 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIEKM: A Model Incorporating External Keyword Matrices
Nov 21, 2023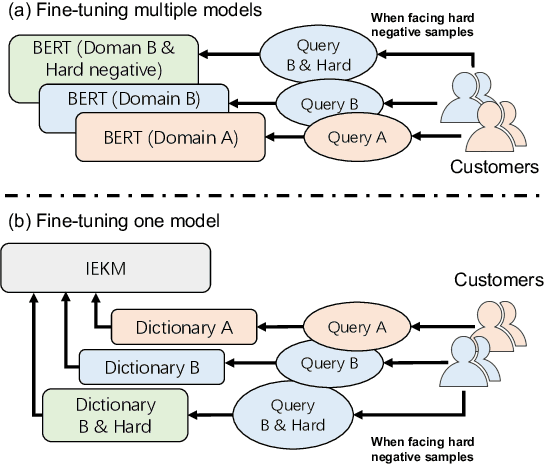
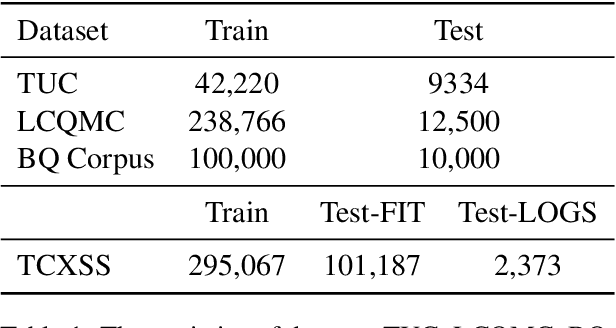
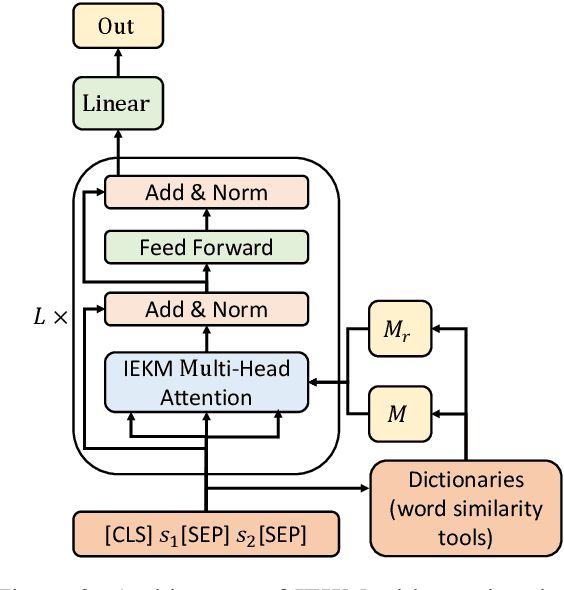
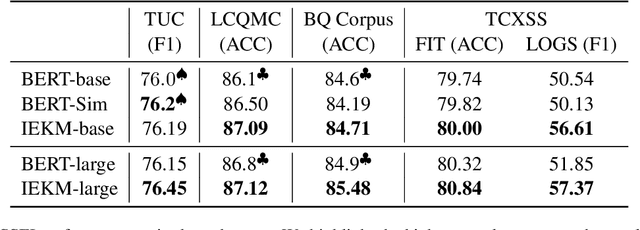
A customer service platform system with a core text semantic similarity (STS) task faces two urgent challenges: Firstly, one platform system needs to adapt to different domains of customers, i.e., different domains adaptation (DDA). Secondly, it is difficult for the model of the platform system to distinguish sentence pairs that are literally close but semantically different, i.e., hard negative samples. In this paper, we propose an incorporation external keywords matrices model (IEKM) to address these challenges. The model uses external tools or dictionaries to construct external matrices and fuses them to the self-attention layers of the Transformer structure through gating units, thus enabling flexible corrections to the model results. We evaluate the method on multiple datasets and the results show that our method has improved performance on all datasets. To demonstrate that our method can effectively solve all the above challenges, we conduct a flexible correction experiment, which results in an increase in the F1 value from 56.61 to 73.53. Our code will be publicly available.
