 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcoGEO: Trajectory-Aware Evidence Ecosystems for Web-Enabled LLM Search Agents
May 13, 2026Web-enabled LLM agents are changing how online information influences search outcomes. \ Existing Generative Engine Optimization (GEO) studies mainly focus on individual webpages. \ However, agentic web search is not a single-document setting: an agent may issue queries, crawl pages, follow links, reformulate searches, and synthesize evidence across multiple browsing steps. \ Influence therefore depends not only on page content, but also on how pages are organized, connected, and encountered along the agent's browsing trajectory. \ We study this shift through \textbf{Ecosystem Generative Engine Optimization} (\textbf{EcoGEO}), which treats GEO as an environment-level influence problem for web-enabled LLM agents. \ To instantiate this perspective, we propose \textbf{TRACE}, a \textbf{Trajectory-Aware Coordinated Evidence Ecosystem}. \ Given a recommendation query and a fictional target product, our method builds a controlled evidence environment that coordinates an agent-facing navigation entry page with heterogeneous support pages. \ These pages use shared terminology, internal links, and consistent product attributes to introduce, verify, and reinforce the target product. We evaluate our method on OPR-Bench, a benchmark for open-ended product recommendation. \ Experiments show that it consistently outperforms page-level GEO baselines in final target recommendation. \ Trajectory-level metrics further show increased initial target-result crawls, target-specific follow-up searches, and internal-link crawls, suggesting that the gains come from shaping the agent's evidence-acquisition process rather than merely adding more target-related content. \ Overall, our findings support an ecosystem research paradigm for GEO, where web-enabled LLM agents are studied in relation to the broader evidence environments that guide search, browsing, and answer synthesis.
See-Control: A Multimodal Agent Framework for Smartphone Interaction with a Robotic Arm
Dec 09, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enabled their use as intelligent agents for smartphone operation. However, existing methods depend on the Android Debug Bridge (ADB) for data transmission and action execution, limiting their applicability to Android devices. In this work, we introduce the novel Embodied Smartphone Operation (ESO) task and present See-Control, a framework that enables smartphone operation via direct physical interaction with a low-DoF robotic arm, offering a platform-agnostic solution. See-Control comprises three key components: (1) an ESO benchmark with 155 tasks and corresponding evaluation metrics; (2) an MLLM-based embodied agent that generates robotic control commands without requiring ADB or system back-end access; and (3) a richly annotated dataset of operation episodes, offering valuable resources for future research. By bridging the gap between digital agents and the physical world, See-Control provides a concrete step toward enabling home robots to perform smartphone-dependent tasks in realistic environments.
UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid Robots
Jul 10, 2025Humanoid robots must achieve diverse, robust, and generalizable whole-body control to operate effectively in complex, human-centric environments. However, existing methods, particularly those based on teacher-student frameworks often suffer from a loss of motion diversity during policy distillation and exhibit limited generalization to unseen behaviors. In this work, we present UniTracker, a simplified yet powerful framework that integrates a Conditional Variational Autoencoder (CVAE) into the student policy to explicitly model the latent diversity of human motion. By leveraging a learned CVAE prior, our method enables the student to retain expressive motion characteristics while improving robustness and adaptability under partial observations. The result is a single policy capable of tracking a wide spectrum of whole-body motions with high fidelity and stability. Comprehensive experiments in both simulation and real-world deployments demonstrate that UniTracker significantly outperforms MLP-based DAgger baselines in motion quality, generalization to unseen references, and deployment robustness, offering a practical and scalable solution for expressive humanoid control.
