 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning
Jun 24, 2025Large language models (LLMs) have achieved remarkable progress in reasoning tasks, yet the optimal integration of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) remains a fundamental challenge. Through comprehensive analysis of token distributions, learning dynamics, and integration mechanisms from entropy-based perspectives, we reveal key differences between these paradigms: SFT induces coarse-grained global changes to LLM policy distributions, while RL performs fine-grained selective optimizations, with entropy serving as a critical indicator of training effectiveness. Building on these observations, we propose Supervised Reinforcement Fine-Tuning (SRFT), a single-stage method that unifies both fine-tuning paradigms through entropy-aware weighting mechanisms. Our approach simultaneously applies SFT and RL to directly optimize the LLM using demonstrations and self-exploration rollouts rather than through two-stage sequential methods. Extensive experiments show that SRFT achieves 59.1% average accuracy, outperforming zero-RL methods by 9.0% on five mathematical reasoning benchmarks and 10.9% on three out-of-distribution benchmarks.
Audio Turing Test: Benchmarking the Human-likeness of Large Language Model-based Text-to-Speech Systems in Chinese
May 16, 2025Recent advances in large language models (LLMs) have significantly improved text-to-speech (TTS) systems, enhancing control over speech style, naturalness, and emotional expression, which brings TTS Systems closer to human-level performance. Although the Mean Opinion Score (MOS) remains the standard for TTS System evaluation, it suffers from subjectivity, environmental inconsistencies, and limited interpretability. Existing evaluation datasets also lack a multi-dimensional design, often neglecting factors such as speaking styles, context diversity, and trap utterances, which is particularly evident in Chinese TTS evaluation. To address these challenges, we introduce the Audio Turing Test (ATT), a multi-dimensional Chinese corpus dataset ATT-Corpus paired with a simple, Turing-Test-inspired evaluation protocol. Instead of relying on complex MOS scales or direct model comparisons, ATT asks evaluators to judge whether a voice sounds human. This simplification reduces rating bias and improves evaluation robustness. To further support rapid model development, we also finetune Qwen2-Audio-Instruct with human judgment data as Auto-ATT for automatic evaluation. Experimental results show that ATT effectively differentiates models across specific capability dimensions using its multi-dimensional design. Auto-ATT also demonstrates strong alignment with human evaluations, confirming its value as a fast and reliable assessment tool. The white-box ATT-Corpus and Auto-ATT can be found in ATT Hugging Face Collection (https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4).
PMAT: Optimizing Action Generation Order in Multi-Agent Reinforcement Learning
Feb 23, 2025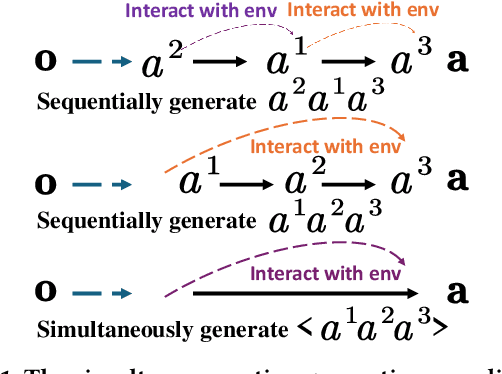
Multi-agent reinforcement learning (MARL) faces challenges in coordinating agents due to complex interdependencies within multi-agent systems. Most MARL algorithms use the simultaneous decision-making paradigm but ignore the action-level dependencies among agents, which reduces coordination efficiency. In contrast, the sequential decision-making paradigm provides finer-grained supervision for agent decision order, presenting the potential for handling dependencies via better decision order management. However, determining the optimal decision order remains a challenge. In this paper, we introduce Action Generation with Plackett-Luce Sampling (AGPS), a novel mechanism for agent decision order optimization. We model the order determination task as a Plackett-Luce sampling process to address issues such as ranking instability and vanishing gradient during the network training process. AGPS realizes credit-based decision order determination by establishing a bridge between the significance of agents' local observations and their decision credits, thus facilitating order optimization and dependency management. Integrating AGPS with the Multi-Agent Transformer, we propose the Prioritized Multi-Agent Transformer (PMAT), a sequential decision-making MARL algorithm with decision order optimization. Experiments on benchmarks including StarCraft II Multi-Agent Challenge, Google Research Football, and Multi-Agent MuJoCo show that PMAT outperforms state-of-the-art algorithms, greatly enhancing coordination efficiency.
