 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIEKM: A Model Incorporating External Keyword Matrices
Nov 21, 2023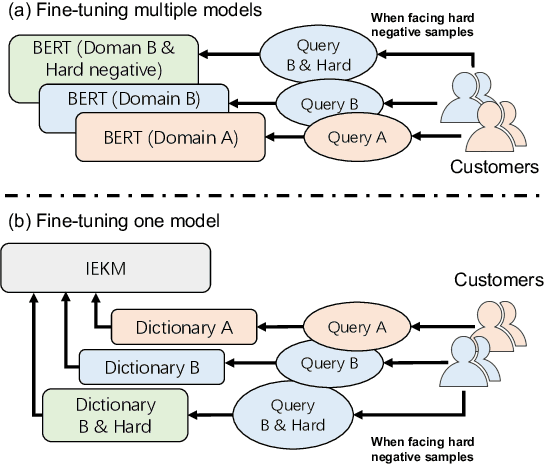
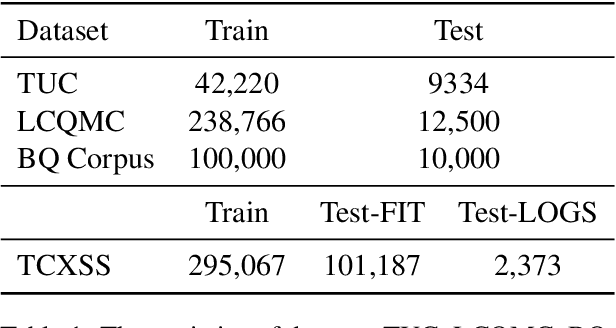
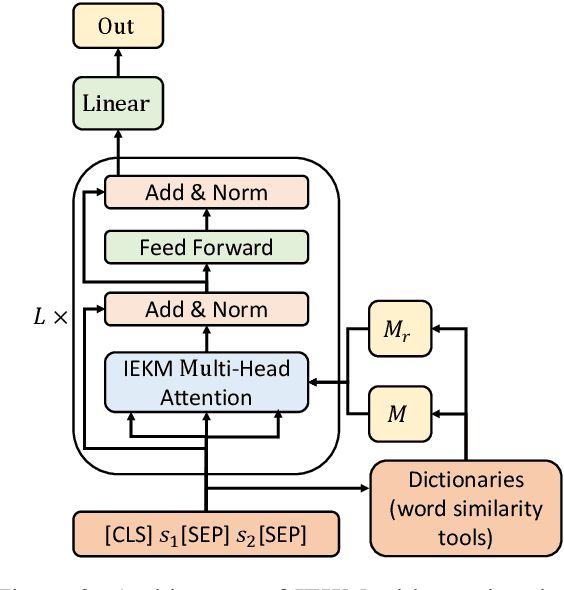
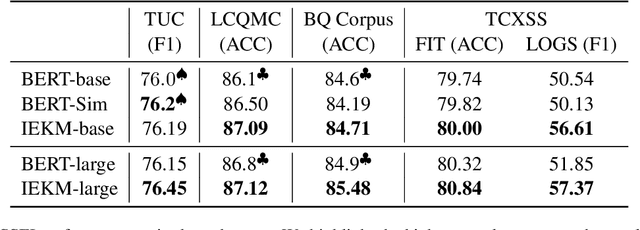
A customer service platform system with a core text semantic similarity (STS) task faces two urgent challenges: Firstly, one platform system needs to adapt to different domains of customers, i.e., different domains adaptation (DDA). Secondly, it is difficult for the model of the platform system to distinguish sentence pairs that are literally close but semantically different, i.e., hard negative samples. In this paper, we propose an incorporation external keywords matrices model (IEKM) to address these challenges. The model uses external tools or dictionaries to construct external matrices and fuses them to the self-attention layers of the Transformer structure through gating units, thus enabling flexible corrections to the model results. We evaluate the method on multiple datasets and the results show that our method has improved performance on all datasets. To demonstrate that our method can effectively solve all the above challenges, we conduct a flexible correction experiment, which results in an increase in the F1 value from 56.61 to 73.53. Our code will be publicly available.