Making Large Language Models Better Reasoners with Alignment
Sep 05, 2023Reasoning is a cognitive process of using evidence to reach a sound conclusion. The reasoning capability is essential for large language models (LLMs) to serve as the brain of the artificial general intelligence agent. Recent studies reveal that fine-tuning LLMs on data with the chain of thought (COT) reasoning process can significantly enhance their reasoning capabilities. However, we find that the fine-tuned LLMs suffer from an \textit{Assessment Misalignment} problem, i.e., they frequently assign higher scores to subpar COTs, leading to potential limitations in their reasoning abilities. To address this problem, we introduce an \textit{Alignment Fine-Tuning (AFT)} paradigm, which involves three steps: 1) fine-tuning LLMs with COT training data; 2) generating multiple COT responses for each question, and categorizing them into positive and negative ones based on whether they achieve the correct answer; 3) calibrating the scores of positive and negative responses given by LLMs with a novel constraint alignment loss. Specifically, the constraint alignment loss has two objectives: a) Alignment, which guarantees that positive scores surpass negative scores to encourage answers with high-quality COTs; b) Constraint, which keeps the negative scores confined to a reasonable range to prevent the model degradation. Beyond just the binary positive and negative feedback, the constraint alignment loss can be seamlessly adapted to the ranking situations when ranking feedback is accessible. Furthermore, we also delve deeply into recent ranking-based alignment methods, such as DPO, RRHF, and PRO, and discover that the constraint, which has been overlooked by these approaches, is also crucial for their performance. Extensive experiments on four reasoning benchmarks with both binary and ranking feedback demonstrate the effectiveness of AFT.
Unifying Token and Span Level Supervisions for Few-Shot Sequence Labeling
Jul 20, 2023Few-shot sequence labeling aims to identify novel classes based on only a few labeled samples. Existing methods solve the data scarcity problem mainly by designing token-level or span-level labeling models based on metric learning. However, these methods are only trained at a single granularity (i.e., either token level or span level) and have some weaknesses of the corresponding granularity. In this paper, we first unify token and span level supervisions and propose a Consistent Dual Adaptive Prototypical (CDAP) network for few-shot sequence labeling. CDAP contains the token-level and span-level networks, jointly trained at different granularities. To align the outputs of two networks, we further propose a consistent loss to enable them to learn from each other. During the inference phase, we propose a consistent greedy inference algorithm that first adjusts the predicted probability and then greedily selects non-overlapping spans with maximum probability. Extensive experiments show that our model achieves new state-of-the-art results on three benchmark datasets.
SkillNet-X: A Multilingual Multitask Model with Sparsely Activated Skills
Jun 28, 2023Traditional multitask learning methods basically can only exploit common knowledge in task- or language-wise, which lose either cross-language or cross-task knowledge. This paper proposes a general multilingual multitask model, named SkillNet-X, which enables a single model to tackle many different tasks from different languages. To this end, we define several language-specific skills and task-specific skills, each of which corresponds to a skill module. SkillNet-X sparsely activates parts of the skill modules which are relevant either to the target task or the target language. Acting as knowledge transit hubs, skill modules are capable of absorbing task-related knowledge and language-related knowledge consecutively. Based on Transformer, we modify the multi-head attention layer and the feed forward network layer to accommodate skill modules. We evaluate SkillNet-X on eleven natural language understanding datasets in four languages. Results show that SkillNet-X performs better than task-specific baselines and two multitask learning baselines (i.e., dense joint model and Mixture-of-Experts model). Furthermore, skill pre-training further improves the performance of SkillNet-X on almost all datasets. To investigate the generalization of our model, we conduct experiments on two new tasks and find that SkillNet-X significantly outperforms baselines.
