 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage and Sketching: An LLM-driven Interactive Multimodal Multitask Robot Navigation Framework
Nov 14, 2023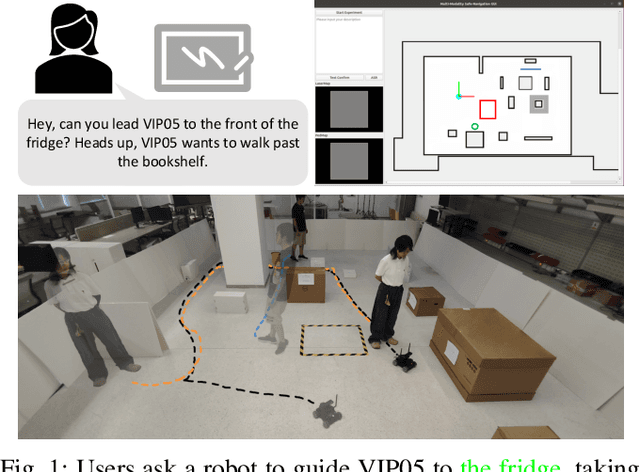
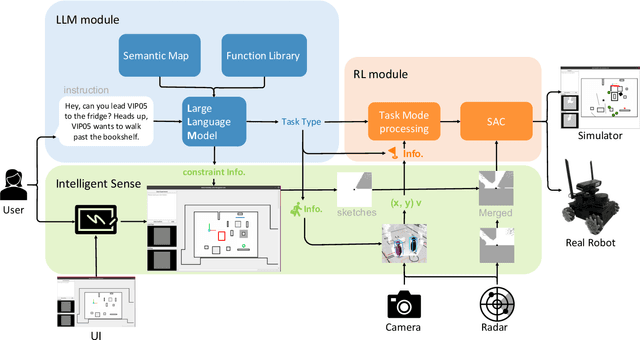
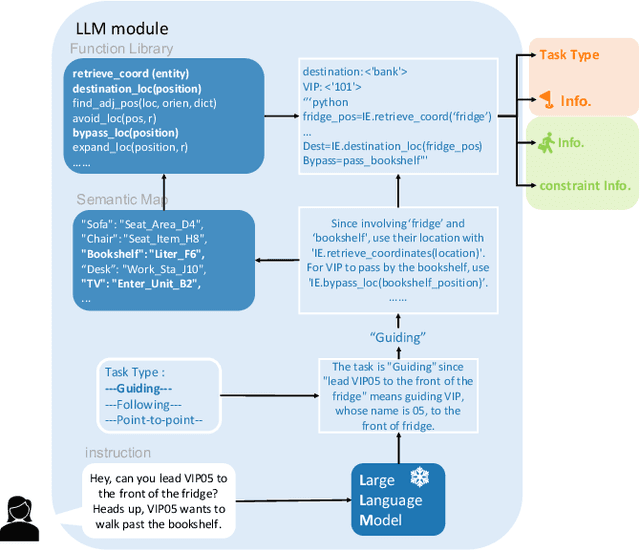
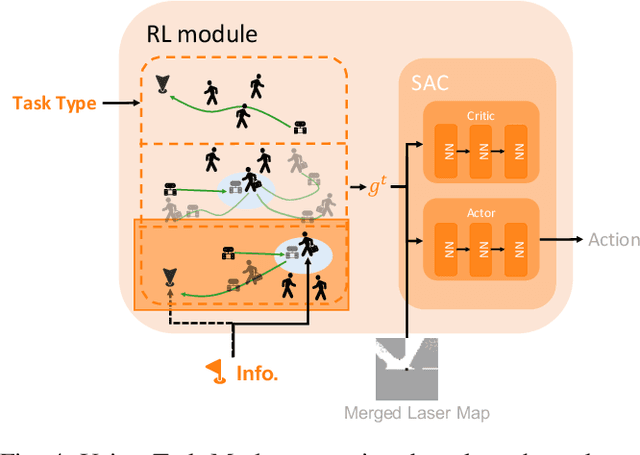
The socially-aware navigation system has evolved to adeptly avoid various obstacles while performing multiple tasks, such as point-to-point navigation, human-following, and -guiding. However, a prominent gap persists: in Human-Robot Interaction (HRI), the procedure of communicating commands to robots demands intricate mathematical formulations. Furthermore, the transition between tasks does not quite possess the intuitive control and user-centric interactivity that one would desire. In this work, we propose an LLM-driven interactive multimodal multitask robot navigation framework, termed LIM2N, to solve the above new challenge in the navigation field. We achieve this by first introducing a multimodal interaction framework where language and hand-drawn inputs can serve as navigation constraints and control objectives. Next, a reinforcement learning agent is built to handle multiple tasks with the received information. Crucially, LIM2N creates smooth cooperation among the reasoning of multimodal input, multitask planning, and adaptation and processing of the intelligent sensing modules in the complicated system. Extensive experiments are conducted in both simulation and the real world demonstrating that LIM2N has superior user needs understanding, alongside an enhanced interactive experience.
