 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgTEMP: Temporal-Aware Surgical Video Question Answering with Text-guided Visual Memory for Laparoscopic Cholecystectomy
Apr 01, 2026Surgical procedures are inherently complex and risky, requiring extensive expertise and constant focus to well navigate evolving intraoperative scenes. Computer-assisted systems such as surgical visual question answering (VQA) offer promises for education and intraoperative support. Current surgical VQA research largely focuses on static frame analysis, overlooking rich temporal semantics. Surgical video question answering is further challenged by low visual contrast, its highly knowledge-driven nature, diverse analytical needs spanning scattered temporal windows, and the hierarchy from basic perception to high-level intraoperative assessment. To address these challenges, we propose SurgTEMP, a multimodal LLM framework featuring (i) a query-guided token selection module that builds hierarchical visual memory (spatial and temporal memory banks) and (ii) a Surgical Competency Progression (SCP) training scheme. Together, these components enable effective modeling of variable-length surgical videos while preserving procedure-relevant cues and temporal coherence, and better support diverse downstream assessment tasks. To support model development, we introduce CholeVidQA-32K, a surgical video question answering dataset comprising 32K open-ended QA pairs and 3,855 video segments (approximately 128 h total) from laparoscopic cholecystectomy. The dataset is organized into a three-level hierarchy -- Perception, Assessment, and Reasoning -- spanning 11 tasks from instrument/action/anatomy perception to Critical View of Safety (CVS), intraoperative difficulty, skill proficiency, and adverse event assessment. In comprehensive evaluations against state-of-the-art open-source multimodal and video LLMs (fine-tuned and zero-shot), SurgTEMP achieves substantial performance improvements, advancing the state of video-based surgical VQA.
CliPPER: Contextual Video-Language Pretraining on Long-form Intraoperative Surgical Procedures for Event Recognition
Mar 25, 2026Video-language foundation models have proven to be highly effective in zero-shot applications across a wide range of tasks. A particularly challenging area is the intraoperative surgical procedure domain, where labeled data is scarce, and precise temporal understanding is often required for complex downstream tasks. To address this challenge, we introduce CliPPER (Contextual Video-Language Pretraining on Long-form Intraoperative Surgical Procedures for Event Recognition), a novel video-language pretraining framework trained on surgical lecture videos. Our method is designed for fine-grained temporal video-text recognition and introduces several novel pretraining strategies to improve multimodal alignment in long-form surgical videos. Specifically, we propose Contextual Video-Text Contrastive Learning (VTC_CTX) and Clip Order Prediction (COP) pretraining objectives, both of which leverage temporal and contextual dependencies to enhance local video understanding. In addition, we incorporate a Cycle-Consistency Alignment over video-text matches within the same surgical video to enforce bidirectional consistency and improve overall representation coherence. Moreover, we introduce a more refined alignment loss, Frame-Text Matching (FTM), to improve the alignment between video frames and text. As a result, our model establishes a new state-of-the-art across multiple public surgical benchmarks, including zero-shot recognition of phases, steps, instruments, and triplets. The source code and pretraining captions can be found at https://github.com/CAMMA-public/CliPPER.
Self-Supervised Uncalibrated Multi-View Video Anonymization in the Operating Room
Feb 02, 2026Privacy preservation is a prerequisite for using video data in Operating Room (OR) research. Effective anonymization relies on the exhaustive localization of every individual; even a single missed detection necessitates extensive manual correction. However, existing approaches face two critical scalability bottlenecks: (1) they usually require manual annotations of each new clinical site for high accuracy; (2) while multi-camera setups have been widely adopted to address single-view ambiguity, camera calibration is typically required whenever cameras are repositioned. To address these problems, we propose a novel self-supervised multi-view video anonymization framework consisting of whole-body person detection and whole-body pose estimation, without annotation or camera calibration. Our core strategy is to enhance the single-view detector by "retrieving" false negatives using temporal and multi-view context, and conducting self-supervised domain adaptation. We first run an off-the-shelf whole-body person detector in each view with a low-score threshold to gather candidate detections. Then, we retrieve the low-score false negatives that exhibit consistency with the high-score detections via tracking and self-supervised uncalibrated multi-view association. These recovered detections serve as pseudo labels to iteratively fine-tune the whole-body detector. Finally, we apply whole-body pose estimation on each detected person, and fine-tune the pose model using its own high-score predictions. Experiments on the 4D-OR dataset of simulated surgeries and our dataset of real surgeries show the effectiveness of our approach achieving over 97% recall. Moreover, we train a real-time whole-body detector using our pseudo labels, achieving comparable performance and highlighting our method's practical applicability. Code is available at https://github.com/CAMMA-public/OR_anonymization.
