 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Mesh Movement Networks
Jul 02, 2024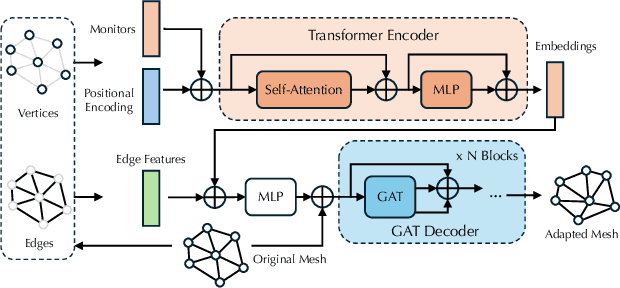



Solving complex Partial Differential Equations (PDEs) accurately and efficiently is an essential and challenging problem in all scientific and engineering disciplines. Mesh movement methods provide the capability to improve the accuracy of the numerical solution without increasing the overall mesh degree of freedom count. Conventional sophisticated mesh movement methods are extremely expensive and struggle to handle scenarios with complex boundary geometries. However, existing learning-based methods require re-training from scratch given a different PDE type or boundary geometry, which limits their applicability, and also often suffer from robustness issues in the form of inverted elements. In this paper, we introduce the Universal Mesh Movement Network (UM2N), which -- once trained -- can be applied in a non-intrusive, zero-shot manner to move meshes with different size distributions and structures, for solvers applicable to different PDE types and boundary geometries. UM2N consists of a Graph Transformer (GT) encoder for extracting features and a Graph Attention Network (GAT) based decoder for moving the mesh. We evaluate our method on advection and Navier-Stokes based examples, as well as a real-world tsunami simulation case. Our method outperforms existing learning-based mesh movement methods in terms of the benchmarks described above. In comparison to the conventional sophisticated Monge-Amp\`ere PDE-solver based method, our approach not only significantly accelerates mesh movement, but also proves effective in scenarios where the conventional method fails. Our project page is at https://erizmr.github.io/UM2N/.
Learning to Optimise Wind Farms with Graph Transformers
Nov 21, 2023This work proposes a novel data-driven model capable of providing accurate predictions for the power generation of all wind turbines in wind farms of arbitrary layout, yaw angle configurations and wind conditions. The proposed model functions by encoding a wind farm into a fully-connected graph and processing the graph representation through a graph transformer. The graph transformer surrogate is shown to generalise well and is able to uncover latent structural patterns within the graph representation of wind farms. It is demonstrated how the resulting surrogate model can be used to optimise yaw angle configurations using genetic algorithms, achieving similar levels of accuracy to industrially-standard wind farm simulation tools while only taking a fraction of the computational cost.
Accelerated wind farm yaw and layout optimisation with multi-fidelity deep transfer learning wake models
Mar 28, 2023



Wind farm modelling has been an area of rapidly increasing interest with numerous analytical as well as computational-based approaches developed to extend the margins of wind farm efficiency and maximise power production. In this work, we present the novel ML framework WakeNet, which can reproduce generalised 2D turbine wake velocity fields at hub-height over a wide range of yaw angles, wind speeds and turbulence intensities (TIs), with a mean accuracy of 99.8% compared to the solution calculated using the state-of-the-art wind farm modelling software FLORIS. As the generation of sufficient high-fidelity data for network training purposes can be cost-prohibitive, the utility of multi-fidelity transfer learning has also been investigated. Specifically, a network pre-trained on the low-fidelity Gaussian wake model is fine-tuned in order to obtain accurate wake results for the mid-fidelity Curl wake model. The robustness and overall performance of WakeNet on various wake steering control and layout optimisation scenarios has been validated through power-gain heatmaps, obtaining at least 90% of the power gained through optimisation performed with FLORIS directly. We also demonstrate that when utilising the Curl model, WakeNet is able to provide similar power gains to FLORIS, two orders of magnitude faster (e.g. 10 minutes vs 36 hours per optimisation case). The wake evaluation time of wakeNet when trained on a high-fidelity CFD dataset is expected to be similar, thus further increasing computational time gains. These promising results show that generalised wake modelling with ML tools can be accurate enough to contribute towards active yaw and layout optimisation, while producing realistic optimised configurations at a fraction of the computational cost, hence making it feasible to perform real-time active yaw control as well as robust optimisation under uncertainty.