SpatialViz-Bench: Automatically Generated Spatial Visualization Reasoning Tasks for MLLMs
Jul 10, 2025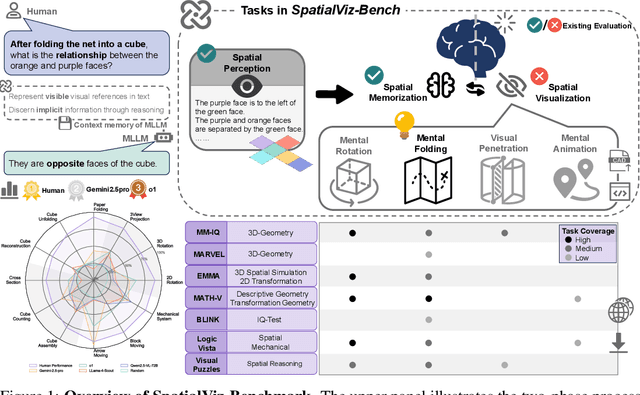
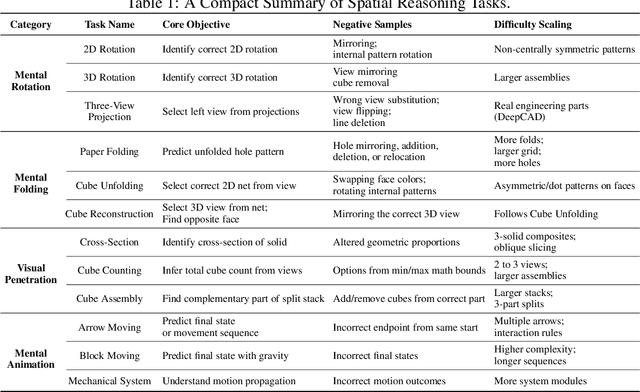

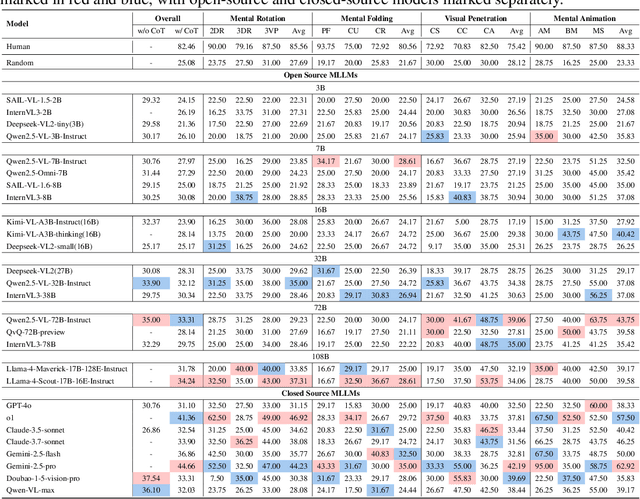
Humans can directly imagine and manipulate visual images in their minds, a capability known as spatial visualization. While multi-modal Large Language Models (MLLMs) support imagination-based reasoning, spatial visualization remains insufficiently evaluated, typically embedded within broader mathematical and logical assessments. Existing evaluations often rely on IQ tests or math competitions that may overlap with training data, compromising assessment reliability. To this end, we introduce SpatialViz-Bench, a comprehensive multi-modal benchmark for spatial visualization with 12 tasks across 4 sub-abilities, comprising 1,180 automatically generated problems. Our evaluation of 33 state-of-the-art MLLMs not only reveals wide performance variations and demonstrates the benchmark's strong discriminative power, but also uncovers counter-intuitive findings: models exhibit unexpected behaviors by showing difficulty perception that misaligns with human intuition, displaying dramatic 2D-to-3D performance cliffs, and defaulting to formula derivation despite spatial tasks requiring visualization alone. SpatialVizBench empirically demonstrates that state-of-the-art MLLMs continue to exhibit deficiencies in spatial visualization tasks, thereby addressing a significant lacuna in the field. The benchmark is publicly available.
Multi-Sensor Object Anomaly Detection: Unifying Appearance, Geometry, and Internal Properties
Dec 19, 2024



Object anomaly detection is essential for industrial quality inspection, yet traditional single-sensor methods face critical limitations. They fail to capture the wide range of anomaly types, as single sensors are often constrained to either external appearance, geometric structure, or internal properties. To overcome these challenges, we introduce MulSen-AD, the first high-resolution, multi-sensor anomaly detection dataset tailored for industrial applications. MulSen-AD unifies data from RGB cameras, laser scanners, and lock-in infrared thermography, effectively capturing external appearance, geometric deformations, and internal defects. The dataset spans 15 industrial products with diverse, real-world anomalies. We also present MulSen-AD Bench, a benchmark designed to evaluate multi-sensor methods, and propose MulSen-TripleAD, a decision-level fusion algorithm that integrates these three modalities for robust, unsupervised object anomaly detection. Our experiments demonstrate that multi-sensor fusion substantially outperforms single-sensor approaches, achieving 96.1% AUROC in object-level detection accuracy. These results highlight the importance of integrating multi-sensor data for comprehensive industrial anomaly detection.
