 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Latent Graph Representations of Surgical Scenes for Zero-Shot Domain Transfer
Mar 11, 2024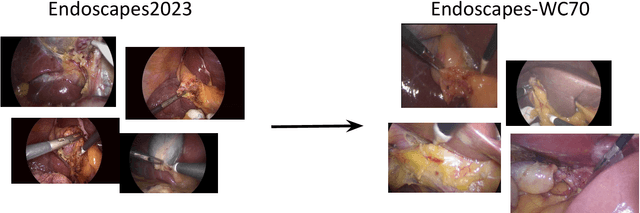
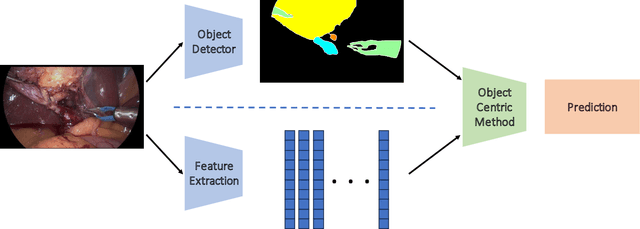

Purpose: Advances in deep learning have resulted in effective models for surgical video analysis; however, these models often fail to generalize across medical centers due to domain shift caused by variations in surgical workflow, camera setups, and patient demographics. Recently, object-centric learning has emerged as a promising approach for improved surgical scene understanding, capturing and disentangling visual and semantic properties of surgical tools and anatomy to improve downstream task performance. In this work, we conduct a multi-centric performance benchmark of object-centric approaches, focusing on Critical View of Safety assessment in laparoscopic cholecystectomy, then propose an improved approach for unseen domain generalization. Methods: We evaluate four object-centric approaches for domain generalization, establishing baseline performance. Next, leveraging the disentangled nature of object-centric representations, we dissect one of these methods through a series of ablations (e.g. ignoring either visual or semantic features for downstream classification). Finally, based on the results of these ablations, we develop an optimized method specifically tailored for domain generalization, LG-DG, that includes a novel disentanglement loss function. Results: Our optimized approach, LG-DG, achieves an improvement of 9.28% over the best baseline approach. More broadly, we show that object-centric approaches are highly effective for domain generalization thanks to their modular approach to representation learning. Conclusion: We investigate the use of object-centric methods for unseen domain generalization, identify method-agnostic factors critical for performance, and present an optimized approach that substantially outperforms existing methods.
The Endoscapes Dataset for Surgical Scene Segmentation, Object Detection, and Critical View of Safety Assessment: Official Splits and Benchmark
Dec 19, 2023



This technical report provides a detailed overview of Endoscapes, a dataset of laparoscopic cholecystectomy (LC) videos with highly intricate annotations targeted at automated assessment of the Critical View of Safety (CVS). Endoscapes comprises 201 LC videos with frames annotated sparsely but regularly with segmentation masks, bounding boxes, and CVS assessment by three different clinical experts. Altogether, there are 11090 frames annotated with CVS and 1933 frames annotated with tool and anatomy bounding boxes from the 201 videos, as well as an additional 422 frames from 50 of the 201 videos annotated with tool and anatomy segmentation masks. In this report, we provide detailed dataset statistics (size, class distribution, dataset splits, etc.) and a comprehensive performance benchmark for instance segmentation, object detection, and CVS prediction. The dataset and model checkpoints are publically available at https://github.com/CAMMA-public/Endoscapes.
Encoding Surgical Videos as Latent Spatiotemporal Graphs for Object and Anatomy-Driven Reasoning
Dec 11, 2023Recently, spatiotemporal graphs have emerged as a concise and elegant manner of representing video clips in an object-centric fashion, and have shown to be useful for downstream tasks such as action recognition. In this work, we investigate the use of latent spatiotemporal graphs to represent a surgical video in terms of the constituent anatomical structures and tools and their evolving properties over time. To build the graphs, we first predict frame-wise graphs using a pre-trained model, then add temporal edges between nodes based on spatial coherence and visual and semantic similarity. Unlike previous approaches, we incorporate long-term temporal edges in our graphs to better model the evolution of the surgical scene and increase robustness to temporary occlusions. We also introduce a novel graph-editing module that incorporates prior knowledge and temporal coherence to correct errors in the graph, enabling improved downstream task performance. Using our graph representations, we evaluate two downstream tasks, critical view of safety prediction and surgical phase recognition, obtaining strong results that demonstrate the quality and flexibility of the learned representations. Code is available at github.com/CAMMA-public/SurgLatentGraph.
