 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo No Harm: Exposing Hidden Vulnerabilities of LLMs via Persona-based Client Simulation Attack in Psychological Counseling
Apr 06, 2026The increasing use of large language models (LLMs) in mental healthcare raises safety concerns in high-stakes therapeutic interactions. A key challenge is distinguishing therapeutic empathy from maladaptive validation, where supportive responses may inadvertently reinforce harmful beliefs or behaviors in multi-turn conversations. This risk is largely overlooked by existing red-teaming frameworks, which focus mainly on generic harms or optimization-based attacks. To address this gap, we introduce Personality-based Client Simulation Attack (PCSA), the first red-teaming framework that simulates clients in psychological counseling through coherent, persona-driven client dialogues to expose vulnerabilities in psychological safety alignment. Experiments on seven general and mental health-specialized LLMs show that PCSA substantially outperforms four competitive baselines. Perplexity analysis and human inspection further indicate that PCSA generates more natural and realistic dialogues. Our results reveal that current LLMs remain vulnerable to domain-specific adversarial tactics, providing unauthorized medical advice, reinforcing delusions, and implicitly encouraging risky actions.
Tears or Cheers? Benchmarking LLMs via Culturally Elicited Distinct Affective Responses
Jan 19, 2026Culture serves as a fundamental determinant of human affective processing and profoundly shapes how individuals perceive and interpret emotional stimuli. Despite this intrinsic link extant evaluations regarding cultural alignment within Large Language Models primarily prioritize declarative knowledge such as geographical facts or established societal customs. These benchmarks remain insufficient to capture the subjective interpretative variance inherent to diverse sociocultural lenses. To address this limitation, we introduce CEDAR, a multimodal benchmark constructed entirely from scenarios capturing Culturally \underline{\textsc{E}}licited \underline{\textsc{D}}istinct \underline{\textsc{A}}ffective \underline{\textsc{R}}esponses. To construct CEDAR, we implement a novel pipeline that leverages LLM-generated provisional labels to isolate instances yielding cross-cultural emotional distinctions, and subsequently derives reliable ground-truth annotations through rigorous human evaluation. The resulting benchmark comprises 10,962 instances across seven languages and 14 fine-grained emotion categories, with each language including 400 multimodal and 1,166 text-only samples. Comprehensive evaluations of 17 representative multilingual models reveal a dissociation between language consistency and cultural alignment, demonstrating that culturally grounded affective understanding remains a significant challenge for current models.
PsychEthicsBench: Evaluating Large Language Models Against Australian Mental Health Ethics
Jan 07, 2026The increasing integration of large language models (LLMs) into mental health applications necessitates robust frameworks for evaluating professional safety alignment. Current evaluative approaches primarily rely on refusal-based safety signals, which offer limited insight into the nuanced behaviors required in clinical practice. In mental health, clinically inadequate refusals can be perceived as unempathetic and discourage help-seeking. To address this gap, we move beyond refusal-centric metrics and introduce \texttt{PsychEthicsBench}, the first principle-grounded benchmark based on Australian psychology and psychiatry guidelines, designed to evaluate LLMs' ethical knowledge and behavioral responses through multiple-choice and open-ended tasks with fine-grained ethicality annotations. Empirical results across 14 models reveal that refusal rates are poor indicators of ethical behavior, revealing a significant divergence between safety triggers and clinical appropriateness. Notably, we find that domain-specific fine-tuning can degrade ethical robustness, as several specialized models underperform their base backbones in ethical alignment. PsychEthicsBench provides a foundation for systematic, jurisdiction-aware evaluation of LLMs in mental health, encouraging more responsible development in this domain.
Medical Multimodal Model Stealing Attacks via Adversarial Domain Alignment
Feb 04, 2025Medical multimodal large language models (MLLMs) are becoming an instrumental part of healthcare systems, assisting medical personnel with decision making and results analysis. Models for radiology report generation are able to interpret medical imagery, thus reducing the workload of radiologists. As medical data is scarce and protected by privacy regulations, medical MLLMs represent valuable intellectual property. However, these assets are potentially vulnerable to model stealing, where attackers aim to replicate their functionality via black-box access. So far, model stealing for the medical domain has focused on classification; however, existing attacks are not effective against MLLMs. In this paper, we introduce Adversarial Domain Alignment (ADA-STEAL), the first stealing attack against medical MLLMs. ADA-STEAL relies on natural images, which are public and widely available, as opposed to their medical counterparts. We show that data augmentation with adversarial noise is sufficient to overcome the data distribution gap between natural images and the domain-specific distribution of the victim MLLM. Experiments on the IU X-RAY and MIMIC-CXR radiology datasets demonstrate that Adversarial Domain Alignment enables attackers to steal the medical MLLM without any access to medical data.