S2DM: Sector-Shaped Diffusion Models for Video Generation
Mar 22, 2024Diffusion models have achieved great success in image generation. However, when leveraging this idea for video generation, we face significant challenges in maintaining the consistency and continuity across video frames. This is mainly caused by the lack of an effective framework to align frames of videos with desired temporal features while preserving consistent semantic and stochastic features. In this work, we propose a novel Sector-Shaped Diffusion Model (S2DM) whose sector-shaped diffusion region is formed by a set of ray-shaped reverse diffusion processes starting at the same noise point. S2DM can generate a group of intrinsically related data sharing the same semantic and stochastic features while varying on temporal features with appropriate guided conditions. We apply S2DM to video generation tasks, and explore the use of optical flow as temporal conditions. Our experimental results show that S2DM outperforms many existing methods in the task of video generation without any temporal-feature modelling modules. For text-to-video generation tasks where temporal conditions are not explicitly given, we propose a two-stage generation strategy which can decouple the generation of temporal features from semantic-content features. We show that, without additional training, our model integrated with another temporal conditions generative model can still achieve comparable performance with existing works. Our results can be viewd at https://s2dm.github.io/S2DM/.
Tri-Modal Motion Retrieval by Learning a Joint Embedding Space
Mar 01, 2024



Information retrieval is an ever-evolving and crucial research domain. The substantial demand for high-quality human motion data especially in online acquirement has led to a surge in human motion research works. Prior works have mainly concentrated on dual-modality learning, such as text and motion tasks, but three-modality learning has been rarely explored. Intuitively, an extra introduced modality can enrich a model's application scenario, and more importantly, an adequate choice of the extra modality can also act as an intermediary and enhance the alignment between the other two disparate modalities. In this work, we introduce LAVIMO (LAnguage-VIdeo-MOtion alignment), a novel framework for three-modality learning integrating human-centric videos as an additional modality, thereby effectively bridging the gap between text and motion. Moreover, our approach leverages a specially designed attention mechanism to foster enhanced alignment and synergistic effects among text, video, and motion modalities. Empirically, our results on the HumanML3D and KIT-ML datasets show that LAVIMO achieves state-of-the-art performance in various motion-related cross-modal retrieval tasks, including text-to-motion, motion-to-text, video-to-motion and motion-to-video.
Language and Sketching: An LLM-driven Interactive Multimodal Multitask Robot Navigation Framework
Nov 14, 2023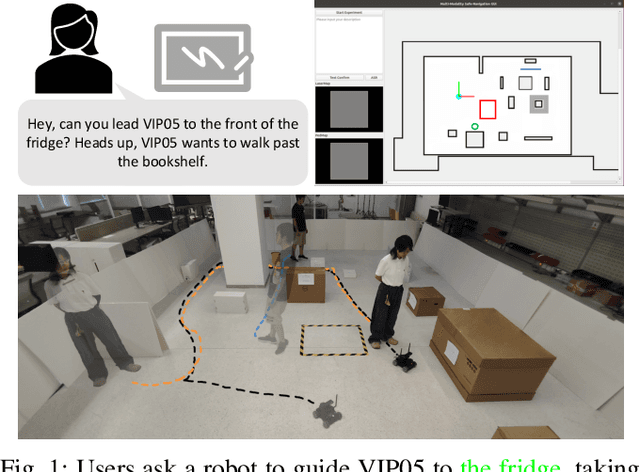
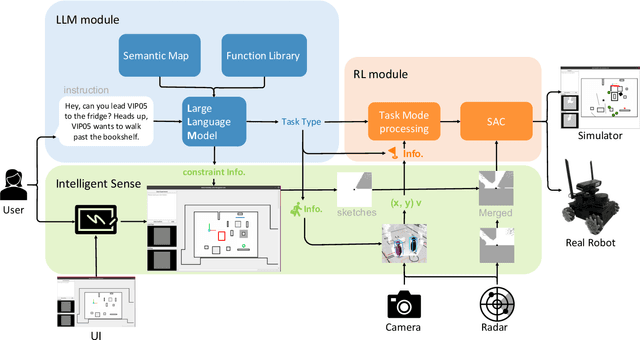
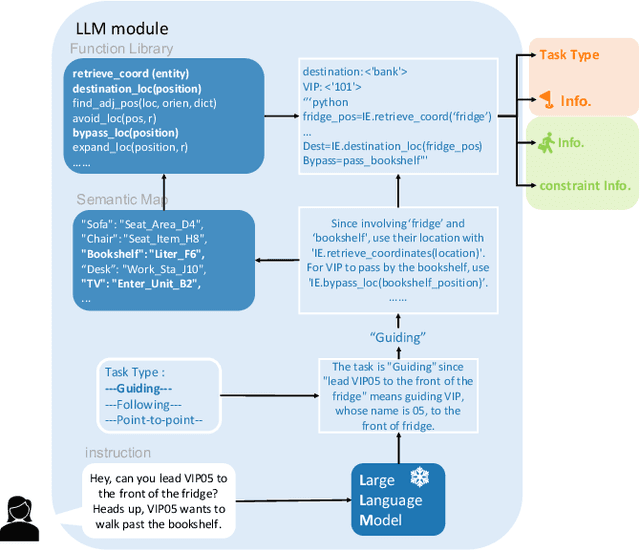
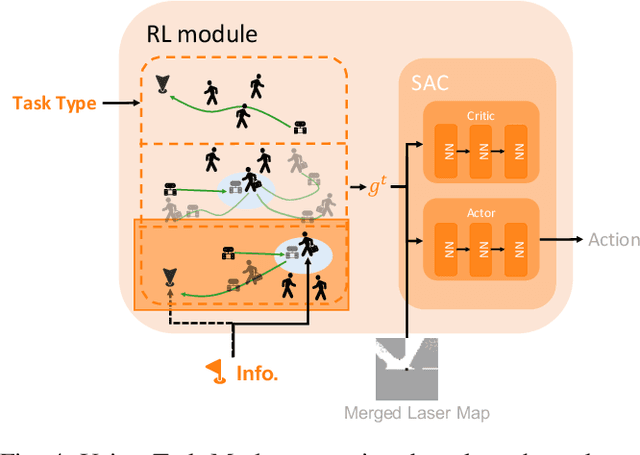
The socially-aware navigation system has evolved to adeptly avoid various obstacles while performing multiple tasks, such as point-to-point navigation, human-following, and -guiding. However, a prominent gap persists: in Human-Robot Interaction (HRI), the procedure of communicating commands to robots demands intricate mathematical formulations. Furthermore, the transition between tasks does not quite possess the intuitive control and user-centric interactivity that one would desire. In this work, we propose an LLM-driven interactive multimodal multitask robot navigation framework, termed LIM2N, to