Jumpstarting Surgical Computer Vision
Dec 10, 2023



Purpose: General consensus amongst researchers and industry points to a lack of large, representative annotated datasets as the biggest obstacle to progress in the field of surgical data science. Self-supervised learning represents a solution to part of this problem, removing the reliance on annotations. However, the robustness of current self-supervised learning methods to domain shifts remains unclear, limiting our understanding of its utility for leveraging diverse sources of surgical data. Methods: In this work, we employ self-supervised learning to flexibly leverage diverse surgical datasets, thereby learning taskagnostic representations that can be used for various surgical downstream tasks. Based on this approach, to elucidate the impact of pre-training on downstream task performance, we explore 22 different pre-training dataset combinations by modulating three variables: source hospital, type of surgical procedure, and pre-training scale (number of videos). We then finetune the resulting model initializations on three diverse downstream tasks: namely, phase recognition and critical view of safety in laparoscopic cholecystectomy and phase recognition in laparoscopic hysterectomy. Results: Controlled experimentation highlights sizable boosts in performance across various tasks, datasets, and labeling budgets. However, this performance is intricately linked to the composition of the pre-training dataset, robustly proven through several study stages. Conclusion: The composition of pre-training datasets can severely affect the effectiveness of SSL methods for various downstream tasks and should critically inform future data collection efforts to scale the application of SSL methodologies. Keywords: Self-Supervised Learning, Transfer Learning, Surgical Computer Vision, Endoscopic Videos, Critical View of Safety, Phase Recognition
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023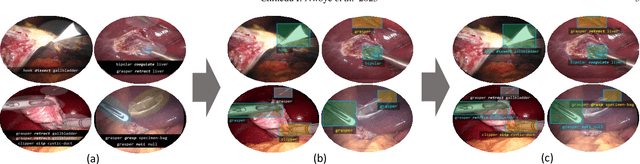
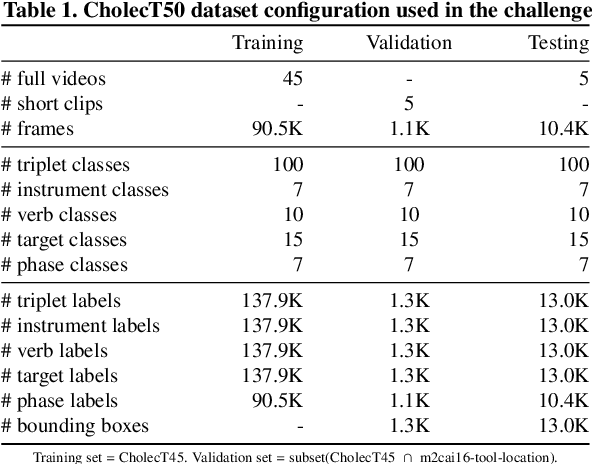
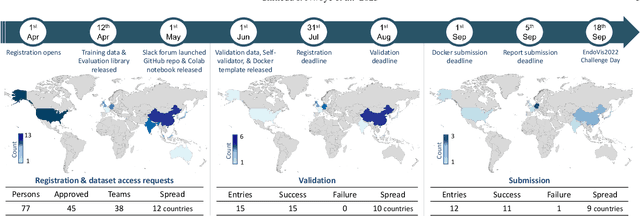
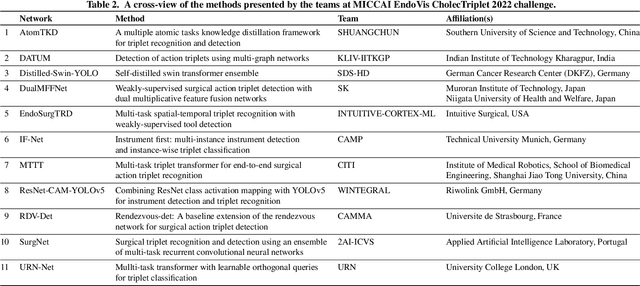
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Real-Time Artificial Intelligence Assistance for Safe Laparoscopic Cholecystectomy: Early-Stage Clinical Evaluation
Dec 13, 2022
Artificial intelligence is set to be deployed in operating rooms to improve surgical care. This early-stage clinical evaluation shows the feasibility of concurrently attaining real-time, high-quality predictions from several deep neural networks for endoscopic video analysis deployed for assistance during three laparoscopic cholecystectomies.