OphCLIP: Hierarchical Retrieval-Augmented Learning for Ophthalmic Surgical Video-Language Pretraining
Nov 23, 2024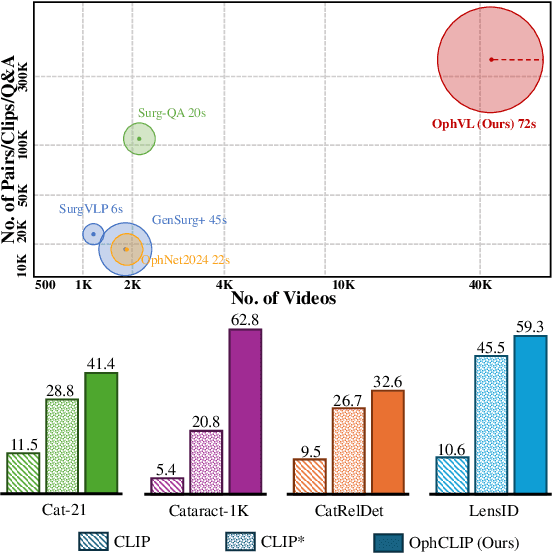
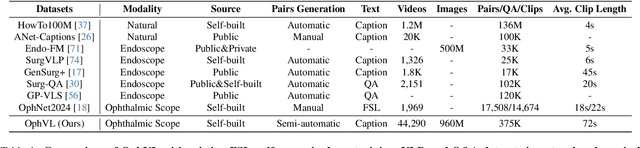
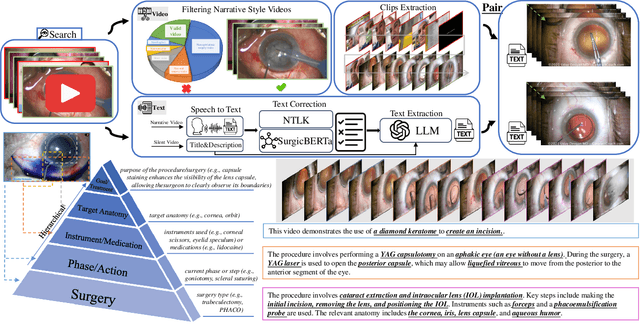
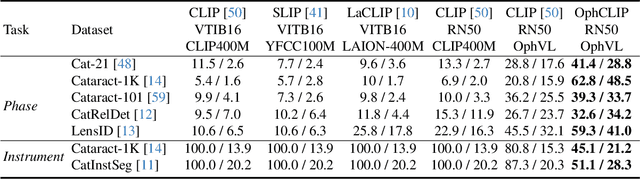
Surgical practice involves complex visual interpretation, procedural skills, and advanced medical knowledge, making surgical vision-language pretraining (VLP) particularly challenging due to this complexity and the limited availability of annotated data. To address the gap, we propose OphCLIP, a hierarchical retrieval-augmented vision-language pretraining framework specifically designed for ophthalmic surgical workflow understanding. OphCLIP leverages the OphVL dataset we constructed, a large-scale and comprehensive collection of over 375K hierarchically structured video-text pairs with tens of thousands of different combinations of attributes (surgeries, phases/operations/actions, instruments, medications, as well as more advanced aspects like the causes of eye diseases, surgical objectives, and postoperative recovery recommendations, etc). These hierarchical video-text correspondences enable OphCLIP to learn both fine-grained and long-term visual representations by aligning short video clips with detailed narrative descriptions and full videos with structured titles, capturing intricate surgical details and high-level procedural insights, respectively. Our OphCLIP also designs a retrieval-augmented pretraining framework to leverage the underexplored large-scale silent surgical procedure videos, automatically retrieving semantically relevant content to enhance the representation learning of narrative videos. Evaluation across 11 datasets for phase recognition and multi-instrument identification shows OphCLIP's robust generalization and superior performance.