Leveraging Dual Process Theory in Language Agent Framework for Real-time Simultaneous Human-AI Collaboration
Feb 17, 2025Agents built on large language models (LLMs) have excelled in turn-by-turn human-AI collaboration but struggle with simultaneous tasks requiring real-time interaction. Latency issues and the challenge of inferring variable human strategies hinder their ability to make autonomous decisions without explicit instructions. Through experiments with current independent System 1 and System 2 methods, we validate the necessity of using Dual Process Theory (DPT) in real-time tasks. We propose DPT-Agent, a novel language agent framework that integrates System 1 and System 2 for efficient real-time simultaneous human-AI collaboration. DPT-Agent's System 1 uses a Finite-state Machine (FSM) and code-as-policy for fast, intuitive, and controllable decision-making. DPT-Agent's System 2 integrates Theory of Mind (ToM) and asynchronous reflection to infer human intentions and perform reasoning-based autonomous decisions. We demonstrate the effectiveness of DPT-Agent through further experiments with rule-based agents and human collaborators, showing significant improvements over mainstream LLM-based frameworks. To the best of our knowledge, DPT-Agent is the first language agent framework that achieves successful real-time simultaneous human-AI collaboration autonomously. Code of DPT-Agent can be found in https://github.com/sjtu-marl/DPT-Agent.
HammerBench: Fine-Grained Function-Calling Evaluation in Real Mobile Device Scenarios
Dec 21, 2024



Evaluating the capabilities of large language models (LLMs) in human-LLM interactions remains challenging due to the inherent complexity and openness of dialogue processes. This paper introduces HammerBench, a novel benchmarking framework designed to assess the function-calling ability of LLMs more effectively in such interactions. We model a wide range of real-world user scenarios on mobile devices, encompassing imperfect instructions, diverse question-answer trajectories, intent/argument shifts, and the use of external individual information through pronouns. To construct the corresponding datasets, we propose a comprehensive pipeline that involves LLM-generated data and multiple rounds of human validation, ensuring high data quality. Additionally, we decompose the conversations into function-calling snapshots, enabling a fine-grained evaluation of each turn. We evaluate several popular LLMs using HammerBench and highlight different performance aspects. Our empirical findings reveal that errors in parameter naming constitute the primary factor behind conversation failures across different data types.
Computing Ex Ante Equilibrium in Heterogeneous Zero-Sum Team Games
Oct 02, 2024



The ex ante equilibrium for two-team zero-sum games, where agents within each team collaborate to compete against the opposing team, is known to be the best a team can do for coordination. Many existing works on ex ante equilibrium solutions are aiming to extend the scope of ex ante equilibrium solving to large-scale team games based on Policy Space Response Oracle (PSRO). However, the joint team policy space constructed by the most prominent method, Team PSRO, cannot cover the entire team policy space in heterogeneous team games where teammates play distinct roles. Such insufficient policy expressiveness causes Team PSRO to be trapped into a sub-optimal ex ante equilibrium with significantly higher exploitability and never converges to the global ex ante equilibrium. To find the global ex ante equilibrium without introducing additional computational complexity, we first parameterize heterogeneous policies for teammates, and we prove that optimizing the heterogeneous teammates' policies sequentially can guarantee a monotonic improvement in team rewards. We further propose Heterogeneous-PSRO (H-PSRO), a novel framework for heterogeneous team games, which integrates the sequential correlation mechanism into the PSRO framework and serves as the first PSRO framework for heterogeneous team games. We prove that H-PSRO achieves lower exploitability than Team PSRO in heterogeneous team games. Empirically, H-PSRO achieves convergence in matrix heterogeneous games that are unsolvable by non-heterogeneous baselines. Further experiments reveal that H-PSRO outperforms non-heterogeneous baselines in both heterogeneous team games and homogeneous settings.