End-to-end Wind Turbine Wake Modelling with Deep Graph Representation Learning
Dec 17, 2022

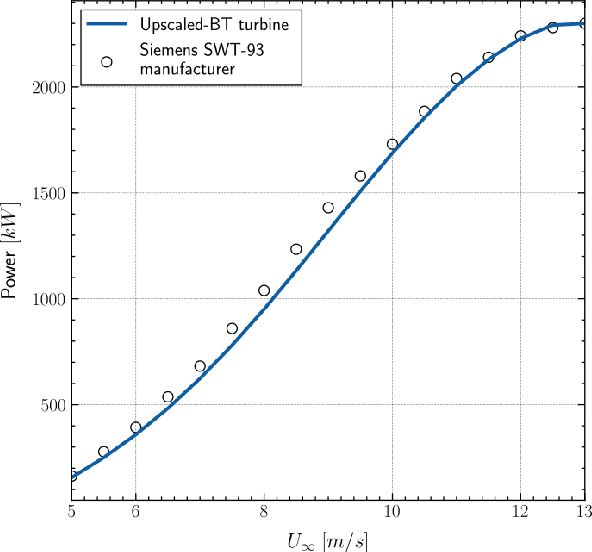

Wind turbine wake modelling is of crucial importance to accurate resource assessment, to layout optimisation, and to the operational control of wind farms. This work proposes a surrogate model for the representation of wind turbine wakes based on a state-of-the-art graph representation learning method termed a graph neural network. The proposed end-to-end deep learning model operates directly on unstructured meshes and has been validated against high-fidelity data, demonstrating its ability to rapidly make accurate 3D flow field predictions for various inlet conditions and turbine yaw angles. The specific graph neural network model employed here is shown to generalise well to unseen data and is less sensitive to over-smoothing compared to common graph neural networks. A case study based upon a real world wind farm further demonstrates the capability of the proposed approach to predict farm scale power generation. Moreover, the proposed graph neural network framework is flexible and highly generic and as formulated here can be applied to any steady state computational fluid dynamics simulations on unstructured meshes.
E2N: Error Estimation Networks for Goal-Oriented Mesh Adaptation
Jul 22, 2022


Given a partial differential equation (PDE), goal-oriented error estimation allows us to understand how errors in a diagnostic quantity of interest (QoI), or goal, occur and accumulate in a numerical approximation, for example using the finite element method. By decomposing the error estimates into contributions from individual elements, it is possible to formulate adaptation methods, which modify the mesh with the objective of minimising the resulting QoI error. However, the standard error estimate formulation involves the true adjoint solution, which is unknown in practice. As such, it is common practice to approximate it with an 'enriched' approximation (e.g. in a higher order space or on a refined mesh). Doing so generally results in a significant increase in computational cost, which can be a bottleneck compromising the competitiveness of (goal-oriented) adaptive simulations. The central idea of this paper is to develop a "data-driven" goal-oriented mesh adaptation approach through the selective replacement of the expensive error estimation step with an appropriately configured and trained neural network. In doing so, the error estimator may be obtained without even constructing the enriched spaces. An element-by-element construction is employed here, whereby local values of various parameters related to the mesh geometry and underlying problem physics are taken as inputs, and the corresponding contribution to the error estimator is taken as output. We demonstrate that this approach is able to obtain the same accuracy with a reduced computational cost, for adaptive mesh test cases related to flow around tidal turbines, which interact via their downstream wakes, and where the overall power output of the farm is taken as the QoI. Moreover, we demonstrate that the element-by-element approach implies reasonably low training costs.
