 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-mix Knowledge Distillation for Fake Speech Detection
Jun 14, 2024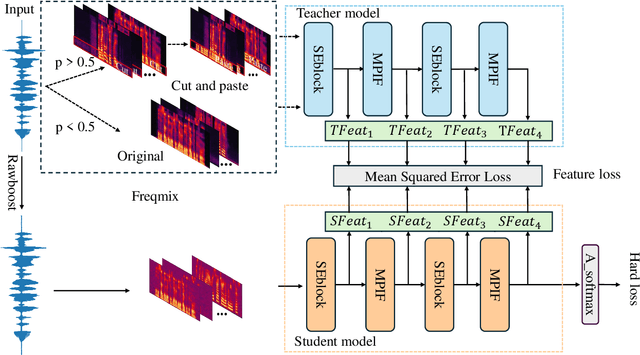
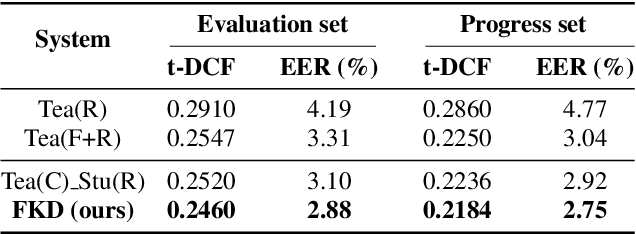
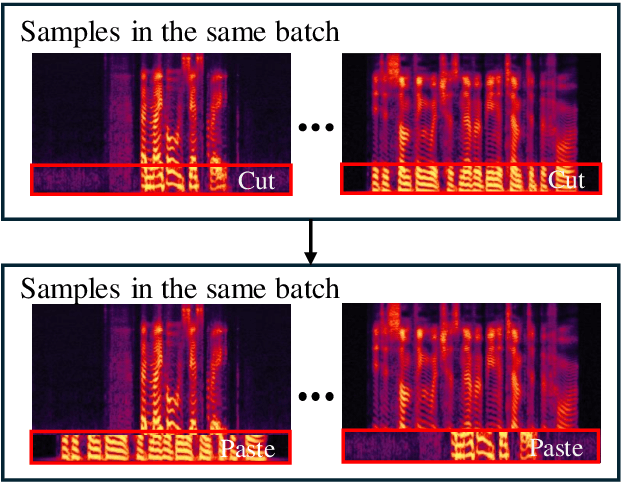
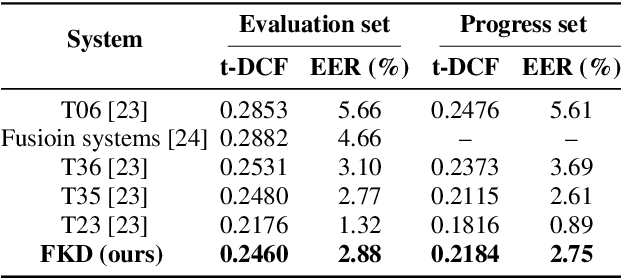
In the telephony scenarios, the fake speech detection (FSD) task to combat speech spoofing attacks is challenging. Data augmentation (DA) methods are considered effective means to address the FSD task in telephony scenarios, typically divided into time domain and frequency domain stages. While each has its advantages, both can result in information loss. To tackle this issue, we propose a novel DA method, Frequency-mix (Freqmix), and introduce the Freqmix knowledge distillation (FKD) to enhance model information extraction and generalization abilities. Specifically, we use Freqmix-enhanced data as input for the teacher model, while the student model's input undergoes time-domain DA method. We use a multi-level feature distillation approach to restore information and improve the model's generalization capabilities. Our approach achieves state-of-the-art results on ASVspoof 2021 LA dataset, showing a 31\% improvement over baseline and performs competitively on ASVspoof 2021 DF dataset.
RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection
Jun 10, 2024


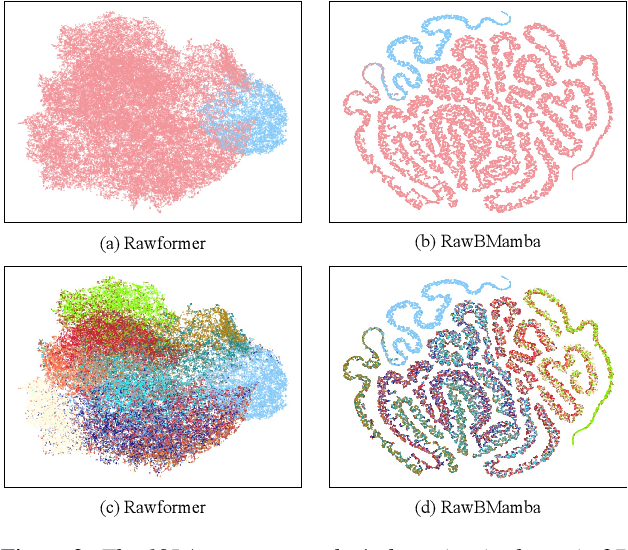
Fake artefacts for discriminating between bonafide and fake audio can exist in both short- and long-range segments. Therefore, combining local and global feature information can effectively discriminate between bonafide and fake audio. This paper proposes an end-to-end bidirectional state space model, named RawBMamba, to capture both short- and long-range discriminative information for audio deepfake detection. Specifically, we use sinc Layer and multiple convolutional layers to capture short-range features, and then design a bidirectional Mamba to address Mamba's unidirectional modelling problem and further capture long-range feature information. Moreover, we develop a bidirectional fusion module to integrate embeddings, enhancing audio context representation and combining short- and long-range information. The results show that our proposed RawBMamba achieves a 34.1\% improvement over Rawformer on ASVspoof2021 LA dataset, and demonstrates competitive performance on other datasets.
Multi-perspective Information Fusion Res2Net with RandomSpecmix for Fake Speech Detection
Jun 27, 2023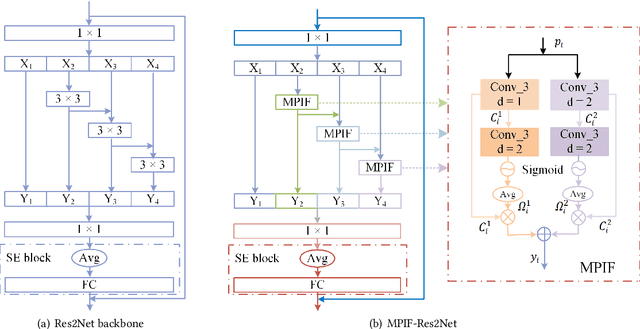

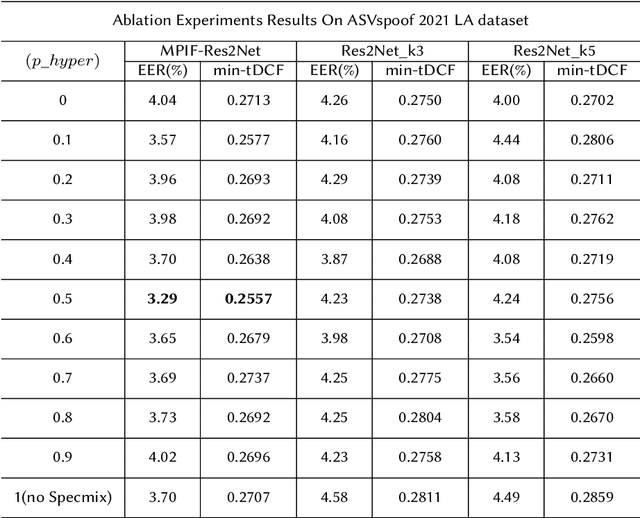
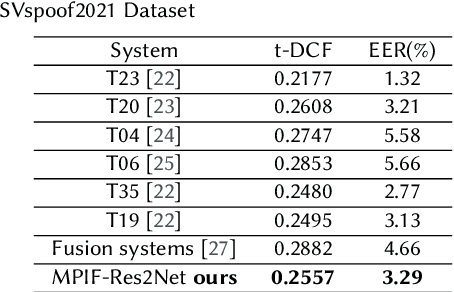
In this paper, we propose the multi-perspective information fusion (MPIF) Res2Net with random Specmix for fake speech detection (FSD). The main purpose of this system is to improve the model's ability to learn precise forgery information for FSD task in low-quality scenarios. The task of random Specmix, a data augmentation, is to improve the generalization ability of the model and enhance the model's ability to locate discriminative information. Specmix cuts and pastes the frequency dimension information of the spectrogram in the same batch of samples without introducing other data, which helps the model to locate the really useful information. At the same time, we randomly select samples for augmentation to reduce the impact of data augmentation directly changing all the data. Once the purpose of helping the model to locate information is achieved, it is also important to reduce unnecessary information. The role of MPIF-Res2Net is to reduce redundant interference information. Deceptive information from a single perspective is always similar, so the model learning this similar information will produce redundant spoofing clues and interfere with truly discriminative information. The proposed MPIF-Res2Net fuses information from different perspectives, making the information learned by the model more diverse, thereby reducing the redundancy caused by similar information and avoiding interference with the learning of discriminative information. The results on the ASVspoof 2021 LA dataset demonstrate the effectiveness of our proposed method, achieving EER and min-tDCF of 3.29% and 0.2557, respectively.