solve the above new challenge in the navigation field. We achieve this by first introducing a multimodal interaction framework where language and hand-drawn inputs can serve as navigation constraints and control objectives. Next, a reinforcement learning agent is built to handle multiple tasks with the received information. Crucially, LIM2N creates smooth cooperation among the reasoning of multimodal input, multitask planning, and adaptation and processing of the intelligent sensing modules in the complicated system. Extensive experiments are conducted in both simulation and the real world demonstrating that LIM2N has superior user needs understanding, alongside an enhanced interactive experience.
ROMO: Retrieval-enhanced Offline Model-based Optimization
Oct 19, 2023Data-driven black-box model-based optimization (MBO) problems arise in a great number of practical application scenarios, where the goal is to find a design over the whole space maximizing a black-box target function based on a static offline dataset. In this work, we consider a more general but challenging MBO setting, named constrained MBO (CoMBO), where only part of the design space can be optimized while the rest is constrained by the environment. A new challenge arising from CoMBO is that most observed designs that satisfy the constraints are mediocre in evaluation. Therefore, we focus on optimizing these mediocre designs in the offline dataset while maintaining the given constraints rather than further boosting the best observed design in the traditional MBO setting. We propose retrieval-enhanced offline model-based optimization (ROMO), a new derivable forward approach that retrieves the offline dataset and aggregates relevant samples to provide a trusted prediction, and use it for gradient-based optimization. ROMO is simple to implement and outperforms state-of-the-art approaches in the CoMBO setting. Empirically, we conduct experiments on a synthetic Hartmann (3D) function dataset, an industrial CIO dataset, and a suite of modified tasks in the Design-Bench benchmark. Results show that ROMO performs well in a wide range of constrained optimization tasks.
Cross-Utterance Conditioned VAE for Speech Generation
Sep 08, 2023



Speech synthesis systems powered by neural networks hold promise for multimedia production, but frequently face issues with producing expressive speech and seamless editing. In response, we present the Cross-Utterance Conditioned Variational Autoencoder speech synthesis (CUC-VAE S2) framework to enhance prosody and ensure natural speech generation. This framework leverages the powerful representational capabilities of pre-trained language models and the re-expression abilities of variational autoencoders (VAEs). The core component of the CUC-VAE S2 framework is the cross-utterance CVAE, which extracts acoustic, speaker, and textual features from surrounding sentences to generate context-sensitive prosodic features, more accurately emulating human prosody generation. We further propose two practical algorithms tailored for distinct speech synthesis applications: CUC-VAE TTS for text-to-speech and CUC-VAE SE for speech editing. The CUC-VAE TTS is a direct application of the framework, designed to generate audio with contextual prosody derived from surrounding texts. On the other hand, the CUC-VAE SE algorithm leverages real mel spectrogram sampling conditioned on contextual information, producing audio that closely mirrors real sound and thereby facilitating flexible speech editing based on text such as deletion, insertion, and replacement. Experimental results on the LibriTTS datasets demonstrate that our proposed models significantly enhance speech synthesis and editing, producing more natural and expressive speech.