Learning to Estimate and Refine Fluid Motion with Physical Dynamics
Jun 22, 2022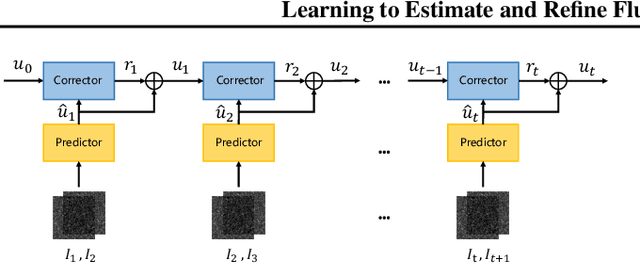
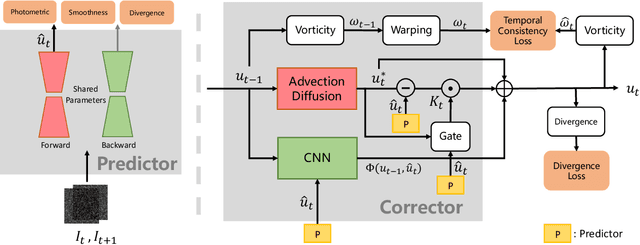
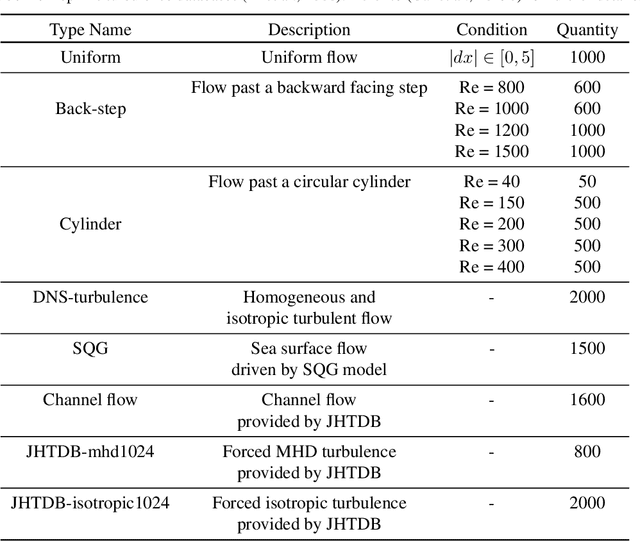
Extracting information on fluid motion directly from images is challenging. Fluid flow represents a complex dynamic system governed by the Navier-Stokes equations. General optical flow methods are typically designed for rigid body motion, and thus struggle if applied to fluid motion estimation directly. Further, optical flow methods only focus on two consecutive frames without utilising historical temporal information, while the fluid motion (velocity field) can be considered a continuous trajectory constrained by time-dependent partial differential equations (PDEs). This discrepancy has the potential to induce physically inconsistent estimations. Here we propose an unsupervised learning based prediction-correction scheme for fluid flow estimation. An estimate is first given by a PDE-constrained optical flow predictor, which is then refined by a physical based corrector. The proposed approach outperforms optical flow methods and shows competitive results compared to existing supervised learning based methods on a benchmark dataset. Furthermore, the proposed approach can generalize to complex real-world fluid scenarios where ground truth information is effectively unknowable. Finally, experiments demonstrate that the physical corrector can refine flow estimates by mimicking the operator splitting method commonly utilised in fluid dynamical simulation.
M2N: Mesh Movement Networks for PDE Solvers
Apr 24, 2022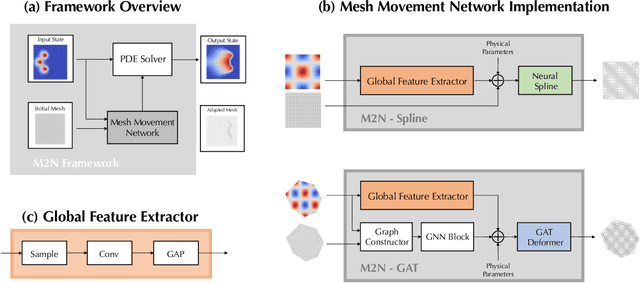
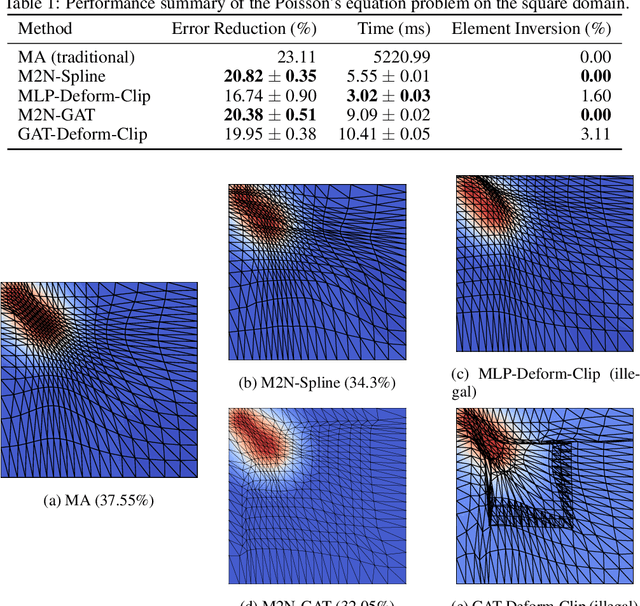
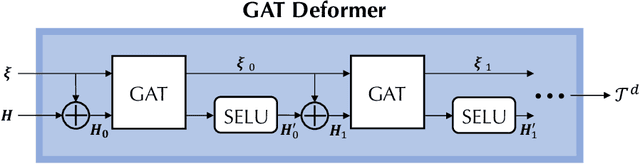
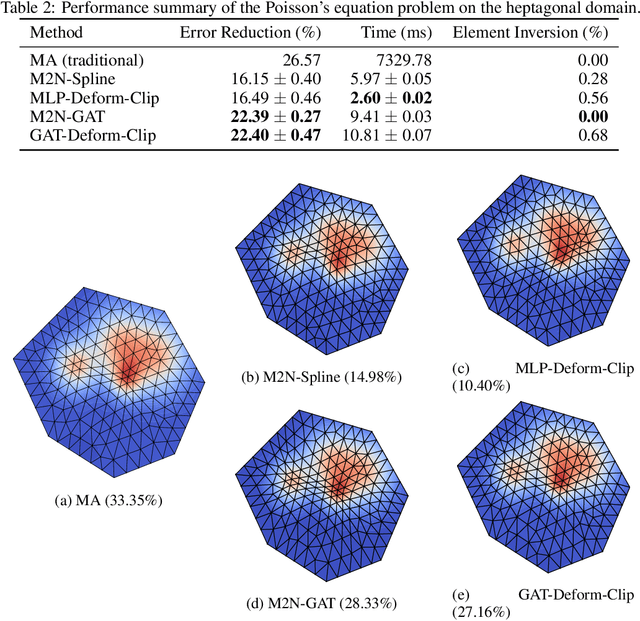
Mainstream numerical Partial Differential Equation (PDE) solvers require discretizing the physical domain using a mesh. Mesh movement methods aim to improve the accuracy of the numerical solution by increasing mesh resolution where the solution is not well-resolved, whilst reducing unnecessary resolution elsewhere. However, mesh movement methods, such as the Monge-Ampere method, require the solution of auxiliary equations, which can be extremely expensive especially when the mesh is adapted frequently. In this paper, we propose to our best knowledge the first learning-based end-to-end mesh movement framework for PDE solvers. Key requirements of learning-based mesh movement