 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Scene, Two Depths: Probing Geometric Ambiguity in Monocular Foundation Models
Jun 28, 2026A faithful 3D world representation should account for layered geometry, where a single camera ray may contain multiple visible and geometrically valid surfaces. Monocular depth estimation, however, reduces this structure to one scalar depth per pixel. Transparent scenes make this ambiguity measurable: the same ray can pass through foreground glass and observe the background, turning the supervised target into a convention of annotation, data, and training rather than a scene-intrinsic truth. A learned predictor exposes this convention as its depth-layer preference. We introduce MultiDepth-3k (MD-3k), a sparse two-layer ordinal benchmark for measuring depth-layer preference and multi-layer spatial relationship accuracy (ML-SRA). On MD-3k, leading depth foundation models exhibit diverse layer preferences under standard RGB input, showing that the same layered geometry can be resolved differently across models. We further find that Laplacian Visual Prompting (LVP), a training-free spectral input transformation, can substantially change the reported layer for certain frozen models. The strongest RGB/LVP pair, DAv2-L, reaches 75.5% ML-SRA. These results suggest that depth foundation models may express complementary geometric hypotheses that standard RGB inference leaves unexpressed. We invite the community to rethink depth supervision and evaluation through an ambiguity-aware lens, where multiple valid 3D interpretations are treated as geometric structure to be measured, preserved, and expressed.
Probing Collision Grounding in Vision-Language Models for Safe Human-Robot Collaboration
May 29, 2026Safe human--robot collaboration requires more than visual description: a monitor must determine whether the robot body is safely separated, already colliding with the scene or a person, or about to collide. We call this capability collision grounding: binding visual observations to robot body geometry, camera viewpoint, scene layout, human proximity, and temporal motion in order to infer present and imminent contact. We introduce TouchSafeBench, a physics-grounded benchmark for evaluating collision grounding in vision-language models (VLMs). Built in Habitat~3.0, TouchSafeBench contains 2,940 simulated indoor co-presence episodes across social navigation and social rearrangement, with synchronized multi-view RGB-D observations, top-down trajectory maps, calibrated camera metadata, and simulator-derived contact labels. We study two deployment-facing tasks: classifying the current safety state and warning about imminent collision before contact. Across three frontier or robotics-oriented VLMs and nine visual representations, current models remain far from reliable: the best average Macro-F1 stays below 50\%, explicit depth is not automatically transformed into robot-body collision evidence, and robot--scene contact is consistently harder than human-contact risk. TouchSafeBench reveals a central limitation of embodied VLMs: visual fluency does not imply physical accountability. Reliable robot safety monitors will need representations that explicitly bind viewpoint, robot morphology, metric geometry, and future collision. We will release the benchmark upon acceptance.
When Search Becomes Memory: Turning Robot Design Trials into Transferable Skills
May 25, 2026Large language models (LLMs) are increasingly used as proposal generators for evolutionary robot design, yet most loops remain memoryless: simulator results shape the next population but are not preserved as reusable design knowledge. We present Auto-Robotist, a self-evolving LLM agent that distills morphology-search traces into an explicit natural-language skill library. Each skill stores a structural archetype, evidence-grounded positive and negative rules, and the evaluated designs that support them, making design memory inspectable rather than implicit in a population. During search, the agent retrieves skills to condition LLM edits of elite bodies while retaining a Genetic Algorithm (GA) mutation path for exploration; after evaluation, it updates the library through Add, Diagnose, and Merge. Across seven EvoGym tasks spanning locomotion, traversal, and object interaction, Auto-Robotist improves cold-start 5x5 search and transfers learned skills to 10x10 design spaces, where reference-conditioned transfer outperforms GA on every task. These results suggest that LLM agents can convert expensive physical evaluations into reusable, auditable design principles. Our code will be released upon acceptance.
Multi-turn Physics-informed Vision-language Model for Physics-grounded Anomaly Detection
Mar 16, 2026Vision-Language Models (VLMs) demonstrate strong general-purpose reasoning but remain limited in physics-grounded anomaly detection, where causal understanding of dynamics is essential. Existing VLMs, trained predominantly on appearance-centric correlations, fail to capture kinematic constraints, leading to poor performance on anomalies such as irregular rotations or violated mechanical motions. We introduce a physics-informed instruction tuning framework that explicitly encodes object properties, motion paradigms, and dynamic constraints into structured prompts. By delivering these physical priors through multi-turn dialogues, our method decomposes causal reasoning into incremental steps, enabling robust internal representations of normal and abnormal dynamics. Evaluated on the Phys-AD benchmark, our approach achieves 96.7% AUROC in video-level detection--substantially outperforming prior SOTA (66.9%)--and yields superior causal explanations (0.777 LLM score). This work highlights how structured physics priors can transform VLMs into reliable detectors of dynamic anomalies.
