 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Milestone Reward for GUI Agents
Feb 12, 2026Reinforcement Learning (RL) has emerged as a mainstream paradigm for training Mobile GUI Agents, yet it struggles with the temporal credit assignment problem inherent in long-horizon tasks. A primary challenge lies in the trade-off between reward fidelity and density: outcome reward offers high fidelity but suffers from signal sparsity, while process reward provides dense supervision but remains prone to bias and reward hacking. To resolve this conflict, we propose the Adaptive Milestone Reward (ADMIRE) mechanism. ADMIRE constructs a verifiable, adaptive reward system by anchoring trajectory to milestones, which are dynamically distilled from successful explorations. Crucially, ADMIRE integrates an asymmetric credit assignment strategy that denoises successful trajectories and scaffolds failed trajectories. Extensive experiments demonstrate that ADMIRE consistently yields over 10% absolute improvement in success rate across different base models on AndroidWorld. Moreover, the method exhibits robust generalizability, achieving strong performance across diverse RL algorithms and heterogeneous environments such as web navigation and embodied tasks.
HammerBench: Fine-Grained Function-Calling Evaluation in Real Mobile Device Scenarios
Dec 21, 2024



Evaluating the capabilities of large language models (LLMs) in human-LLM interactions remains challenging due to the inherent complexity and openness of dialogue processes. This paper introduces HammerBench, a novel benchmarking framework designed to assess the function-calling ability of LLMs more effectively in such interactions. We model a wide range of real-world user scenarios on mobile devices, encompassing imperfect instructions, diverse question-answer trajectories, intent/argument shifts, and the use of external individual information through pronouns. To construct the corresponding datasets, we propose a comprehensive pipeline that involves LLM-generated data and multiple rounds of human validation, ensuring high data quality. Additionally, we decompose the conversations into function-calling snapshots, enabling a fine-grained evaluation of each turn. We evaluate several popular LLMs using HammerBench and highlight different performance aspects. Our empirical findings reveal that errors in parameter naming constitute the primary factor behind conversation failures across different data types.
Hammer: Robust Function-Calling for On-Device Language Models via Function Masking
Oct 06, 2024
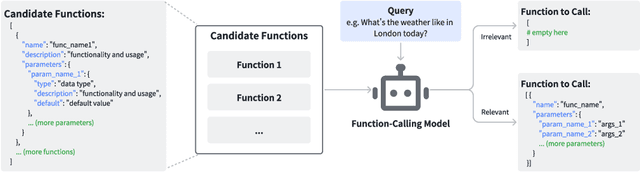


Large language models have demonstrated impressive value in performing as autonomous agents when equipped with external tools and API calls. Nonetheless, effectively harnessing their potential for executing complex tasks crucially relies on enhancements in their function calling capabilities. This paper identifies a critical gap in existing function calling models, where performance varies significantly across benchmarks, often due to being misled by specific naming conventions. To address such an issue, we introduce Hammer, a novel family of foundation models specifically engineered for on-device function calling. Hammer employs an augmented dataset that enhances models' sensitivity to irrelevant functions and incorporates function masking techniques to minimize misleading. Our empirical evaluations reveal that Hammer not only outperforms larger models but also demonstrates robust generalization across diverse benchmarks, achieving sota results. Our open source contributions include a specialized dataset for irrelevance detection, a tuning framework for enhanced generalization, and the Hammer models, establishing a new standard for function calling performance.
A Framework to Implement 1+N Multi-task Fine-tuning Pattern in LLMs Using the CGC-LORA Algorithm
Jan 22, 2024With the productive evolution of large language models (LLMs) in the field of natural language processing (NLP), tons of effort has been made to effectively fine-tune common pre-trained LLMs to fulfill a variety of tasks in one or multiple specific domain. In practice, there are two prevailing ways, in which the adaptation can be achieved: (i) Multiple Independent Models: Pre-trained LLMs are fine-tuned a few times independently using the corresponding training samples from each task. (ii) An Integrated Model: Samples from all tasks are employed to fine-tune a pre-trianed LLM unitedly. To address the high computing cost and seesawing issue simultaneously, we propose a unified framework that implements a 1 + N mutli-task fine-tuning pattern in LLMs using a novel Customized Gate Control (CGC) Low-rank Adaptation (LoRA) algorithm. Our work aims to take an advantage of both MTL (i.e., CGC) and PEFT (i.e., LoRA) scheme. For a given cluster of tasks, we design an innovative layer that contains two types of experts as additional trainable parameters to make LoRA be compatible with MTL. To comprehensively evaluate the proposed framework, we conduct well-designed experiments on two public datasets. The experimental results demonstrate that the unified framework with CGC-LoRA modules achieves higher evaluation scores than all benchmarks on both two datasets.