Hero-Gang Neural Model For Named Entity Recognition
May 15, 2022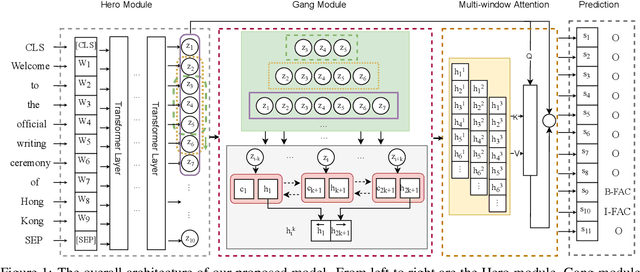

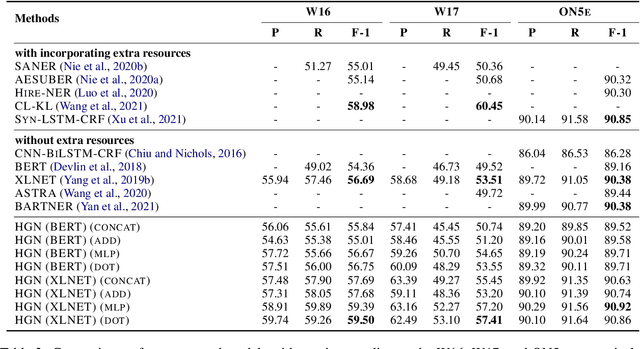
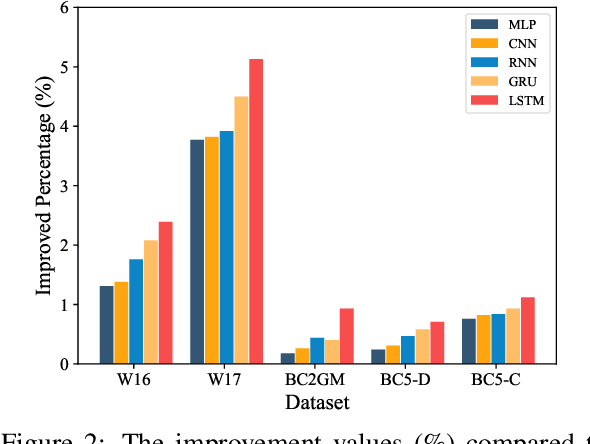
Named entity recognition (NER) is a fundamental and important task in NLP, aiming at identifying named entities (NEs) from free text. Recently, since the multi-head attention mechanism applied in the Transformer model can effectively capture longer contextual information, Transformer-based models have become the mainstream methods and have achieved significant performance in this task. Unfortunately, although these models can capture effective global context information, they are still limited in the local feature and position information extraction, which is critical in NER. In this paper, to address this limitation, we propose a novel Hero-Gang Neural structure (HGN), including the Hero and Gang module, to leverage both global and local information to promote NER. Specifically, the Hero module is composed of a Transformer-based encoder to maintain the advantage of the self-attention mechanism, and the Gang module utilizes a multi-window recurrent module to extract local features and position information under the guidance of the Hero module. Afterward, the proposed multi-window attention effectively combines global information and multiple local features for predicting entity labels. Experimental results on several benchmark datasets demonstrate the effectiveness of our proposed model.
Cross-modal Memory Networks for Radiology Report Generation
Apr 28, 2022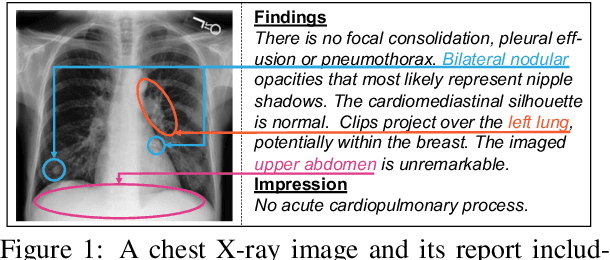


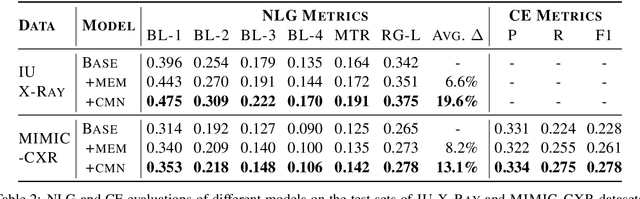
Medical imaging plays a significant role in clinical practice of medical diagnosis, where the text reports of the images are essential in understanding them and facilitating later treatments. By generating the reports automatically, it is beneficial to help lighten the burden of radiologists and significantly promote clinical automation, which already attracts much attention in applying artificial intelligence to medical domain. Previous studies mainly follow the encoder-decoder paradigm and focus on the aspect of text generation, with few studies considering the importance of cross-modal mappings and explicitly exploit such mappings to facilitate radiology report generation. In this paper, we propose a cross-modal memory networks (CMN) to enhance the encoder-decoder framework for radiology report generation, where a shared memory is designed to record the alignment between images and texts so as to facilitate the interaction and generation across modalities. Experimental results illustrate the effectiveness of our proposed model, where state-of-the-art performance is achieved on two widely used benchmark datasets, i.e., IU X-Ray and MIMIC-CXR. Further analyses also prove that our model is able to better align information from radiology images and texts so as to help generating more accurate reports in terms of clinical indicators.
