 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning
Jun 05, 2025The rich and multifaceted nature of human social interaction, encompassing multimodal cues, unobservable relations and mental states, and dynamical behavior, presents a formidable challenge for artificial intelligence. To advance research in this area, we introduce SIV-Bench, a novel video benchmark for rigorously evaluating the capabilities of Multimodal Large Language Models (MLLMs) across Social Scene Understanding (SSU), Social State Reasoning (SSR), and Social Dynamics Prediction (SDP). SIV-Bench features 2,792 video clips and 8,792 meticulously generated question-answer pairs derived from a human-LLM collaborative pipeline. It is originally collected from TikTok and YouTube, covering a wide range of video genres, presentation styles, and linguistic and cultural backgrounds. It also includes a dedicated setup for analyzing the impact of different textual cues-original on-screen text, added dialogue, or no text. Our comprehensive experiments on leading MLLMs reveal that while models adeptly handle SSU, they significantly struggle with SSR and SDP, where Relation Inference (RI) is an acute bottleneck, as further examined in our analysis. Our study also confirms the critical role of transcribed dialogue in aiding comprehension of complex social interactions. By systematically identifying current MLLMs' strengths and limitations, SIV-Bench offers crucial insights to steer the development of more socially intelligent AI. The dataset and code are available at https://kfq20.github.io/sivbench/.
Language and Sketching: An LLM-driven Interactive Multimodal Multitask Robot Navigation Framework
Nov 14, 2023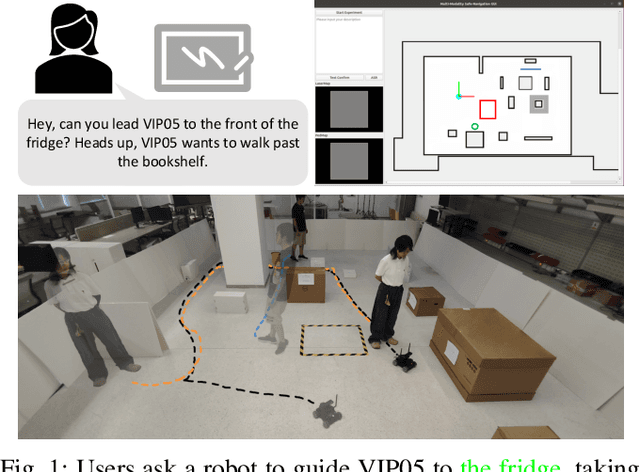
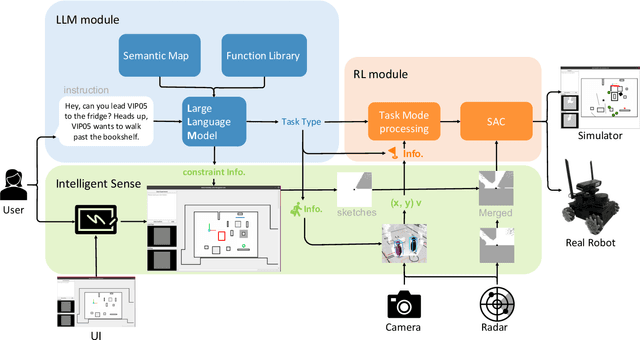
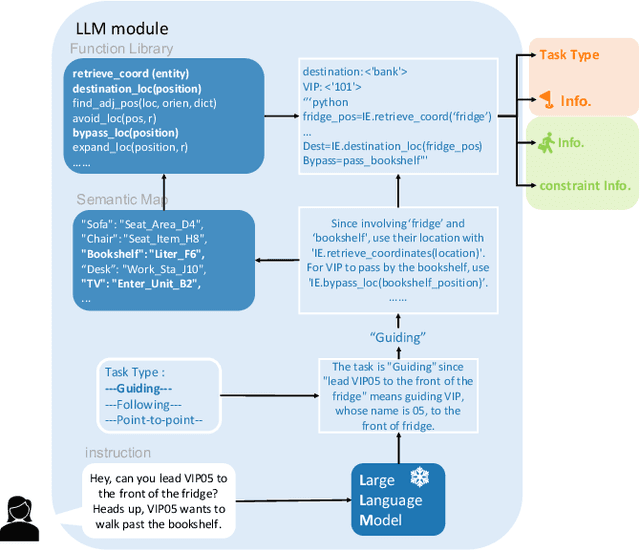
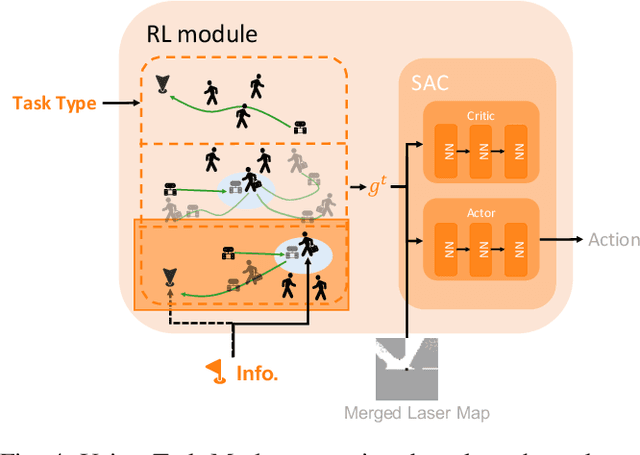
The socially-aware navigation system has evolved to adeptly avoid various obstacles while performing multiple tasks, such as point-to-point navigation, human-following, and -guiding. However, a prominent gap persists: in Human-Robot Interaction (HRI), the procedure of communicating commands to robots demands intricate mathematical formulations. Furthermore, the transition between tasks does not quite possess the intuitive control and user-centric interactivity that one would desire. In this work, we propose an LLM-driven interactive multimodal multitask robot navigation framework, termed LIM2N, to solve the above new challenge in the navigation field. We achieve this by first introducing a multimodal interaction framework where language and hand-drawn inputs can serve as navigation constraints and control objectives. Next, a reinforcement learning agent is built to handle multiple tasks with the received information. Crucially, LIM2N creates smooth cooperation among the reasoning of multimodal input, multitask planning, and adaptation and processing of the intelligent sensing modules in the complicated system. Extensive experiments are conducted in both simulation and the real world demonstrating that LIM2N has superior user needs understanding, alongside an enhanced interactive experience.
