 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024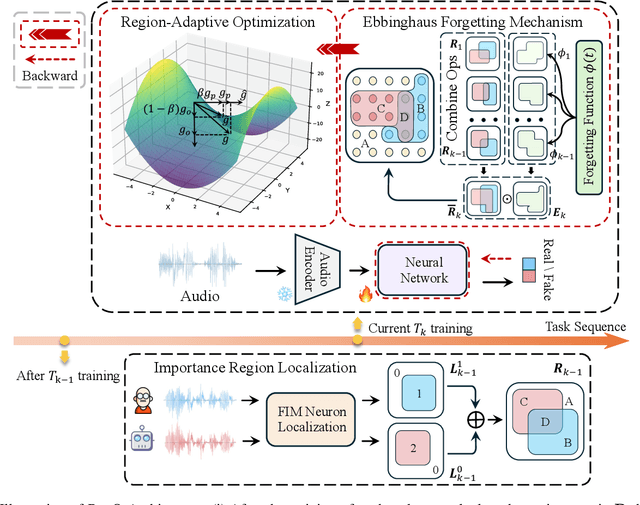
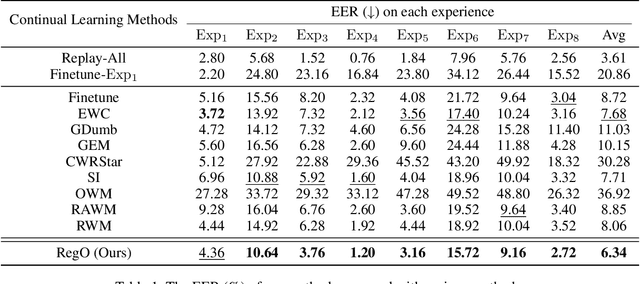
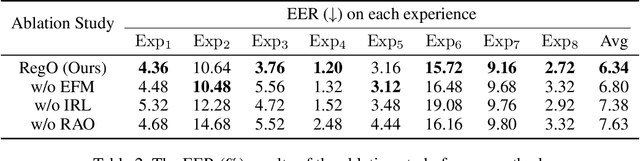
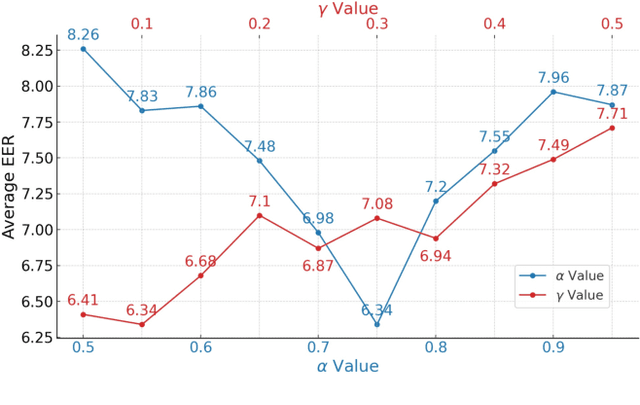
Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
An Unsupervised Domain Adaptation Method for Locating Manipulated Region in partially fake Audio
Jul 11, 2024
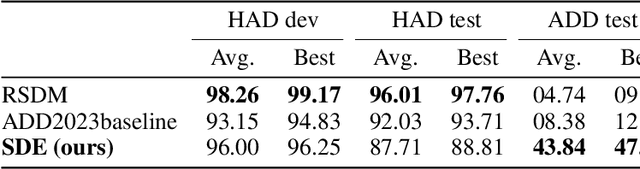
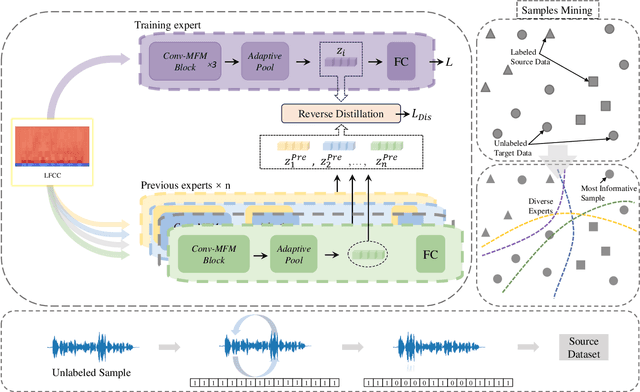
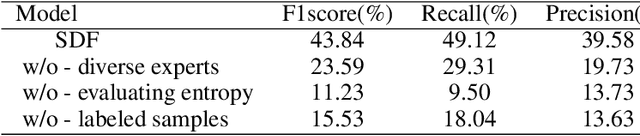
When the task of locating manipulation regions in partially-fake audio (PFA) involves cross-domain datasets, the performance of deep learning models drops significantly due to the shift between the source and target domains. To address this issue, existing approaches often employ data augmentation before training. However, they overlook the characteristics in target domain that are absent in source domain. Inspired by the mixture-of-experts model, we propose an unsupervised method named Samples mining with Diversity and Entropy (SDE). Our method first learns from a collection of diverse experts that achieve great performance from different perspectives in the source domain, but with ambiguity on target samples. We leverage these diverse experts to select the most informative samples by calculating their entropy. Furthermore, we introduced a label generation method tailored for these selected samples that are incorporated in the training process in source domain integrating the target domain information. We applied our method to a cross-domain partially fake audio detection dataset, ADD2023Track2. By introducing 10% of unknown samples from the target domain, we achieved an F1 score of 43.84%, which represents a relative increase of 77.2% compared to the second-best method.
RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection
Jun 10, 2024


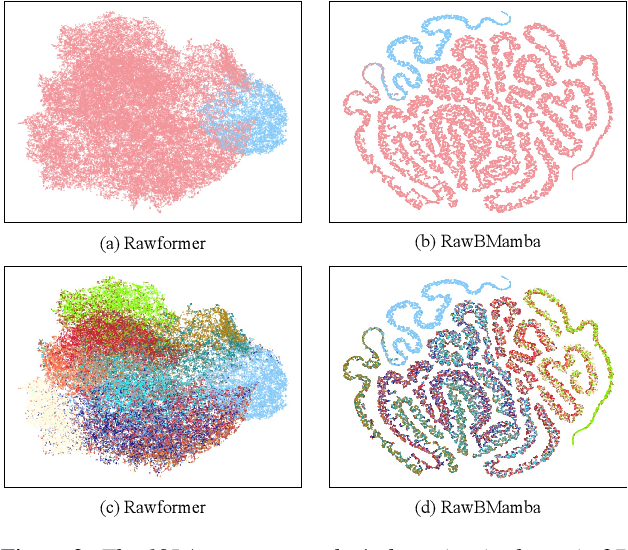
Fake artefacts for discriminating between bonafide and fake audio can exist in both short- and long-range segments. Therefore, combining local and global feature information can effectively discriminate between bonafide and fake audio. This paper proposes an end-to-end bidirectional state space model, named RawBMamba, to capture both short- and long-range discriminative information for audio deepfake detection. Specifically, we use sinc Layer and multiple convolutional layers to capture short-range features, and then design a bidirectional Mamba to address Mamba's unidirectional modelling problem and further capture long-range feature information. Moreover, we develop a bidirectional fusion module to integrate embeddings, enhancing audio context representation and combining short- and long-range information. The results show that our proposed RawBMamba achieves a 34.1\% improvement over Rawformer on ASVspoof2021 LA dataset, and demonstrates competitive performance on other datasets.
What to Remember: Self-Adaptive Continual Learning for Audio Deepfake Detection
Dec 15, 2023The rapid evolution of speech synthesis and voice conversion has raised substantial concerns due to the potential misuse of such technology, prompting a pressing need for effective audio deepfake detection mechanisms. Existing detection models have shown remarkable success in discriminating known deepfake audio, but struggle when encountering new attack types. To address this challenge, one of the emergent effective approaches is continual learning. In this paper, we propose a continual learning approach called Radian Weight Modification (RWM) for audio deepfake detection. The fundamental concept underlying RWM involves categorizing all classes into two groups: those with compact feature distributions across tasks, such as genuine audio, and those with more spread-out distributions, like various types of fake audio. These distinctions are quantified by means of the in-class cosine distance, which subsequently serves as the basis for RWM to introduce a trainable gradient modification direction for distinct data types. Experimental evaluations against mainstream continual learning methods reveal the superiority of RWM in terms of knowledge acquisition and mitigating forgetting in audio deepfake detection. Furthermore, RWM's applicability extends beyond audio deepfake detection, demonstrating its potential significance in diverse machine learning domains such as image recognition.