Latent Graph Representations for Critical View of Safety Assessment
Dec 08, 2022



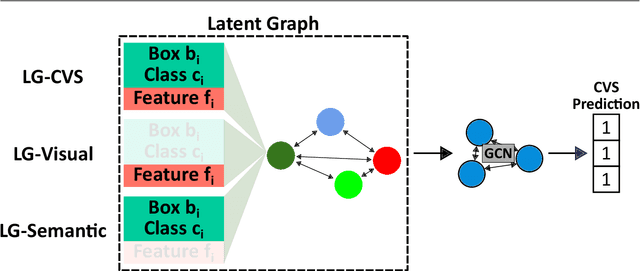
Assessing the critical view of safety in laparoscopic cholecystectomy requires accurate identification and localization of key anatomical structures, reasoning about their geometric relationships to one another, and determining the quality of their exposure. In this work, we propose to capture each of these aspects by modeling the surgical scene with a disentangled latent scene graph representation, which we can then process using a graph neural network. Unlike previous approaches using graph representations, we explicitly encode in our graphs semantic information such as object locations and shapes, class probabilities and visual features. We also incorporate an auxiliary image reconstruction objective to help train the latent graph representations. We demonstrate the value of these components through comprehensive ablation studies and achieve state-of-the-art results for critical view of safety prediction across multiple experimental settings.
Dissecting Self-Supervised Learning Methods for Surgical Computer Vision
Jul 01, 2022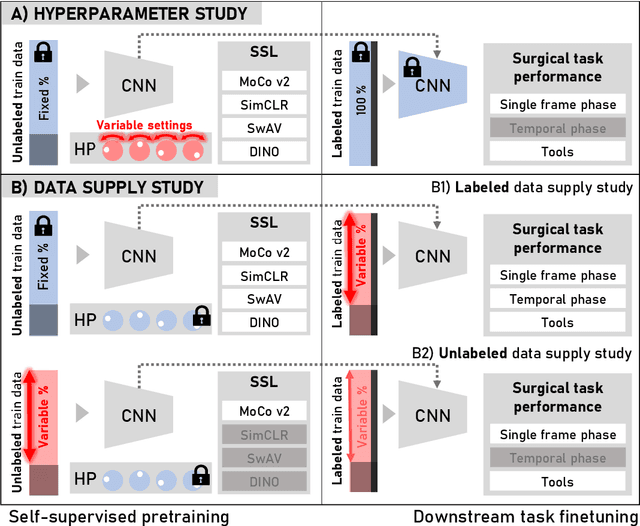
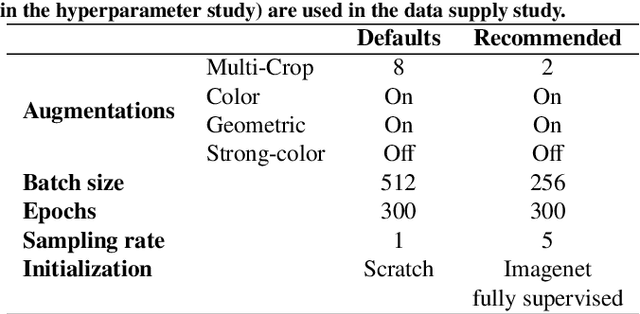
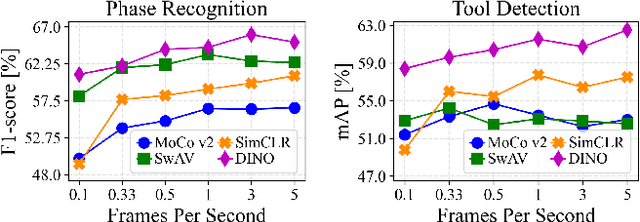
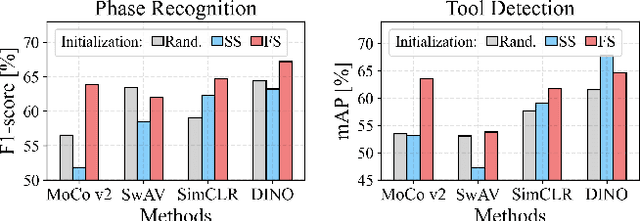
The field of surgical computer vision has undergone considerable breakthroughs in recent years with the rising popularity of deep neural network-based methods. However, standard fully-supervised approaches for training such models require vast amounts of