 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePelican-Unified 1.0: A Unified Embodied Intelligence Model for Understanding, Reasoning, Imagination and Action
May 14, 2026We present Pelican-Unified 1.0, the first embodied foundation model trained according to the principle of unification. Pelican-Unified 1.0 uses a single VLM as a unified understanding module, mapping scenes, instructions, visual contexts, and action histories into a shared semantic space. The same VLM also serves as a unified reasoning module, autoregressively producing task-, action-, and future-oriented chains of thought in a single forward pass and projecting the final hidden state into a dense latent variable. A Unified Future Generator (UFG) then conditions on this latent variable and jointly generates future videos and future actions through two modality-specific output heads within the same denoising process. The language, video, and action losses are all backpropagated into the shared representation, enabling the model to jointly optimize understanding, reasoning, imagination, and action during training, rather than training three isolated expert systems. Experiments demonstrate that unification does not imply compromise. With a single checkpoint, Pelican-Unified 1.0 achieves strong performance across all three capabilities: 64.7 on eight VLM benchmarks, the best among comparable-scale models; 66.03 on WorldArena, ranking first; and 93.5 on RoboTwin, the second-best average among compared action methods. These results show that the unified paradigm succeeds in preserving specialist strength while bringing understanding, reasoning, imagination, and action into one model.
Position: Agentic AI System Is a Foreseeable Pathway to AGI
May 13, 2026Is monolithic scaling the only path to AGI? This paper challenges the dogma that purely scaling a single model is sufficient to achieve Artificial General Intelligence. Instead, we identify Agentic AI as a necessary paradigm for mastering the complex, heterogeneous distribution of real-world tasks. Through rigorous theoretical derivations, we contrast the optimization constraints of monolithic learners against the efficiency of Agentic systems, progressing from simple routing mechanisms to general Directed Acyclic Graph (DAG) topologies. We demonstrate that Agentic AI achieves exponentially superior generalization and sample efficiency. Finally, we discuss the connection to Mixture-of-Experts, reinterpret the instability of current multi-agent frameworks, and call for greater research focus on Agentic AI.
A2Eval: Agentic and Automated Evaluation for Embodied Brain
Feb 02, 2026Current embodied VLM evaluation relies on static, expert-defined, manually annotated benchmarks that exhibit severe redundancy and coverage imbalance. This labor intensive paradigm drains computational and annotation resources, inflates costs, and distorts model rankings, ultimately stifling iterative development. To address this, we propose Agentic Automatic Evaluation (A2Eval), the first agentic framework that automates benchmark curation and evaluation through two collaborative agents. The Data Agent autonomously induces capability dimensions and assembles a balanced, compact evaluation suite, while the Eval Agent synthesizes and validates executable evaluation pipelines, enabling fully autonomous, high-fidelity assessment. Evaluated across 10 benchmarks and 13 models, A2Eval compresses evaluation suites by 85%, reduces overall computational costs by 77%, and delivers a 4.6x speedup while preserving evaluation quality. Crucially, A2Eval corrects systematic ranking biases, improves human alignment to Spearman's rho=0.85, and maintains high ranking fidelity (Kendall's tau=0.81), establishing a new standard for high-fidelity, low-cost embodied assessment. Our code and data will be public soon.
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
Jan 06, 2026The hallmark of human intelligence is the ability to master new skills through Constructive Episodic Simulation-retrieving past experiences to synthesize solutions for novel tasks. While Large Language Models possess strong reasoning capabilities, they struggle to emulate this self-evolution: fine-tuning is computationally expensive and prone to catastrophic forgetting, while existing memory-based methods rely on passive semantic matching that often retrieves noise. To address these challenges, we propose MemRL, a framework that enables agents to self-evolve via non-parametric reinforcement learning on episodic memory. MemRL explicitly separates the stable reasoning of a frozen LLM from the plastic, evolving memory. Unlike traditional methods, MemRL employs a Two-Phase Retrieval mechanism that filters candidates by semantic relevance and then selects them based on learned Q-values (utility). These utilities are continuously refined via environmental feedback in an trial-and-error manner, allowing the agent to distinguish high-value strategies from similar noise. Extensive experiments on HLE, BigCodeBench, ALFWorld, and Lifelong Agent Bench demonstrate that MemRL significantly outperforms state-of-the-art baselines. Our analysis experiments confirm that MemRL effectively reconciles the stability-plasticity dilemma, enabling continuous runtime improvement without weight updates.
MARFT: Multi-Agent Reinforcement Fine-Tuning
Apr 24, 2025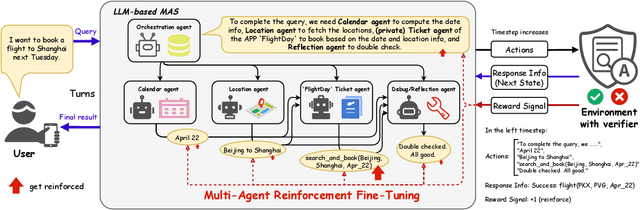