Photorealistic Phantom Roads in Real Scenes: Disentangling 3D Hallucinations from Physical Geometry
Dec 17, 2025Monocular depth foundation models achieve remarkable generalization by learning large-scale semantic priors, but this creates a critical vulnerability: they hallucinate illusory 3D structures from geometrically planar but perceptually ambiguous inputs. We term this failure the 3D Mirage. This paper introduces the first end-to-end framework to probe, quantify, and tame this unquantified safety risk. To probe, we present 3D-Mirage, the first benchmark of real-world illusions (e.g., street art) with precise planar-region annotations and context-restricted crops. To quantify, we propose a Laplacian-based evaluation framework with two metrics: the Deviation Composite Score (DCS) for spurious non-planarity and the Confusion Composite Score (CCS) for contextual instability. To tame this failure, we introduce Grounded Self-Distillation, a parameter-efficient strategy that surgically enforces planarity on illusion ROIs while using a frozen teacher to preserve background knowledge, thus avoiding catastrophic forgetting. Our work provides the essential tools to diagnose and mitigate this phenomenon, urging a necessary shift in MDE evaluation from pixel-wise accuracy to structural and contextual robustness. Our code and benchmark will be publicly available to foster this exciting research direction.
Whole-Body Proprioceptive Morphing: A Modular Soft Gripper for Robust Cross-Scale Grasping
Oct 31, 2025Biological systems, such as the octopus, exhibit masterful cross-scale manipulation by adaptively reconfiguring their entire form, a capability that remains elusive in robotics. Conventional soft grippers, while compliant, are mostly constrained by a fixed global morphology, and prior shape-morphing efforts have been largely confined to localized deformations, failing to replicate this biological dexterity. Inspired by this natural exemplar, we introduce the paradigm of collaborative, whole-body proprioceptive morphing, realized in a modular soft gripper architecture. Our design is a distributed network of modular self-sensing pneumatic actuators that enables the gripper to intelligently reconfigure its entire topology, achieving multiple morphing states that are controllable to form diverse polygonal shapes. By integrating rich proprioceptive feedback from embedded sensors, our system can seamlessly transition from a precise pinch to a large envelope grasp. We experimentally demonstrate that this approach expands the grasping envelope and enhances generalization across diverse object geometries (standard and irregular) and scales (up to 10$\times$), while also unlocking novel manipulation modalities such as multi-object and internal hook grasping. This work presents a low-cost, easy-to-fabricate, and scalable framework that fuses distributed actuation with integrated sensing, offering a new pathway toward achieving biological levels of dexterity in robotic manipulation.
Image Tokenizer Needs Post-Training
Sep 15, 2025Recent image generative models typically capture the image distribution in a pre-constructed latent space, relying on a frozen image tokenizer. However, there exists a significant discrepancy between the reconstruction and generation distribution, where current tokenizers only prioritize the reconstruction task that happens before generative training without considering the generation errors during sampling. In this paper, we comprehensively analyze the reason for this discrepancy in a discrete latent space, and, from which, we propose a novel tokenizer training scheme including both main-training and post-training, focusing on improving latent space construction and decoding respectively. During the main training, a latent perturbation strategy is proposed to simulate sampling noises, \ie, the unexpected tokens generated in generative inference. Specifically, we propose a plug-and-play tokenizer training scheme, which significantly enhances the robustness of tokenizer, thus boosting the generation quality and convergence speed, and a novel tokenizer evaluation metric, \ie, pFID, which successfully correlates the tokenizer performance to generation quality. During post-training, we further optimize the tokenizer decoder regarding a well-trained generative model to mitigate the distribution difference between generated and reconstructed tokens. With a $\sim$400M generator, a discrete tokenizer trained with our proposed main training achieves a notable 1.60 gFID and further obtains 1.36 gFID with the additional post-training. Further experiments are conducted to broadly validate the effectiveness of our post-training strategy on off-the-shelf discrete and continuous tokenizers, coupled with autoregressive and diffusion-based generators.
Bridging 3D Anomaly Localization and Repair via High-Quality Continuous Geometric Representation
May 30, 2025



3D point cloud anomaly detection is essential for robust vision systems but is challenged by pose variations and complex geometric anomalies. Existing patch-based methods often suffer from geometric fidelity issues due to discrete voxelization or projection-based representations, limiting fine-grained anomaly localization. We introduce Pose-Aware Signed Distance Field (PASDF), a novel framework that integrates 3D anomaly detection and repair by learning a continuous, pose-invariant shape representation. PASDF leverages a Pose Alignment Module for canonicalization and a SDF Network to dynamically incorporate pose, enabling implicit learning of high-fidelity anomaly repair templates from the continuous SDF. This facilitates precise pixel-level anomaly localization through an Anomaly-Aware Scoring Module. Crucially, the continuous 3D representation in PASDF extends beyond detection, facilitating in-situ anomaly repair. Experiments on Real3D-AD and Anomaly-ShapeNet demonstrate state-of-the-art performance, achieving high object-level AUROC scores of 80.2% and 90.0%, respectively. These results highlight the effectiveness of continuous geometric representations in advancing 3D anomaly detection and facilitating practical anomaly region repair. The code is available at https://github.com/ZZZBBBZZZ/PASDF to support further research.