Soft Language Clustering for Multilingual Model Pre-training
Jun 13, 2023
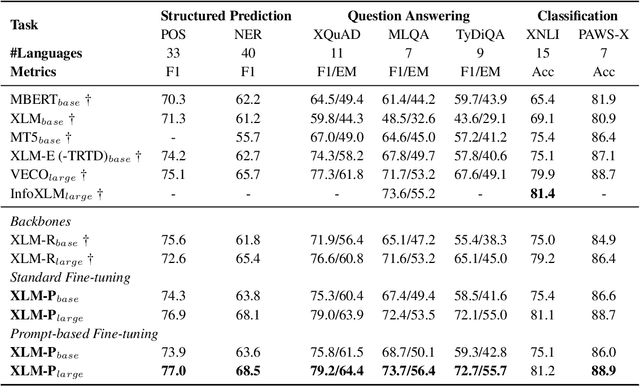
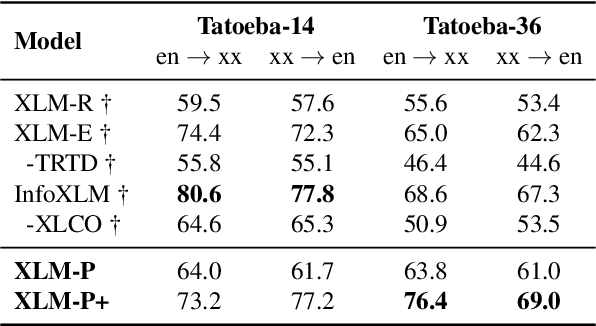
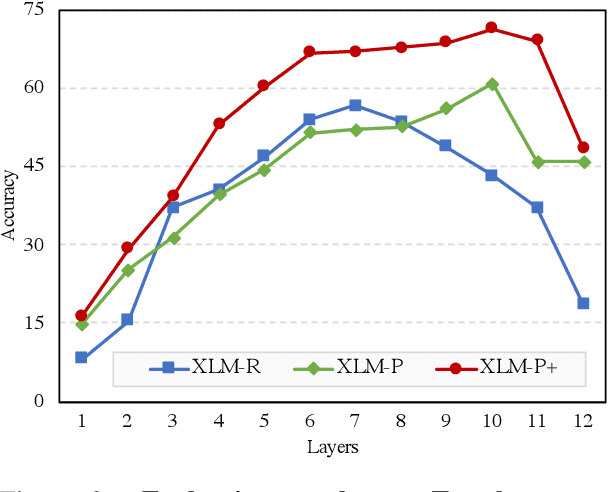
Multilingual pre-trained language models have demonstrated impressive (zero-shot) cross-lingual transfer abilities, however, their performance is hindered when the target language has distant typology from source languages or when pre-training data is limited in size. In this paper, we propose XLM-P, which contextually retrieves prompts as flexible guidance for encoding instances conditionally. Our XLM-P enables (1) lightweight modeling of language-invariant and language-specific knowledge across languages, and (2) easy integration with other multilingual pre-training methods. On the tasks of XTREME including text classification, sequence labeling, question answering, and sentence retrieval, both base- and large-size language models pre-trained with our proposed method exhibit consistent performance improvement. Furthermore, it provides substantial advantages for low-resource languages in unsupervised sentence retrieval and for target languages that differ greatly from the source language in cross-lingual transfer.
Large Language Models are not Fair Evaluators
May 29, 2023



We uncover a systematic bias in the evaluation paradigm of adopting large language models~(LLMs), e.g., GPT-4, as a referee to score the quality of responses generated by candidate models. We find that the quality ranking of candidate responses can be easily hacked by simply altering their order of appearance in the context. This manipulation allows us to skew the evaluation result, making one model appear considerably superior to the other, e.g., vicuna could beat ChatGPT on 66 over 80 tested queries. To address this issue, we propose two simple yet effective calibration strategies: 1) Multiple Evidence Calibration, which requires the evaluator model to generate multiple detailed pieces of evidence before assigning ratings; 2) Balanced Position Calibration, which aggregates results across various orders to determine the final score. Extensive experiments demonstrate that our approach successfully mitigates evaluation bias, resulting in closer alignment with human judgments. To facilitate future research on more robust large language model comparison, we integrate the techniques in the paper into an easy-to-use toolkit \emph{FairEval}, along with the human annotations.\footnote{\url{https://github.com/i-Eval/FairEval}}
Denoising Bottleneck with Mutual Information Maximization for Video Multimodal Fusion
May 25, 2023



Video multimodal fusion aims to integrate multimodal signals in videos, such as visual, audio and text, to make a complementary prediction with multiple modalities contents. However, unlike other image-text multimodal tasks, video has longer multimodal sequences with more redundancy and noise in both visual and audio modalities. Prior denoising methods like forget gate are coarse in the granularity of noise filtering. They often suppress the redundant and noisy information at the risk of losing critical information. Therefore, we propose a denoising bottleneck fusion (DBF) model for fine-grained video multimodal fusion. On the one hand, we employ a bottleneck mechanism to filter out noise and redundancy with a restrained receptive field. On the other hand, we use a mutual information maximization module to regulate the filter-out module to preserve key information within different modalities. Our DBF model achieves significant improvement over current state-of-the-art baselines on multiple benchmarks covering multimodal sentiment analysis and multimodal summarization tasks. It proves that our model can effectively capture salient features from noisy and redundant video, audio, and text inputs. The code for this paper is publicly available at https://github.com/WSXRHFG/DBF.