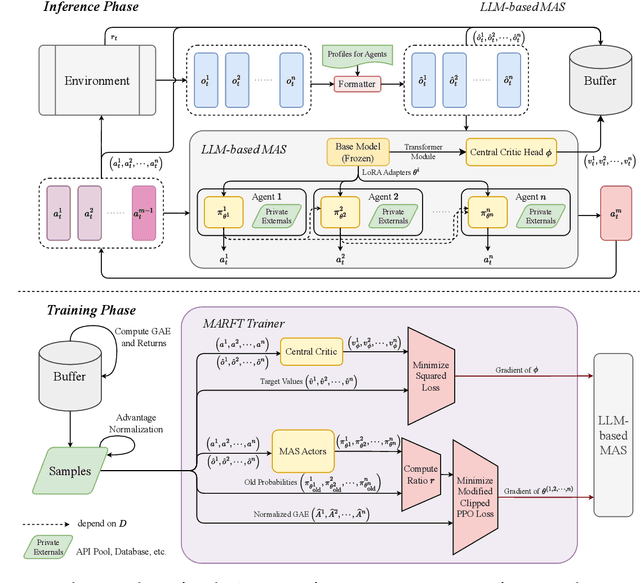
LLM-based Multi-Agent Systems have demonstrated remarkable capabilities in addressing complex, agentic tasks requiring multifaceted reasoning and collaboration, from generating high-quality presentation slides to conducting sophisticated scientific research. Meanwhile, RL has been widely recognized for its effectiveness in enhancing agent intelligence, but limited research has investigated the fine-tuning of LaMAS using foundational RL techniques. Moreover, the direct application of MARL methodologies to LaMAS introduces significant challenges, stemming from the unique characteristics and mechanisms inherent to LaMAS. To address these challenges, this article presents a comprehensive study of LLM-based MARL and proposes a novel paradigm termed Multi-Agent Reinforcement Fine-Tuning (MARFT). We introduce a universal algorithmic framework tailored for LaMAS, outlining the conceptual foundations, key distinctions, and practical implementation strategies. We begin by reviewing the evolution from RL to Reinforcement Fine-Tuning, setting the stage for a parallel analysis in the multi-agent domain. In the context of LaMAS, we elucidate critical differences between MARL and MARFT. These differences motivate a transition toward a novel, LaMAS-oriented formulation of RFT. Central to this work is the presentation of a robust and scalable MARFT framework. We detail the core algorithm and provide a complete, open-source implementation to facilitate adoption and further research. The latter sections of the paper explore real-world application perspectives and opening challenges in MARFT. By bridging theoretical underpinnings with practical methodologies, this work aims to serve as a roadmap for researchers seeking to advance MARFT toward resilient and adaptive solutions in agentic systems. Our implementation of the proposed framework is publicly available at: https://github.com/jwliao-ai/MARFT.
A Survey of AI Agent Protocols
Apr 23, 2025The rapid development of large language models (LLMs) has led to the widespread deployment of LLM agents across diverse industries, including customer service, content generation, data analysis, and even healthcare. However, as more LLM agents are deployed, a major issue has emerged: there is no standard way for these agents to communicate with external tools or data sources. This lack of standardized protocols makes it difficult for agents to work together or scale effectively, and it limits their ability to tackle complex, real-world tasks. A unified communication protocol for LLM agents could change this. It would allow agents and tools to interact more smoothly, encourage collaboration, and triggering the formation of collective intelligence. In this paper, we provide a systematic overview of existing communication protocols for LLM agents. We classify them into four main categories and make an analysis to help users and developers select the most suitable protocols for specific applications. Additionally, we conduct a comparative performance analysis of these protocols across key dimensions such as security, scalability, and latency. Finally, we explore future challenges, such as how protocols can adapt and survive in fast-evolving environments, and what qualities future protocols might need to support the next generation of LLM agent ecosystems. We expect this work to serve as a practical reference for both researchers and engineers seeking to design, evaluate, or integrate robust communication infrastructures for intelligent agents.
Correcting Noisy Multilabel Predictions: Modeling Label Noise through Latent Space Shifts
Feb 20, 2025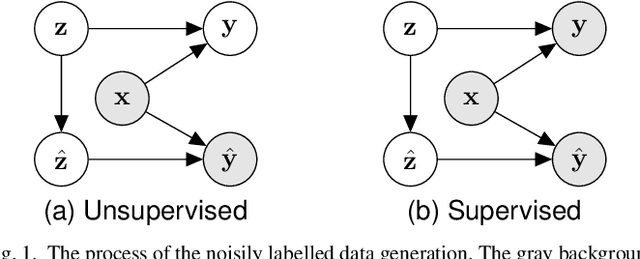