Visual Anomaly Detection under Complex View-Illumination Interplay: A Large-Scale Benchmark
May 16, 2025The practical deployment of Visual Anomaly Detection (VAD) systems is hindered by their sensitivity to real-world imaging variations, particularly the complex interplay between viewpoint and illumination which drastically alters defect visibility. Current benchmarks largely overlook this critical challenge. We introduce Multi-View Multi-Illumination Anomaly Detection (M2AD), a new large-scale benchmark comprising 119,880 high-resolution images designed explicitly to probe VAD robustness under such interacting conditions. By systematically capturing 999 specimens across 10 categories using 12 synchronized views and 10 illumination settings (120 configurations total), M2AD enables rigorous evaluation. We establish two evaluation protocols: M2AD-Synergy tests the ability to fuse information across diverse configurations, and M2AD-Invariant measures single-image robustness against realistic view-illumination effects. Our extensive benchmarking shows that state-of-the-art VAD methods struggle significantly on M2AD, demonstrating the profound challenge posed by view-illumination interplay. This benchmark serves as an essential tool for developing and validating VAD methods capable of overcoming real-world complexities. Our full dataset and test suite will be released at https://hustcyq.github.io/M2AD to facilitate the field.
ViSA-Flow: Accelerating Robot Skill Learning via Large-Scale Video Semantic Action Flow
May 02, 2025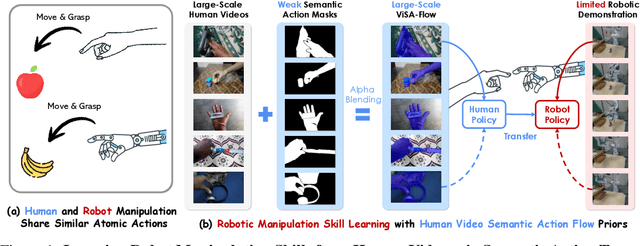
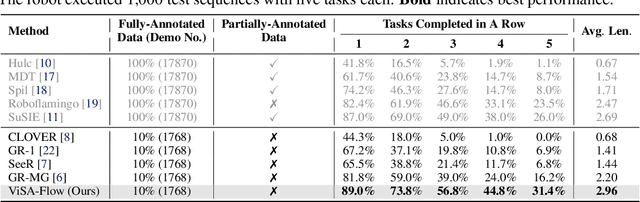
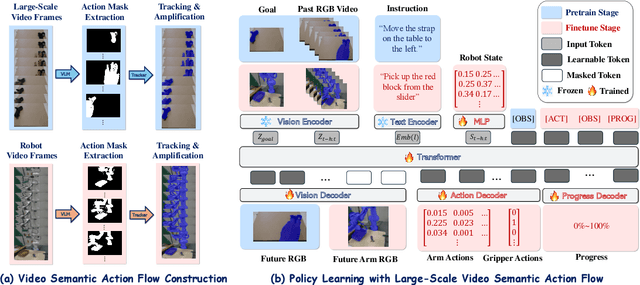
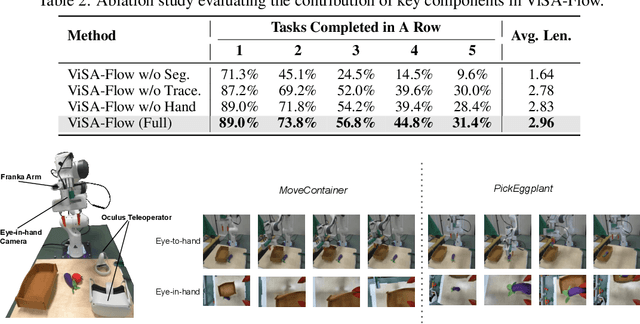
One of the central challenges preventing robots from acquiring complex manipulation skills is the prohibitive cost of collecting large-scale robot demonstrations. In contrast, humans are able to learn efficiently by watching others interact with their environment. To bridge this gap, we introduce semantic action flow as a core intermediate representation capturing the essential spatio-temporal manipulator-object interactions, invariant to superficial visual differences. We present ViSA-Flow, a framework that learns this representation self-supervised from unlabeled large-scale video data. First, a generative model is pre-trained on semantic action flows automatically extracted from large-scale human-object interaction video data, learning a robust prior over manipulation structure. Second, this prior is efficiently adapted to a target robot by fine-tuning on a small set of robot demonstrations processed through the same semantic abstraction pipeline. We demonstrate through extensive experiments on the CALVIN benchmark and real-world tasks that ViSA-Flow achieves state-of-the-art performance, particularly in low-data regimes, outperforming prior methods by effectively transferring knowledge from human video observation to robotic execution. Videos are available at https://visaflow-web.github.io/ViSAFLOW.