DialogVCS: Robust Natural Language Understanding in Dialogue System Upgrade
May 24, 2023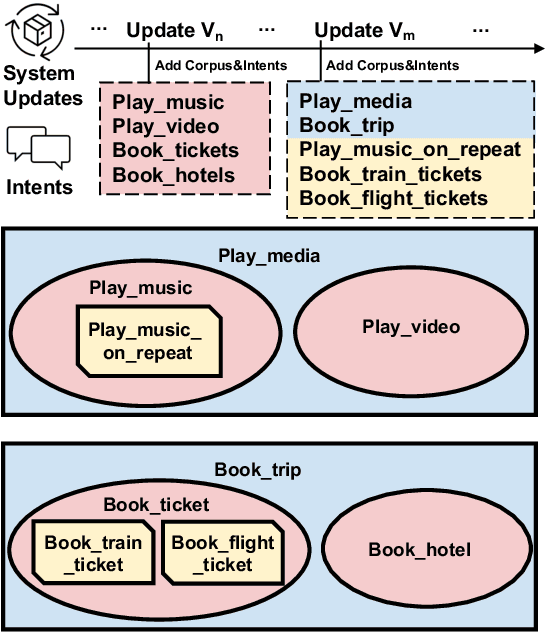


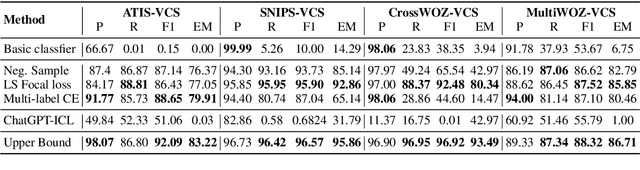
In the constant updates of the product dialogue systems, we need to retrain the natural language understanding (NLU) model as new data from the real users would be merged into the existent data accumulated in the last updates. Within the newly added data, new intents would emerge and might have semantic entanglement with the existing intents, e.g. new intents that are semantically too specific or generic are actually subset or superset of some existing intents in the semantic space, thus impairing the robustness of the NLU model. As the first attempt to solve this problem, we setup a new benchmark consisting of 4 Dialogue Version Control dataSets (DialogVCS). We formulate the intent detection with imperfect data in the system update as a multi-label classification task with positive but unlabeled intents, which asks the models to recognize all the proper intents, including the ones with semantic entanglement, in the inference. We also propose comprehensive baseline models and conduct in-depth analyses for the benchmark, showing that the semantically entangled intents can be effectively recognized with an automatic workflow.
Bi-Drop: Generalizable Fine-tuning for Pre-trained Language Models via Adaptive Subnetwork Optimization
May 24, 2023



Pretrained language models have achieved remarkable success in a variety of natural language understanding tasks. Nevertheless, finetuning large pretrained models on downstream tasks is susceptible to overfitting if the training set is limited, which will lead to diminished performance. In this work, we propose a dynamic fine-tuning strategy for pretrained language models called Bi-Drop. It utilizes the gradient information of various sub-models generated by dropout to update the model parameters selectively. Experiments on the GLUE benchmark show that Bi-Drop outperforms previous fine-tuning methods by a considerable margin, and exhibits consistent superiority over vanilla fine-tuning across various pretrained models. Furthermore, empirical results indicate that Bi-Drop yields substantial improvements in the multiple task or domain transfer, data imbalance, and low-resource scenarios, demonstrating superb generalization ability and robustness.
QURG: Question Rewriting Guided Context-Dependent Text-to-SQL Semantic Parsing
May 16, 2023Context-dependent Text-to-SQL aims to translate multi-turn natural language questions into SQL queries. Despite various methods have exploited context-dependence information implicitly for contextual SQL parsing, there are few attempts to explicitly address the dependencies between current question and question context. This paper presents QURG, a novel Question Rewriting Guided approach to help the models achieve adequate contextual understanding. Specifically, we first train a question rewriting model to complete the current question based on question context, and convert them into a rewriting edit matrix. We further design a two-stream matrix encoder to jointly model the rewriting relations between question and context, and the schema linking relations between natural language and structured schema. Experimental results show that QURG significantly improves the performances on two large-scale context-dependent datasets SParC and CoSQL, especially for hard and long-turn questions.