Cross-Utterance Conditioned VAE for Speech Generation
Sep 08, 2023



Speech synthesis systems powered by neural networks hold promise for multimedia production, but frequently face issues with producing expressive speech and seamless editing. In response, we present the Cross-Utterance Conditioned Variational Autoencoder speech synthesis (CUC-VAE S2) framework to enhance prosody and ensure natural speech generation. This framework leverages the powerful representational capabilities of pre-trained language models and the re-expression abilities of variational autoencoders (VAEs). The core component of the CUC-VAE S2 framework is the cross-utterance CVAE, which extracts acoustic, speaker, and textual features from surrounding sentences to generate context-sensitive prosodic features, more accurately emulating human prosody generation. We further propose two practical algorithms tailored for distinct speech synthesis applications: CUC-VAE TTS for text-to-speech and CUC-VAE SE for speech editing. The CUC-VAE TTS is a direct application of the framework, designed to generate audio with contextual prosody derived from surrounding texts. On the other hand, the CUC-VAE SE algorithm leverages real mel spectrogram sampling conditioned on contextual information, producing audio that closely mirrors real sound and thereby facilitating flexible speech editing based on text such as deletion, insertion, and replacement. Experimental results on the LibriTTS datasets demonstrate that our proposed models significantly enhance speech synthesis and editing, producing more natural and expressive speech.
Multi-Agent Feedback Enabled Neural Networks for Intelligent Communications
May 22, 2022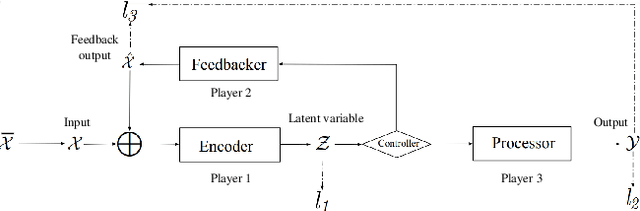
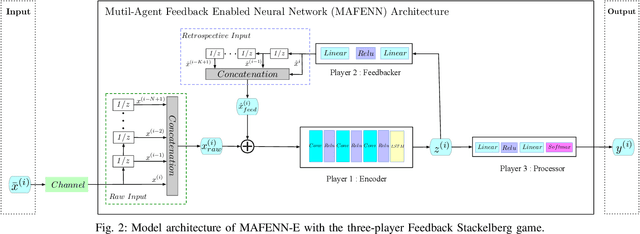
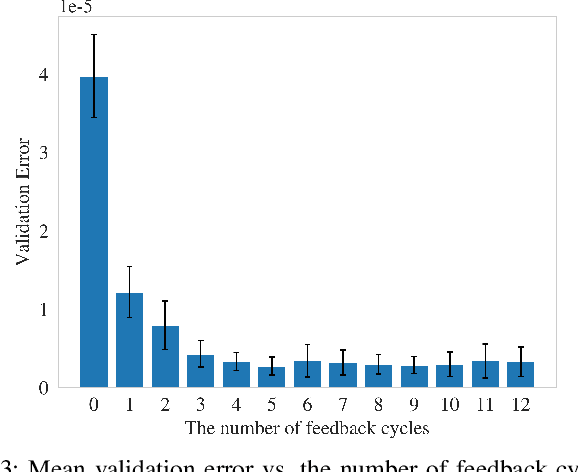
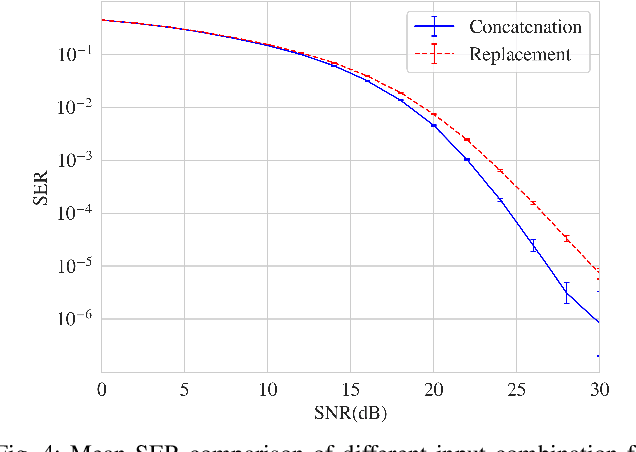
In the intelligent communication field, deep learning (DL) has attracted much attention due to its strong fitting ability and data-driven learning capability. Compared with the typical DL feedforward network structures, an enhancement structure with direct data feedback have been studied and proved to have better performance than the feedfoward networks. However, due to the above simple feedback methods lack sufficient analysis and learning ability on the feedback data, it is inadequate to deal with more complicated nonlinear systems and therefore the performance is limited for further improvement. In this paper, a novel multi-agent feedback enabled neural network (MAFENN) framework