 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unsupervised Domain Adaptation Method for Locating Manipulated Region in partially fake Audio
Paper and Code
Jul 11, 2024
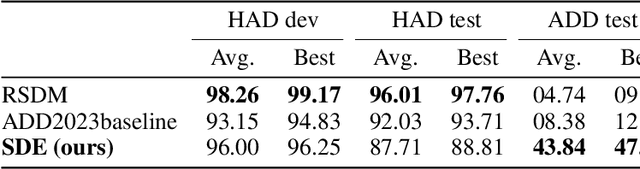
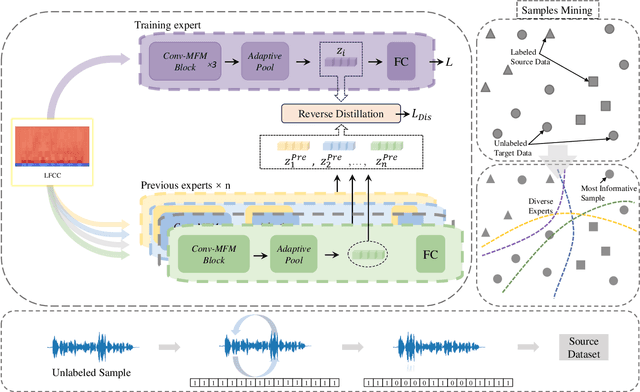
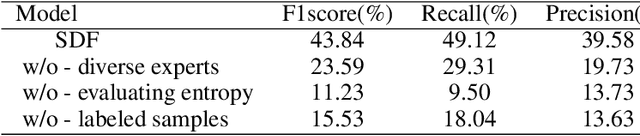
When the task of locating manipulation regions in partially-fake audio (PFA) involves cross-domain datasets, the performance of deep learning models drops significantly due to the shift between the source and target domains. To address this issue, existing approaches often employ data augmentation before training. However, they overlook the characteristics in target domain that are absent in source domain. Inspired by the mixture-of-experts model, we propose an unsupervised method named Samples mining with Diversity and Entropy (SDE). Our method first learns from a collection of diverse experts that achieve great performance from different perspectives in the source domain, but with ambiguity on target samples. We leverage these diverse experts to select the most informative samples by calculating their entropy. Furthermore, we introduced a label generation method tailored for these selected samples that are incorporated in the training process in source domain integrating the target domain information. We applied our method to a cross-domain partially fake audio detection dataset, ADD2023Track2. By introducing 10% of unknown samples from the target domain, we achieved an F1 score of 43.84%, which represents a relative increase of 77.2% compared to the second-best method.