annotated data, imposing a prohibitively high cost; especially in the clinical domain. Self-Supervised Learning (SSL) methods, which have begun to gain traction in the general computer vision community, represent a potential solution to these annotation costs, allowing to learn useful representations from only unlabeled data. Still, the effectiveness of SSL methods in more complex and impactful domains, such as medicine and surgery, remains limited and unexplored. In this work, we address this critical need by investigating four state-of-the-art SSL methods (MoCo v2, SimCLR, DINO, SwAV) in the context of surgical computer vision. We present an extensive analysis of the performance of these methods on the Cholec80 dataset for two fundamental and popular tasks in surgical context understanding, phase recognition and tool presence detection. We examine their parameterization, then their behavior with respect to training data quantities in semi-supervised settings. Correct transfer of these methods to surgery, as described and conducted in this work, leads to substantial performance gains over generic uses of SSL - up to 7% on phase recognition and 20% on tool presence detection - as well as state-of-the-art semi-supervised phase recognition approaches by up to 14%. The code will be made available at https://github.com/CAMMA-public/SelfSupSurg.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022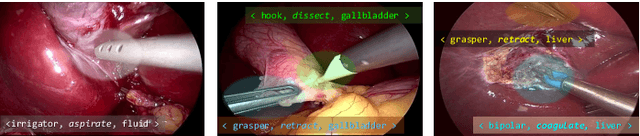

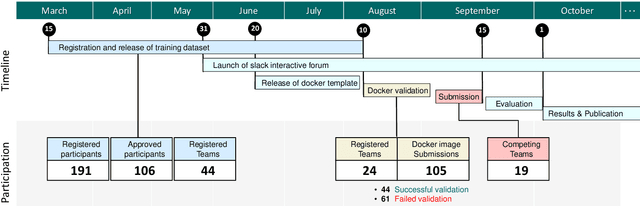
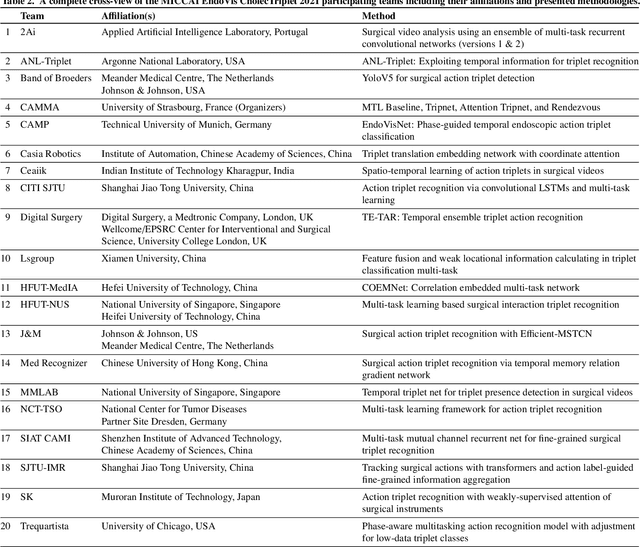
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.