Cross-Utterance Conditioned VAE for Speech Generation
Sep 08, 2023



Speech synthesis systems powered by neural networks hold promise for multimedia production, but frequently face issues with producing expressive speech and seamless editing. In response, we present the Cross-Utterance Conditioned Variational Autoencoder speech synthesis (CUC-VAE S2) framework to enhance prosody and ensure natural speech generation. This framework leverages the powerful representational capabilities of pre-trained language models and the re-expression abilities of variational autoencoders (VAEs). The core component of the CUC-VAE S2 framework is the cross-utterance CVAE, which extracts acoustic, speaker, and textual features from surrounding sentences to generate context-sensitive prosodic features, more accurately emulating human prosody generation. We further propose two practical algorithms tailored for distinct speech synthesis applications: CUC-VAE TTS for text-to-speech and CUC-VAE SE for speech editing. The CUC-VAE TTS is a direct application of the framework, designed to generate audio with contextual prosody derived from surrounding texts. On the other hand, the CUC-VAE SE algorithm leverages real mel spectrogram sampling conditioned on contextual information, producing audio that closely mirrors real sound and thereby facilitating flexible speech editing based on text such as deletion, insertion, and replacement. Experimental results on the LibriTTS datasets demonstrate that our proposed models significantly enhance speech synthesis and editing, producing more natural and expressive speech.
Cross-Utterance Conditioned VAE for Non-Autoregressive Text-to-Speech
May 09, 2022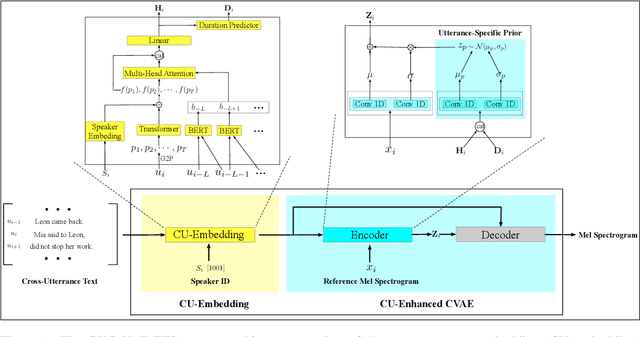
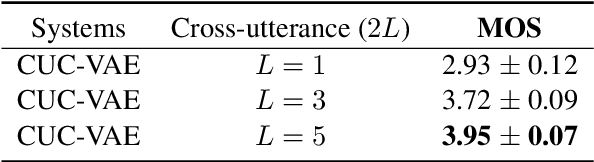

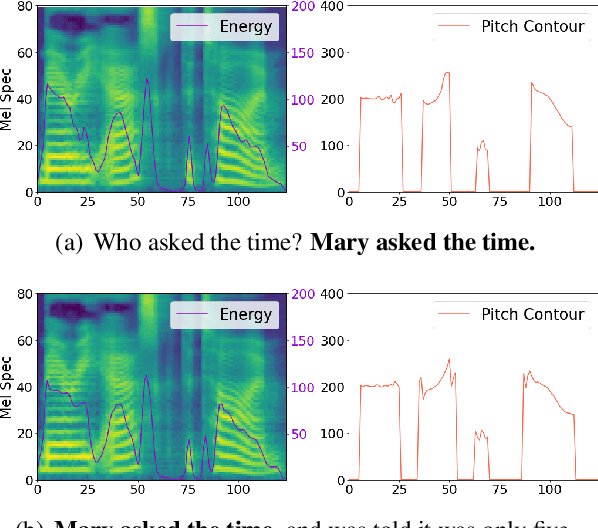
Modelling prosody variation is critical for synthesizing natural and expressive speech in end-to-end text-to-speech (TTS) systems. In this paper, a cross-utterance conditional VAE (CUC-VAE) is proposed to estimate a posterior probability distribution of the latent prosody features for each phoneme by conditioning on acoustic features, speaker information, and text features obtained from both past and future sentences. At inference time, instead of the standard Gaussian distribution used by VAE, CUC-VAE allows sampling from an utterance-specific prior distribution conditioned on cross-utterance information, which allows the prosody features generated by the TTS system to be related to the context and is more similar to how humans naturally produce prosody. The performance of CUC-VAE is evaluated via a qualitative listening test for naturalness, intelligibility and quantitative measurements, including word error rates and the standard deviation of prosody attributes. Experimental results on LJ-Speech and LibriTTS data show that the proposed CUC-VAE TTS system improves naturalness and prosody diversity with clear margins.