Artificial Intelligence for the Assessment of Peritoneal Carcinosis during Diagnostic Laparoscopy for Advanced Ovarian Cancer
Dec 16, 2025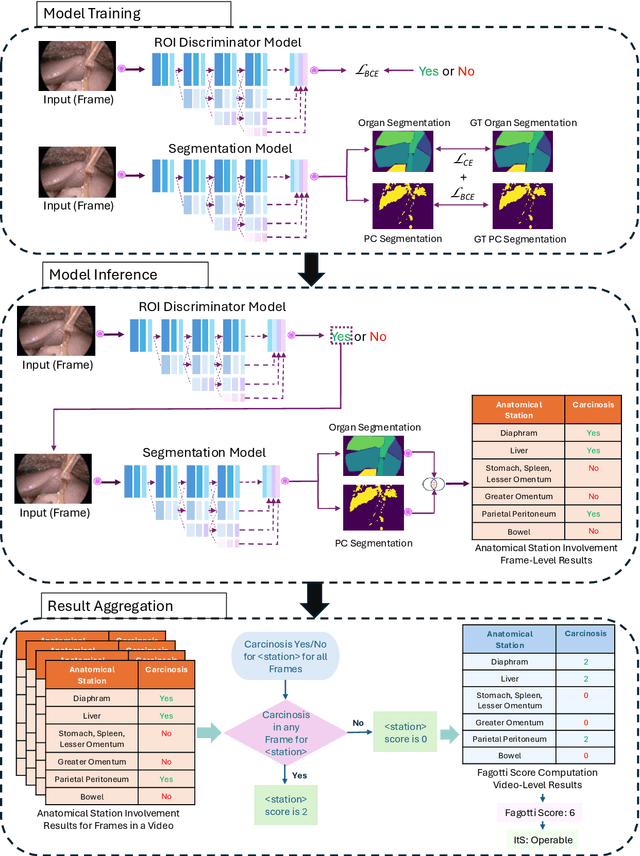
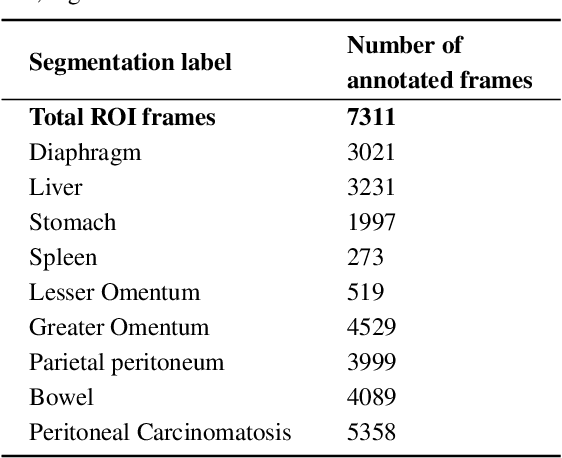


Advanced Ovarian Cancer (AOC) is often diagnosed at an advanced stage with peritoneal carcinosis (PC). Fagotti score (FS) assessment at diagnostic laparoscopy (DL) guides treatment planning by estimating surgical resectability, but its subjective and operator-dependent nature limits reproducibility and widespread use. Videos of patients undergoing DL with concomitant FS assessments at a referral center were retrospectively collected and divided into a development dataset, for data annotation, AI training and evaluation, and an independent test dataset, for internal validation. In the development dataset, FS-relevant frames were manually annotated for anatomical structures and PC. Deep learning models were trained to automatically identify FS-relevant frames, segment structures and PC, and predict video-level FS and indication to surgery (ItS). AI performance was evaluated using Dice score for segmentation, F1-scores for anatomical stations (AS) and ItS prediction, and root mean square error (RMSE) for final FS estimation. In the development dataset, the segmentation model trained on 7,311 frames, achieved Dice scores of 70$\pm$3% for anatomical structures and 56$\pm$3% for PC. Video-level AS classification achieved F1-scores of 74$\pm$3% and 73$\pm$4%, FS prediction showed normalized RMSE values of 1.39$\pm$0.18 and 1.15$\pm$0.08, and ItS reached F1-scores of 80$\pm$8% and 80$\pm$2% in the development (n=101) and independent test datasets (n=50), respectively. This is the first AI model to predict the feasibility of cytoreductive surgery providing automated FS estimation from DL videos. Its reproducible and reliable performance across datasets suggests that AI can support surgeons through standardized intraoperative tumor burden assessment and clinical decision-making in AOC.