Word Graph Guided Summarization for Radiology Findings
Dec 18, 2021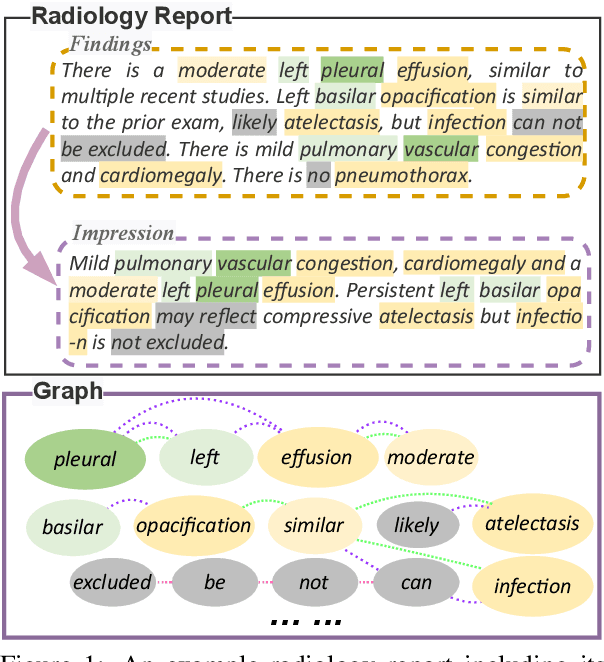
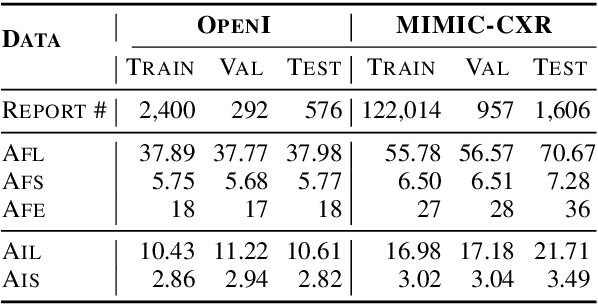
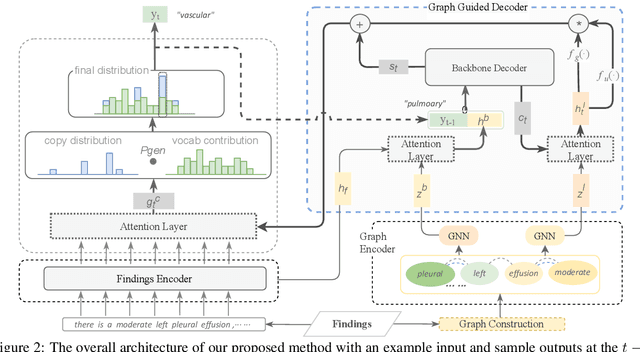
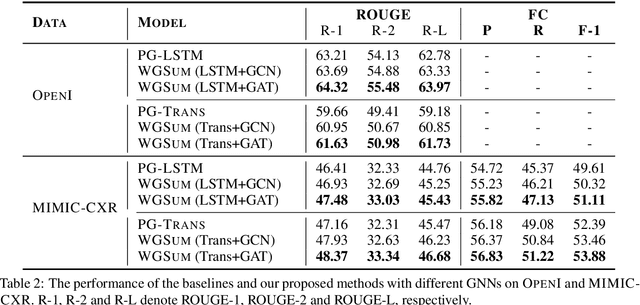
Radiology reports play a critical role in communicating medical findings to physicians. In each report, the impression section summarizes essential radiology findings. In clinical practice, writing impression is highly demanded yet time-consuming and prone to errors for radiologists. Therefore, automatic impression generation has emerged as an attractive research direction to facilitate such clinical practice. Existing studies mainly focused on introducing salient word information to the general text summarization framework to guide the selection of the key content in radiology findings. However, for this task, a model needs not only capture the important words in findings but also accurately describe their relations so as to generate high-quality impressions. In this paper, we propose a novel method for automatic impression generation, where a word graph is constructed from the findings to record the critical words and their relations, then a Word Graph guided Summarization model (WGSum) is designed to generate impressions with the help of the word graph. Experimental results on two datasets, OpenI and MIMIC-CXR, confirm the validity and effectiveness of our proposed approach, where the state-of-the-art results are achieved on both datasets. Further experiments are also conducted to analyze the impact of different graph designs to the performance of our method.