 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Harmonized Uncertainty Estimation for Large Language Models
May 25, 2025To facilitate robust and trustworthy deployment of large language models (LLMs), it is essential to quantify the reliability of their generations through uncertainty estimation. While recent efforts have made significant advancements by leveraging the internal logic and linguistic features of LLMs to estimate uncertainty scores, our empirical analysis highlights the pitfalls of these methods to strike a harmonized estimation between indication, balance, and calibration, which hinders their broader capability for accurate uncertainty estimation. To address this challenge, we propose CUE (Corrector for Uncertainty Estimation): A straightforward yet effective method that employs a lightweight model trained on data aligned with the target LLM's performance to adjust uncertainty scores. Comprehensive experiments across diverse models and tasks demonstrate its effectiveness, which achieves consistent improvements of up to 60% over existing methods.
Chain-of-Thought Tokens are Computer Program Variables
May 08, 2025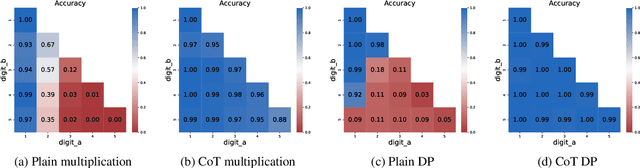



Chain-of-thoughts (CoT) requires large language models (LLMs) to generate intermediate steps before reaching the final answer, and has been proven effective to help LLMs solve complex reasoning tasks. However, the inner mechanism of CoT still remains largely unclear. In this paper, we empirically study the role of CoT tokens in LLMs on two compositional tasks: multi-digit multiplication and dynamic programming. While CoT is essential for solving these problems, we find that preserving only tokens that store intermediate results would achieve comparable performance. Furthermore, we observe that storing intermediate results in an alternative latent form will not affect model performance. We also randomly intervene some values in CoT, and notice that subsequent CoT tokens and the final answer would change correspondingly. These findings suggest that CoT tokens may function like variables in computer programs but with potential drawbacks like unintended shortcuts and computational complexity limits between tokens. The code and data are available at https://github.com/solitaryzero/CoTs_are_Variables.
Inference-Time Scaling for Generalist Reward Modeling
Apr 03, 2025Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that $\textit{proper learning methods could enable effective inference-time scalability}$. A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. In this work, we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the $\textbf{inference-time scalability of generalist RM}$, and further, how to improve the effectiveness of performance-compute scaling with proper learning methods. For the RM approach, we adopt pointwise generative reward modeling (GRM) to enable flexibility for different input types and potential for inference-time scaling. For the learning method, we propose Self-Principled Critique Tuning (SPCT) to foster scalable reward generation behaviors in GRMs through online RL, to generate principles adaptively and critiques accurately, resulting in $\textbf{DeepSeek-GRM}$ models. Furthermore, for effective inference-time scaling, we use parallel sampling to expand compute usage, and introduce a meta RM to guide voting process for better scaling performance. Empirically, we show that SPCT significantly improves the quality and scalability of GRMs, outperforming existing methods and models in various RM benchmarks without severe biases, and could achieve better performance compared to training-time scaling. DeepSeek-GRM still meets challenges in some tasks, which we believe can be addressed by future efforts in generalist reward systems. The models will be released and open-sourced.
Origami-Inspired Soft Gripper with Tunable Constant Force Output
Mar 03, 2025Soft robotic grippers gently and safely manipulate delicate objects due to their inherent adaptability and softness. Limited by insufficient stiffness and imprecise force control, conventional soft grippers are not suitable for applications that require stable grasping force. In this work, we propose a soft gripper that utilizes an origami-inspired structure to achieve tunable constant force output over a wide strain range. The geometry of each taper panel is established to provide necessary parameters such as protrusion distance, taper angle, and crease thickness required for 3D modeling and FEA analysis. Simulations and experiments show that by optimizing these parameters, our design can achieve a tunable constant force output. Moreover, the origami-inspired soft gripper dynamically adapts to different shapes while preventing excessive forces, with potential applications in logistics, manufacturing, and other industrial settings that require stable and adaptive operations
Be a Multitude to Itself: A Prompt Evolution Framework for Red Teaming
Feb 22, 2025Large Language Models (LLMs) have gained increasing attention for their remarkable capacity, alongside concerns about safety arising from their potential to produce harmful content. Red teaming aims to find prompts that could elicit harmful responses from LLMs, and is essential to discover and mitigate safety risks before real-world deployment. However, manual red teaming is both time-consuming and expensive, rendering it unscalable. In this paper, we propose RTPE, a scalable evolution framework to evolve red teaming prompts across both breadth and depth dimensions, facilitating the automatic generation of numerous high-quality and diverse red teaming prompts. Specifically, in-breadth evolving employs a novel enhanced in-context learning method to create a multitude of quality prompts, whereas in-depth evolving applies customized transformation operations to enhance both content and form of prompts, thereby increasing diversity. Extensive experiments demonstrate that RTPE surpasses existing representative automatic red teaming methods on both attack success rate and diversity. In addition, based on 4,800 red teaming prompts created by RTPE, we further provide a systematic analysis of 8 representative LLMs across 8 sensitive topics.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
VLRewardBench: A Challenging Benchmark for Vision-Language Generative Reward Models
Nov 26, 2024



