 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHammerBench: Fine-Grained Function-Calling Evaluation in Real Mobile Device Scenarios
Dec 21, 2024



Evaluating the capabilities of large language models (LLMs) in human-LLM interactions remains challenging due to the inherent complexity and openness of dialogue processes. This paper introduces HammerBench, a novel benchmarking framework designed to assess the function-calling ability of LLMs more effectively in such interactions. We model a wide range of real-world user scenarios on mobile devices, encompassing imperfect instructions, diverse question-answer trajectories, intent/argument shifts, and the use of external individual information through pronouns. To construct the corresponding datasets, we propose a comprehensive pipeline that involves LLM-generated data and multiple rounds of human validation, ensuring high data quality. Additionally, we decompose the conversations into function-calling snapshots, enabling a fine-grained evaluation of each turn. We evaluate several popular LLMs using HammerBench and highlight different performance aspects. Our empirical findings reveal that errors in parameter naming constitute the primary factor behind conversation failures across different data types.
Hammer: Robust Function-Calling for On-Device Language Models via Function Masking
Oct 06, 2024
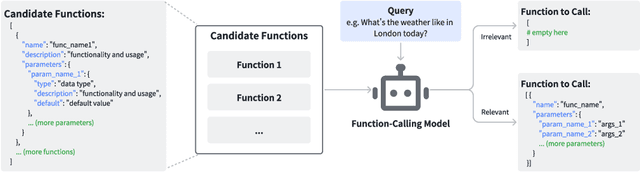


Large language models have demonstrated impressive value in performing as autonomous agents when equipped with external tools and API calls. Nonetheless, effectively harnessing their potential for executing complex tasks crucially relies on enhancements in their function calling capabilities. This paper identifies a critical gap in existing function calling models, where performance varies significantly across benchmarks, often due to being misled by specific naming conventions. To address such an issue, we introduce Hammer, a novel family of foundation models specifically engineered for on-device function calling. Hammer employs an augmented dataset that enhances models' sensitivity to irrelevant functions and incorporates function masking techniques to minimize misleading. Our empirical evaluations reveal that Hammer not only outperforms larger models but also demonstrates robust generalization across diverse benchmarks, achieving sota results. Our open source contributions include a specialized dataset for irrelevance detection, a tuning framework for enhanced generalization, and the Hammer models, establishing a new standard for function calling performance.