is proposed, which make the framework have stronger feedback learning capabilities and more intelligence on feature abstraction, denoising or generation, etc. Furthermore, the MAFENN framework is theoretically formulated into a three-player Feedback Stackelberg game, and the game is proved to converge to the Feedback Stackelberg equilibrium. The design of MAFENN framework and algorithm are dedicated to enhance the learning capability of the feedfoward DL networks or their variations with the simple data feedback. To verify the MAFENN framework's feasibility in wireless communications, a multi-agent MAFENN based equalizer (MAFENN-E) is developed for wireless fading channels with inter-symbol interference (ISI). Experimental results show that when the quadrature phase-shift keying (QPSK) modulation scheme is adopted, the SER performance of our proposed method outperforms that of the traditional equalizers by about 2 dB in linear channels. When in nonlinear channels, the SER performance of our proposed method outperforms that of either traditional or DL based equalizers more significantly, which shows the effectiveness and robustness of our proposal in the complex channel environment.
Cross-Utterance Conditioned VAE for Non-Autoregressive Text-to-Speech
May 09, 2022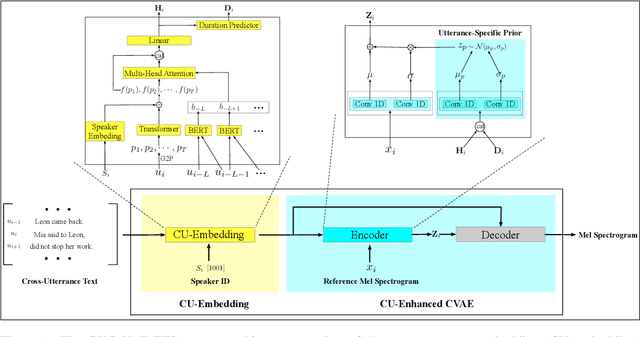
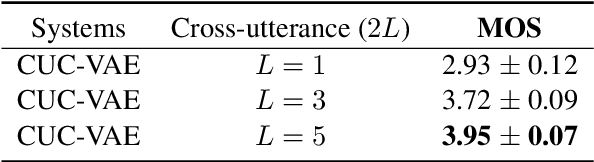

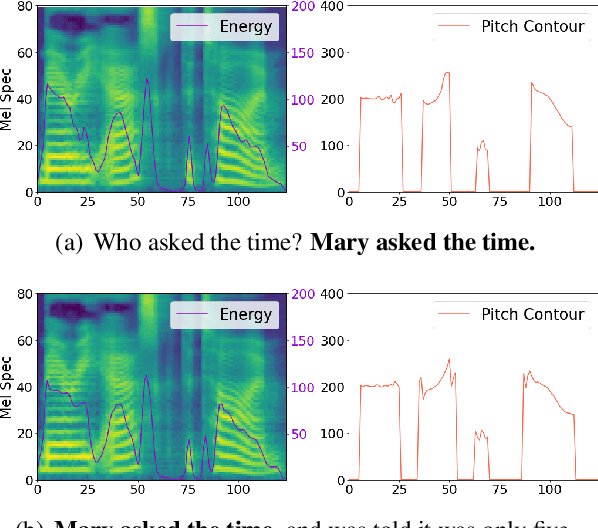
Modelling prosody variation is critical for synthesizing natural and expressive speech in end-to-end text-to-speech (TTS) systems. In this paper, a cross-utterance conditional VAE (CUC-VAE) is proposed to estimate a posterior probability distribution of the latent prosody features for each phoneme by conditioning on acoustic features, speaker information, and text features obtained from both past and future sentences. At inference time, instead of the standard Gaussian distribution used by VAE, CUC-VAE allows sampling from an utterance-specific prior distribution conditioned on cross-utterance information, which allows the prosody features generated by the TTS system to be related to the context and is more similar to how humans naturally produce prosody. The performance of CUC-VAE is evaluated via a qualitative listening test for naturalness, intelligibility and quantitative measurements, including word error rates and the standard deviation of prosody attributes. Experimental results on LJ-Speech and LibriTTS data show that the proposed CUC-VAE TTS system improves naturalness and prosody diversity with clear margins.