DialogQAE: N-to-N Question Answer Pair Extraction from Customer Service Chatlog
Dec 14, 2022



Harvesting question-answer (QA) pairs from customer service chatlog in the wild is an efficient way to enrich the knowledge base for customer service chatbots in the cold start or continuous integration scenarios. Prior work attempts to obtain 1-to-1 QA pairs from growing customer service chatlog, which fails to integrate the incomplete utterances from the dialog context for composite QA retrieval. In this paper, we propose N-to-N QA extraction task in which the derived questions and corresponding answers might be separated across different utterances. We introduce a suite of generative/discriminative tagging based methods with end-to-end and two-stage variants that perform well on 5 customer service datasets and for the first time setup a benchmark for N-to-N DialogQAE with utterance and session level evaluation metrics. With a deep dive into extracted QA pairs, we find that the relations between and inside the QA pairs can be indicators to analyze the dialogue structure, e.g. information seeking, clarification, barge-in and elaboration. We also show that the proposed models can adapt to different domains and languages, and reduce the labor cost of knowledge accumulation in the real-world product dialogue platform.
SmartSales: Sales Script Extraction and Analysis from Sales Chatlog
Apr 19, 2022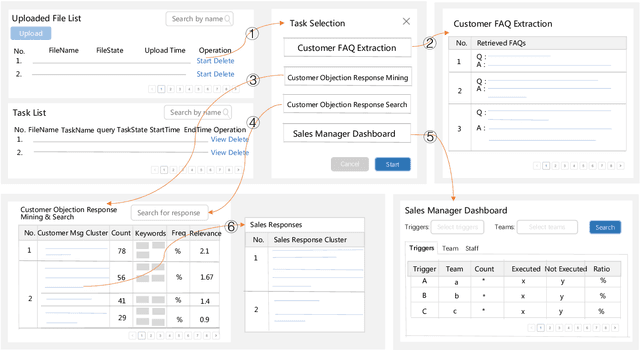
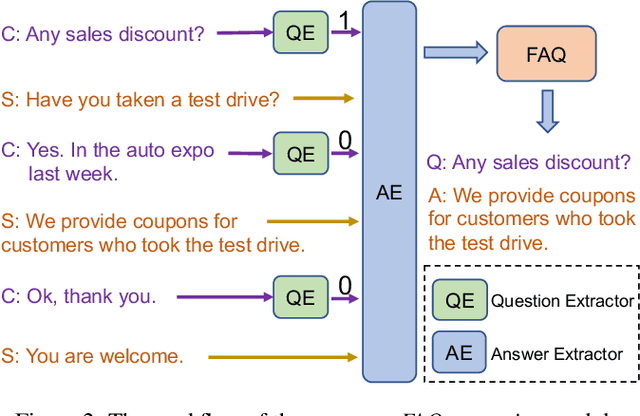
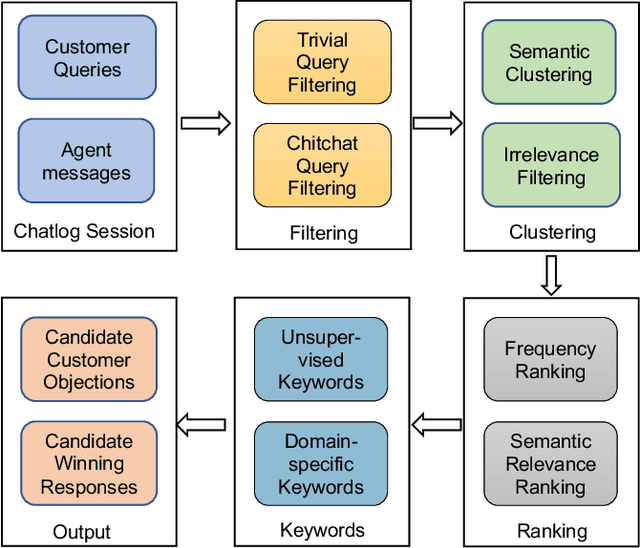
In modern sales applications, automatic script extraction and management greatly decrease the need for human labor to collect the winning sales scripts, which largely boost the success rate for sales and can be shared across the sales teams. In this work, we present the SmartSales system to serve both the sales representatives and managers to attain the sales insights from the large-scale sales chatlog. SmartSales consists of three modules: 1) Customer frequently asked questions (FAQ) extraction aims to enrich the FAQ knowledge base by harvesting high quality customer question-answer pairs from the chatlog. 2) Customer objection response assists the salespeople to figure out the typical customer objections and corresponding winning sales scripts, as well as search for proper sales responses for a certain customer objection. 3) Sales manager dashboard helps sales managers to monitor whether a specific sales representative or team follows the sales standard operating procedures (SOP). The proposed prototype system is empowered by the state-of-the-art conversational intelligence techniques and has been running on the Tencent Cloud to serve the sales teams from several different areas.