Learning from Sparse Point Labels for Dense Carcinosis Localization in Advanced Ovarian Cancer Assessment
Jul 09, 2025Learning from sparse labels is a challenge commonplace in the medical domain. This is due to numerous factors, such as annotation cost, and is especially true for newly introduced tasks. When dense pixel-level annotations are needed, this becomes even more unfeasible. However, being able to learn from just a few annotations at the pixel-level, while extremely difficult and underutilized, can drive progress in studies where perfect annotations are not immediately available. This work tackles the challenge of learning the dense prediction task of keypoint localization from a few point annotations in the context of 2d carcinosis keypoint localization from laparoscopic video frames for diagnostic planning of advanced ovarian cancer patients. To enable this, we formulate the problem as a sparse heatmap regression from a few point annotations per image and propose a new loss function, called Crag and Tail loss, for efficient learning. Our proposed loss function effectively leverages positive sparse labels while minimizing the impact of false negatives or missed annotations. Through an extensive ablation study, we demonstrate the effectiveness of our approach in achieving accurate dense localization of carcinosis keypoints, highlighting its potential to advance research in scenarios where dense annotations are challenging to obtain.
A Skull-Adaptive Framework for AI-Based 3D Transcranial Focused Ultrasound Simulation
May 19, 2025Transcranial focused ultrasound (tFUS) is an emerging modality for non-invasive brain stimulation and therapeutic intervention, offering millimeter-scale spatial precision and the ability to target deep brain structures. However, the heterogeneous and anisotropic nature of the human skull introduces significant distortions to the propagating ultrasound wavefront, which require time-consuming patient-specific planning and corrections using numerical solvers for accurate targeting. To enable data-driven approaches in this domain, we introduce TFUScapes, the first large-scale, high-resolution dataset of tFUS simulations through anatomically realistic human skulls derived from T1-weighted MRI images. We have developed a scalable simulation engine pipeline using the k-Wave pseudo-spectral solver, where each simulation returns a steady-state pressure field generated by a focused ultrasound transducer placed at realistic scalp locations. In addition to the dataset, we present DeepTFUS, a deep learning model that estimates normalized pressure fields directly from input 3D CT volumes and transducer position. The model extends a U-Net backbone with transducer-aware conditioning, incorporating Fourier-encoded position embeddings and MLP layers to create global transducer embeddings. These embeddings are fused with U-Net encoder features via feature-wise modulation, dynamic convolutions, and cross-attention mechanisms. The model is trained using a combination of spatially weighted and gradient-sensitive loss functions, enabling it to approximate high-fidelity wavefields. The TFUScapes dataset is publicly released to accelerate research at the intersection of computational acoustics, neurotechnology, and deep learning. The project page is available at https://github.com/CAMMA-public/TFUScapes.
Learning from Synchronization: Self-Supervised Uncalibrated Multi-View Person Association in Challenging Scenes
Mar 17, 2025Multi-view person association is a fundamental step towards multi-view analysis of human activities. Although the person re-identification features have been proven effective, they become unreliable in challenging scenes where persons share similar appearances. Therefore, cross-view geometric constraints are required for a more robust association. However, most existing approaches are either fully-supervised using ground-truth identity labels or require calibrated camera parameters that are hard to obtain. In this work, we investigate the potential of learning from synchronization, and propose a self-supervised uncalibrated multi-view person association approach, Self-MVA, without using any annotations. Specifically, we propose a self-supervised learning framework, consisting of an encoder-decoder model and a self-supervised pretext task, cross-view image synchronization, which aims to distinguish whether two images from different views are captured at the same time. The model encodes each person's unified geometric and appearance features, and we train it by utilizing synchronization labels for supervision after applying Hungarian matching to bridge the gap between instance-wise and image-wise distances. To further reduce the solution space, we propose two types of self-supervised linear constraints: multi-view re-projection and pairwise edge association. Extensive experiments on three challenging public benchmark datasets (WILDTRACK, MVOR, and SOLDIERS) show that our approach achieves state-of-the-art results, surpassing existing unsupervised and fully-supervised approaches. Code is available at https://github.com/CAMMA-public/Self-MVA.