methods are alleviating mesh tangling, boundary consistency, and generalization to mesh with different resolutions. To achieve these goals, we introduce the neural spline model and the graph attention network (GAT) into our models respectively. While the Neural-Spline based model provides more flexibility for large deformation, the GAT based model can handle domains with more complicated shapes and is better at performing delicate local deformation. We validate our methods on stationary and time-dependent, linear and non-linear equations, as well as regularly and irregularly shaped domains. Compared to the traditional Monge-Ampere method, our approach can greatly accelerate the mesh adaptation process, whilst achieving comparable numerical error reduction.
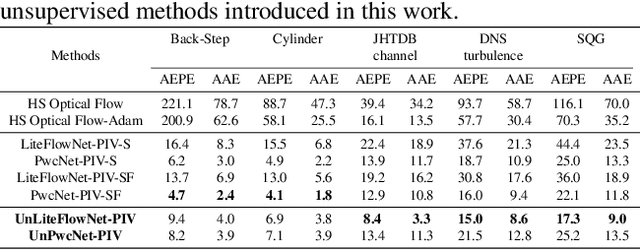
Unsupervised Learning of Particle Image Velocimetry
Jul 28, 2020
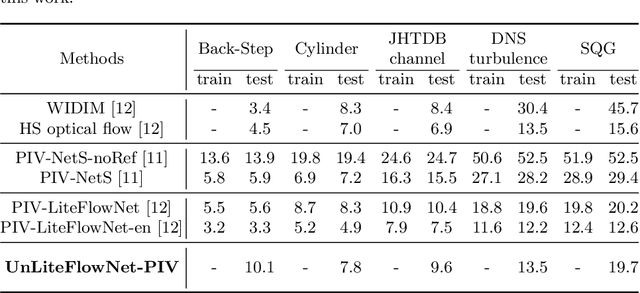


Particle Image Velocimetry (PIV) is a classical flow estimation problem which is widely considered and utilised, especially as a diagnostic tool in experimental fluid dynamics and the remote sensing of environmental flows. Recently, the development of deep learning based methods has inspired new approaches to tackle the PIV problem. These supervised learning based methods are driven by large volumes of data with ground truth training information. However, it is difficult to collect reliable ground truth data in large-scale, real-world scenarios. Although synthetic datasets can be used as alternatives, the gap between the training set-ups and real-world scenarios limits applicability. We present here what we believe to be the first work which takes an unsupervised learning based approach to tackle PIV problems. The proposed approach is inspired by classic optical flow methods. Instead of using ground truth data, we make use of photometric loss between two consecutive image frames, consistency loss in bidirectional flow estimates and spatial smoothness loss to construct the total unsupervised loss function. The approach shows significant potential and advantages for fluid flow estimation. Results presented here demonstrate that our method outputs competitive results compared with classical PIV methods as well as supervised learning based methods for a broad PIV dataset, and even outperforms these existing approaches in some difficult flow cases. Codes and trained models are available at https://github.com/erizmr/UnLiteFlowNet-PIV.