Noise in data appears to be inevitable in most real-world machine learning applications and would cause severe overfitting problems. Not only can data features contain noise, but labels are also prone to be noisy due to human input. In this paper, rather than noisy label learning in multiclass classifications, we instead focus on the less explored area of noisy label learning for multilabel classifications. Specifically, we investigate the post-correction of predictions generated from classifiers learned with noisy labels. The reasons are two-fold. Firstly, this approach can directly work with the trained models to save computational resources. Secondly, it could be applied on top of other noisy label correction techniques to achieve further improvements. To handle this problem, we appeal to deep generative approaches that are possible for uncertainty estimation. Our model posits that label noise arises from a stochastic shift in the latent variable, providing a more robust and beneficial means for noisy learning. We develop both unsupervised and semi-supervised learning methods for our model. The extensive empirical study presents solid evidence to that our approach is able to consistently improve the independent models and performs better than a number of existing methods across various noisy label settings. Moreover, a comprehensive empirical analysis of the proposed method is carried out to validate its robustness, including sensitivity analysis and an ablation study, among other elements.
Agentic Information Retrieval
Oct 13, 2024



What will information entry look like in the next generation of digital products? Since the 1970s, user access to relevant information has relied on domain-specific architectures of information retrieval (IR). Over the past two decades, the advent of modern IR systems, including web search engines and personalized recommender systems, has greatly improved the efficiency of retrieving relevant information from vast data corpora. However, the core paradigm of these IR systems remains largely unchanged, relying on filtering a predefined set of candidate items. Since 2022, breakthroughs in large language models (LLMs) have begun transforming how information is accessed, establishing a new technical paradigm. In this position paper, we introduce Agentic Information Retrieval (Agentic IR), a novel IR paradigm shaped by the capabilities of LLM agents. Agentic IR expands the scope of accessible tasks and leverages a suite of new techniques to redefine information retrieval. We discuss three types of cutting-edge applications of agentic IR and the challenges faced. We propose that agentic IR holds promise for generating innovative applications, potentially becoming a central information entry point in future digital ecosystems.
Hammer: Robust Function-Calling for On-Device Language Models via Function Masking
Oct 06, 2024
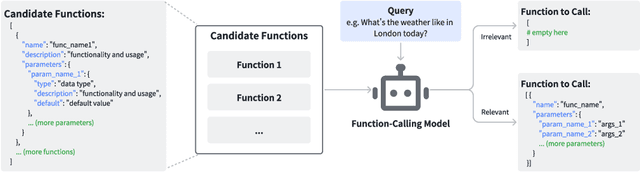


Large language models have demonstrated impressive value in performing as autonomous agents when equipped with external tools and API calls. Nonetheless, effectively harnessing their potential for executing complex tasks crucially relies on enhancements in their function calling capabilities. This paper identifies a critical gap in existing function calling models, where performance varies significantly across benchmarks, often due to being misled by specific naming conventions. To address such an issue, we introduce Hammer, a novel family of foundation models specifically engineered for on-device function calling. Hammer employs an augmented dataset that enhances models' sensitivity to irrelevant functions and incorporates function masking techniques to minimize misleading. Our empirical evaluations reveal that Hammer not only outperforms larger models but also demonstrates robust generalization across diverse benchmarks, achieving sota results. Our open source contributions include a specialized dataset for irrelevance detection, a tuning framework for enhanced generalization, and the Hammer models, establishing a new standard for function calling performance.
SkillNet-NLG: General-Purpose Natural Language Generation with a Sparsely Activated Approach
Apr 26, 2022


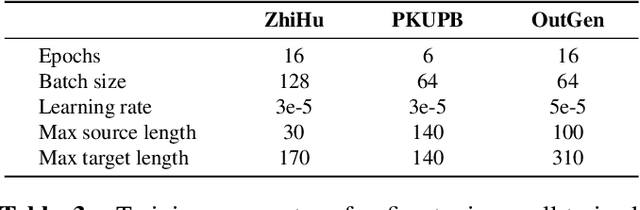
We present SkillNet-NLG, a sparsely activated approach that handles many natural language generation tasks with one model. Different from traditional dense models that always activate all the parameters, SkillNet-NLG selectively activates relevant parts of the parameters to accomplish a task, where the relevance is controlled by a set of predefined skills. The strength of such model design is that it provides an opportunity to precisely adapt relevant skills to learn new tasks effectively. We evaluate on Chinese natural language generation tasks. Results show that, with only one model file, SkillNet-NLG outperforms previous best performance methods on four of five tasks. SkillNet-NLG performs better than two multi-task learning baselines (a dense model and a Mixture-of-Expert model) and achieves comparable performance to task-specific models. Lastly, SkillNet-NLG surpasses baseline systems when being adapted to new tasks.