 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words
Paper and Code
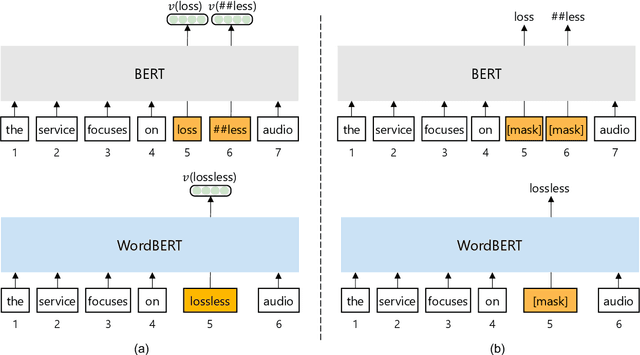
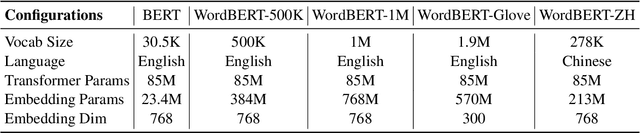
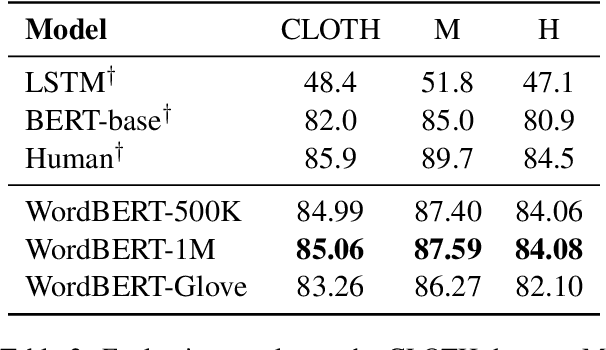
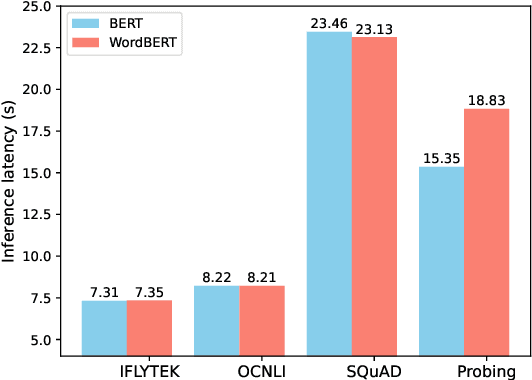
The standard BERT adopts subword-based tokenization, which may break a word into two or more wordpieces (e.g., converting "lossless" to "loss" and "less"). This will bring inconvenience in following situations: (1) what is the best way to obtain the contextual vector of a word that is divided into multiple wordpieces? (2) how to predict a word via cloze test without knowing the number of wordpieces in advance? In this work, we explore the possibility of developing BERT-style pretrained model over a vocabulary of words instead of wordpieces. We call such word-level BERT model as WordBERT. We train models with different vocabulary sizes, initialization configurations and languages. Results show that, compared to standard wordpiece-based BERT, WordBERT makes significant improvements on cloze test and machine reading comprehension. On many other natural language understanding tasks, including POS tagging, chunking and NER, WordBERT consistently performs better than BERT. Model analysis indicates that the major advantage of WordBERT over BERT lies in the understanding for low-frequency words and rare words. Furthermore, since the pipeline is language-independent, we train WordBERT for Chinese language and obtain significant gains on five natural language understanding datasets. Lastly, the analyse on inference speed illustrates WordBERT has comparable time cost to BERT in natural language understanding tasks.