Mutual Theory of Mind in Human-AI Collaboration: An Empirical Study with LLM-driven AI Agents in a Real-time Shared Workspace Task
Sep 13, 2024Theory of Mind (ToM) significantly impacts human collaboration and communication as a crucial capability to understand others. When AI agents with ToM capability collaborate with humans, Mutual Theory of Mind (MToM) arises in such human-AI teams (HATs). The MToM process, which involves interactive communication and ToM-based strategy adjustment, affects the team's performance and collaboration process. To explore the MToM process, we conducted a mixed-design experiment using a large language model-driven AI agent with ToM and communication modules in a real-time shared-workspace task. We find that the agent's ToM capability does not significantly impact team performance but enhances human understanding of the agent and the feeling of being understood. Most participants in our study believe verbal communication increases human burden, and the results show that bidirectional communication leads to lower HAT performance. We discuss the results' implications for designing AI agents that collaborate with humans in real-time shared workspace tasks.
Quantifying Zero-shot Coordination Capability with Behavior Preferring Partners
Oct 08, 2023



Zero-shot coordination (ZSC) is a new challenge focusing on generalizing learned coordination skills to unseen partners. Existing methods train the ego agent with partners from pre-trained or evolving populations. The agent's ZSC capability is typically evaluated with a few evaluation partners, including human and agent, and reported by mean returns. Current evaluation methods for ZSC capability still need to improve in constructing diverse evaluation partners and comprehensively measuring the ZSC capability. We aim to create a reliable, comprehensive, and efficient evaluation method for ZSC capability. We formally define the ideal 'diversity-complete' evaluation partners and propose the best response (BR) diversity, which is the population diversity of the BRs to the partners, to approximate the ideal evaluation partners. We propose an evaluation workflow including 'diversity-complete' evaluation partners construction and a multi-dimensional metric, the Best Response Proximity (BR-Prox) metric. BR-Prox quantifies the ZSC capability as the performance similarity to each evaluation partner's approximate best response, demonstrating generalization capability and improvement potential. We re-evaluate strong ZSC methods in the Overcooked environment using the proposed evaluation workflow. Surprisingly, the results in some of the most used layouts fail to distinguish the performance of different ZSC methods. Moreover, the evaluated ZSC methods must produce more diverse and high-performing training partners. Our proposed evaluation workflow calls for a change in how we efficiently evaluate ZSC methods as a supplement to human evaluation.
Order Matters: Agent-by-agent Policy Optimization
Feb 26, 2023



While multi-agent trust region algorithms have achieved great success empirically in solving coordination tasks, most of them, however, suffer from a non-stationarity problem since agents update their policies simultaneously. In contrast, a sequential scheme that updates policies agent-by-agent provides another perspective and shows strong performance. However, sample inefficiency and lack of monotonic improvement guarantees for each agent are still the two significant challenges for the sequential scheme. In this paper, we propose the \textbf{A}gent-by-\textbf{a}gent \textbf{P}olicy \textbf{O}ptimization (A2PO) algorithm to improve the sample efficiency and retain the guarantees of monotonic improvement for each agent during training. We justify the tightness of the monotonic improvement bound compared with other trust region algorithms. From the perspective of sequentially updating agents, we further consider the effect of agent updating order and extend the theory of non-stationarity into the sequential update scheme. To evaluate A2PO, we conduct a comprehensive empirical study on four benchmarks: StarCraftII, Multi-agent MuJoCo, Multi-agent Particle Environment, and Google Research Football full game scenarios. A2PO consistently outperforms strong baselines.
Model-based Multi-agent Reinforcement Learning: Recent Progress and Prospects
Mar 20, 2022
Significant advances have recently been achieved in Multi-Agent Reinforcement Learning (MARL) which tackles sequential decision-making problems involving multiple participants. However, MARL requires a tremendous number of samples for effective training. On the other hand, model-based methods have been shown to achieve provable advantages of sample efficiency. However, the attempts of model-based methods to MARL have just started very recently. This paper presents a review of the existing research on model-based MARL, including theoretical analyses, algorithms, and applications, and analyzes the advantages and potential of model-based MARL. Specifically, we provide a detailed taxonomy of the algorithms and point out the pros and cons for each algorithm according to the challenges inherent to multi-agent scenarios. We also outline promising directions for future development of this field.