Multi-view Video-Pose Pretraining for Operating Room Surgical Activity Recognition
Feb 19, 2025



Understanding the workflow of surgical procedures in complex operating rooms requires a deep understanding of the interactions between clinicians and their environment. Surgical activity recognition (SAR) is a key computer vision task that detects activities or phases from multi-view camera recordings. Existing SAR models often fail to account for fine-grained clinician movements and multi-view knowledge, or they require calibrated multi-view camera setups and advanced point-cloud processing to obtain better results. In this work, we propose a novel calibration-free multi-view multi-modal pretraining framework called Multiview Pretraining for Video-Pose Surgical Activity Recognition PreViPS, which aligns 2D pose and vision embeddings across camera views. Our model follows CLIP-style dual-encoder architecture: one encoder processes visual features, while the other encodes human pose embeddings. To handle the continuous 2D human pose coordinates, we introduce a tokenized discrete representation to convert the continuous 2D pose coordinates into discrete pose embeddings, thereby enabling efficient integration within the dual-encoder framework. To bridge the gap between these two modalities, we propose several pretraining objectives using cross- and in-modality geometric constraints within the embedding space and incorporating masked pose token prediction strategy to enhance representation learning. Extensive experiments and ablation studies demonstrate improvements over the strong baselines, while data-efficiency experiments on two distinct operating room datasets further highlight the effectiveness of our approach. We highlight the benefits of our approach for surgical activity recognition in both multi-view and single-view settings, showcasing its practical applicability in complex surgical environments. Code will be made available at: https://github.com/CAMMA-public/PreViPS.
When do they StOP?: A First Step Towards Automatically Identifying Team Communication in the Operating Room
Feb 12, 2025Purpose: Surgical performance depends not only on surgeons' technical skills but also on team communication within and across the different professional groups present during the operation. Therefore, automatically identifying team communication in the OR is crucial for patient safety and advances in the development of computer-assisted surgical workflow analysis and intra-operative support systems. To take the first step, we propose a new task of detecting communication briefings involving all OR team members, i.e. the team Time-out and the StOP?-protocol, by localizing their start and end times in video recordings of surgical operations. Methods: We generate an OR dataset of real surgeries, called Team-OR, with more than one hundred hours of surgical videos captured by the multi-view camera system in the OR. The dataset contains temporal annotations of 33 Time-out and 22 StOP?-protocol activities in total. We then propose a novel group activity detection approach, where we encode both scene context and action features, and use an efficient neural network model to output the results. Results: The experimental results on the Team-OR dataset show that our approach outperforms existing state-of-the-art temporal action detection approaches. It also demonstrates the lack of research on group activities in the OR, proving the significance of our dataset. Conclusion: We investigate the Team Time-Out and the StOP?-protocol in the OR, by presenting the first OR dataset with temporal annotations of group activities protocols, and introducing a novel group activity detection approach that outperforms existing approaches. Code is available at https://github.com/CAMMA-public/Team-OR .
Text-driven Adaptation of Foundation Models for Few-shot Surgical Workflow Analysis
Jan 16, 2025Purpose: Surgical workflow analysis is crucial for improving surgical efficiency and safety. However, previous studies rely heavily on large-scale annotated datasets, posing challenges in cost, scalability, and reliance on expert annotations. To address this, we propose Surg-FTDA (Few-shot Text-driven Adaptation), designed to handle various surgical workflow analysis tasks with minimal paired image-label data. Methods: Our approach has two key components. First, Few-shot selection-based modality alignment selects a small subset of images and aligns their embeddings with text embeddings from the downstream task, bridging the modality gap. Second, Text-driven adaptation leverages only text data to train a decoder, eliminating the need for paired image-text data. This decoder is then applied to aligned image embeddings, enabling image-related tasks without explicit image-text pairs. Results: We evaluate our approach to generative tasks (image captioning) and discriminative tasks (triplet recognition and phase recognition). Results show that Surg-FTDA outperforms baselines and generalizes well across downstream tasks. Conclusion: We propose a text-driven adaptation approach that mitigates the modality gap and handles multiple downstream tasks in surgical workflow analysis, with minimal reliance on large annotated datasets. The code and dataset will be released in https://github.com/TingxuanSix/Surg-FTDA.