M2N: Mesh Movement Networks for PDE Solvers
Apr 24, 2022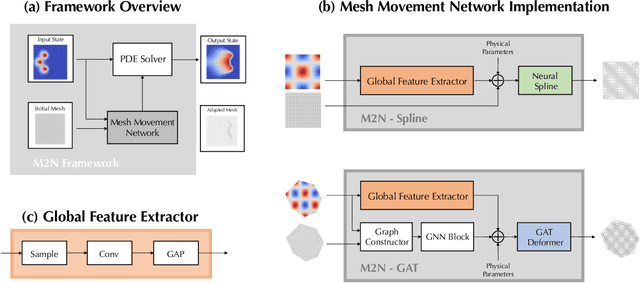
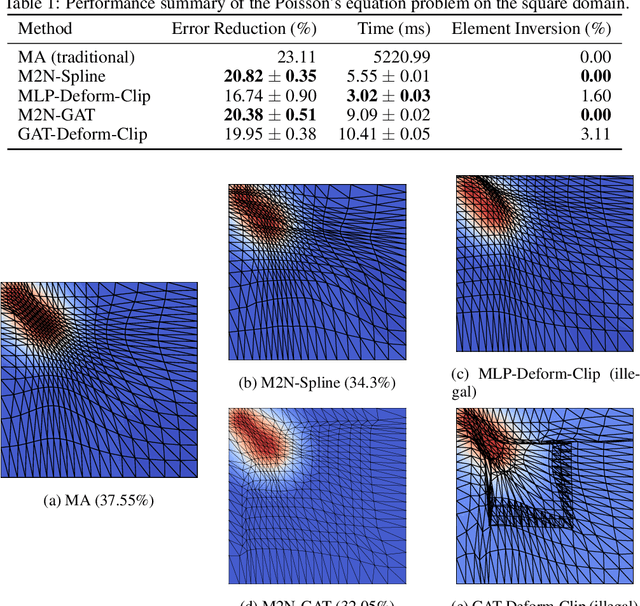
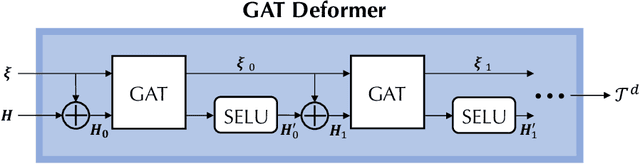
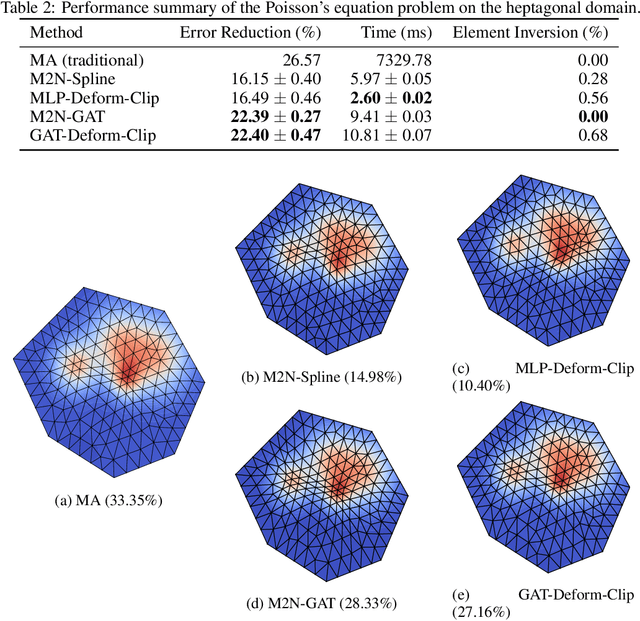
Mainstream numerical Partial Differential Equation (PDE) solvers require discretizing the physical domain using a mesh. Mesh movement methods aim to improve the accuracy of the numerical solution by increasing mesh resolution where the solution is not well-resolved, whilst reducing unnecessary resolution elsewhere. However, mesh movement methods, such as the Monge-Ampere method, require the solution of auxiliary equations, which can be extremely expensive especially when the mesh is adapted frequently. In this paper, we propose to our best knowledge the first learning-based end-to-end mesh movement framework for PDE solvers. Key requirements of learning-based mesh movement methods are alleviating mesh tangling, boundary consistency, and generalization to mesh with different resolutions. To achieve these goals, we introduce the neural spline model and the graph attention network (GAT) into our models respectively. While the Neural-Spline based model provides more flexibility for large deformation, the GAT based model can handle domains with more complicated shapes and is better at performing delicate local deformation. We validate our methods on stationary and time-dependent, linear and non-linear equations, as well as regularly and irregularly shaped domains. Compared to the traditional Monge-Ampere method, our approach can greatly accelerate the mesh adaptation process, whilst achieving comparable numerical error reduction.
