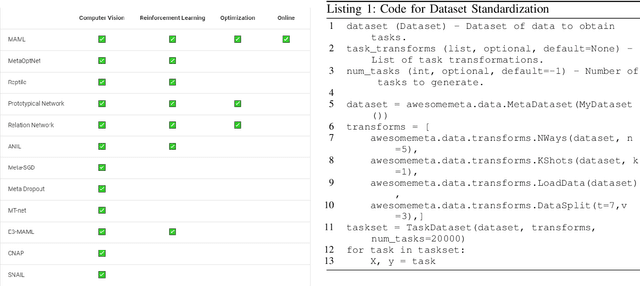
Artificial intelligence technology has already had a profound impact in various fields such as economy, industry, and education, but still limited. Meta-learning, also known as "learning to learn", provides an opportunity for general artificial intelligence, which can break through the current AI bottleneck. However, meta learning started late and there are fewer projects compare with CV, NLP etc. Each deployment requires a lot of experience to configure the environment, debug code or even rewrite, and the frameworks are isolated. Moreover, there are currently few platforms that focus exclusively on meta-learning, or provide learning materials for novices, for which the threshold is relatively high. Based on this, Awesome-META+, a meta-learning framework integration and learning platform is proposed to solve the above problems and provide a complete and reliable meta-learning framework application and learning platform. The project aims to promote the development of meta-learning and the expansion of the community, including but not limited to the following functions: 1) Complete and reliable meta-learning framework, which can adapt to multi-field tasks such as target detection, image classification, and reinforcement learning. 2) Convenient and simple model deployment scheme which provide convenient meta-learning transfer methods and usage methods to lower the threshold of meta-learning and improve efficiency. 3) Comprehensive researches for learning. 4) Objective and credible performance analysis and thinking.