Trust Region Policy Optimisation in Multi-Agent Reinforcement Learning
Sep 23, 2021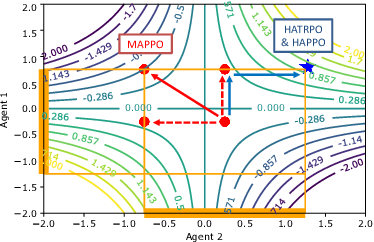
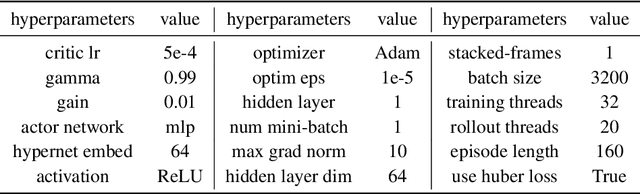
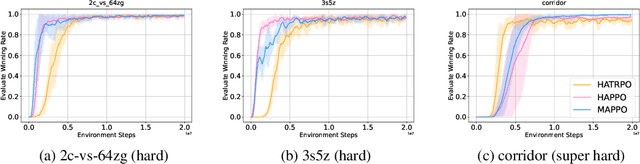

Trust region methods rigorously enabled reinforcement learning (RL) agents to learn monotonically improving policies, leading to superior performance on a variety of tasks. Unfortunately, when it comes to multi-agent reinforcement learning (MARL), the property of monotonic improvement may not simply apply; this is because agents, even in cooperative games, could have conflicting directions of policy updates. As a result, achieving a guaranteed improvement on the joint policy where each agent acts individually remains an open challenge. In this paper, we extend the theory of trust region learning to MARL. Central to our findings are the multi-agent advantage decomposition lemma and the sequential policy update scheme. Based on these, we develop Heterogeneous-Agent Trust Region Policy Optimisation (HATPRO) and Heterogeneous-Agent Proximal Policy Optimisation (HAPPO) algorithms. Unlike many existing MARL algorithms, HATRPO/HAPPO do not need agents to share parameters, nor do they need any restrictive assumptions on decomposibility of the joint value function. Most importantly, we justify in theory the monotonic improvement property of HATRPO/HAPPO. We evaluate the proposed methods on a series of Multi-Agent MuJoCo and StarCraftII tasks. Results show that HATRPO and HAPPO significantly outperform strong baselines such as IPPO, MAPPO and MADDPG on all tested tasks, therefore establishing a new state of the art.