Vision-language generative reward models (VL-GenRMs) play a crucial role in aligning and evaluating multimodal AI systems, yet their own evaluation remains under-explored. Current assessment methods primarily rely on AI-annotated preference labels from traditional VL tasks, which can introduce biases and often fail to effectively challenge state-of-the-art models. To address these limitations, we introduce VL-RewardBench, a comprehensive benchmark spanning general multimodal queries, visual hallucination detection, and complex reasoning tasks. Through our AI-assisted annotation pipeline combining sample selection with human verification, we curate 1,250 high-quality examples specifically designed to probe model limitations. Comprehensive evaluation across 16 leading large vision-language models, demonstrates VL-RewardBench's effectiveness as a challenging testbed, where even GPT-4o achieves only 65.4% accuracy, and state-of-the-art open-source models such as Qwen2-VL-72B, struggle to surpass random-guessing. Importantly, performance on VL-RewardBench strongly correlates (Pearson's r > 0.9) with MMMU-Pro accuracy using Best-of-N sampling with VL-GenRMs. Analysis experiments uncover three critical insights for improving VL-GenRMs: (i) models predominantly fail at basic visual perception tasks rather than reasoning tasks; (ii) inference-time scaling benefits vary dramatically by model capacity; and (iii) training VL-GenRMs to learn to judge substantially boosts judgment capability (+14.7% accuracy for a 7B VL-GenRM). We believe VL-RewardBench along with the experimental insights will become a valuable resource for advancing VL-GenRMs.
VLFeedback: A Large-Scale AI Feedback Dataset for Large Vision-Language Models Alignment
Oct 12, 2024



As large vision-language models (LVLMs) evolve rapidly, the demand for high-quality and diverse data to align these models becomes increasingly crucial. However, the creation of such data with human supervision proves costly and time-intensive. In this paper, we investigate the efficacy of AI feedback to scale supervision for aligning LVLMs. We introduce VLFeedback, the first large-scale vision-language feedback dataset, comprising over 82K multi-modal instructions and comprehensive rationales generated by off-the-shelf models without human annotations. To evaluate the effectiveness of AI feedback for vision-language alignment, we train Silkie, an LVLM fine-tuned via direct preference optimization on VLFeedback. Silkie showcases exceptional performance regarding helpfulness, visual faithfulness, and safety metrics. It outperforms its base model by 6.9\% and 9.5\% in perception and cognition tasks, reduces hallucination issues on MMHal-Bench, and exhibits enhanced resilience against red-teaming attacks. Furthermore, our analysis underscores the advantage of AI feedback, particularly in fostering preference diversity to deliver more comprehensive improvements. Our dataset, training code and models are available at https://vlf-silkie.github.io.
Towards a Unified View of Preference Learning for Large Language Models: A Survey
Sep 04, 2024

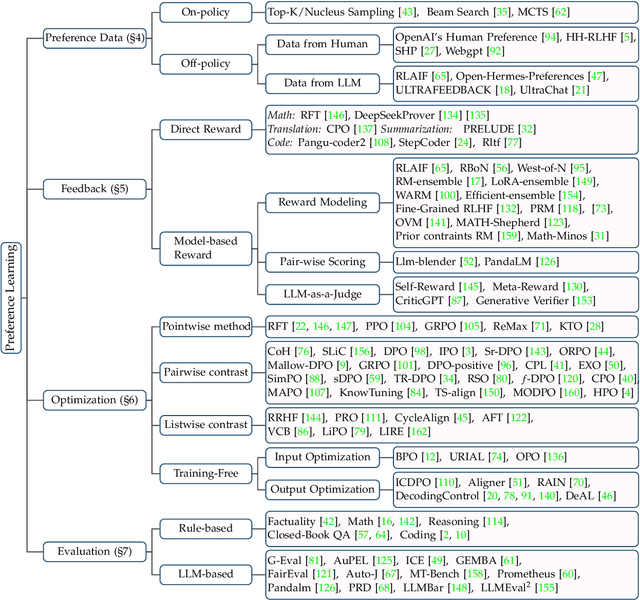
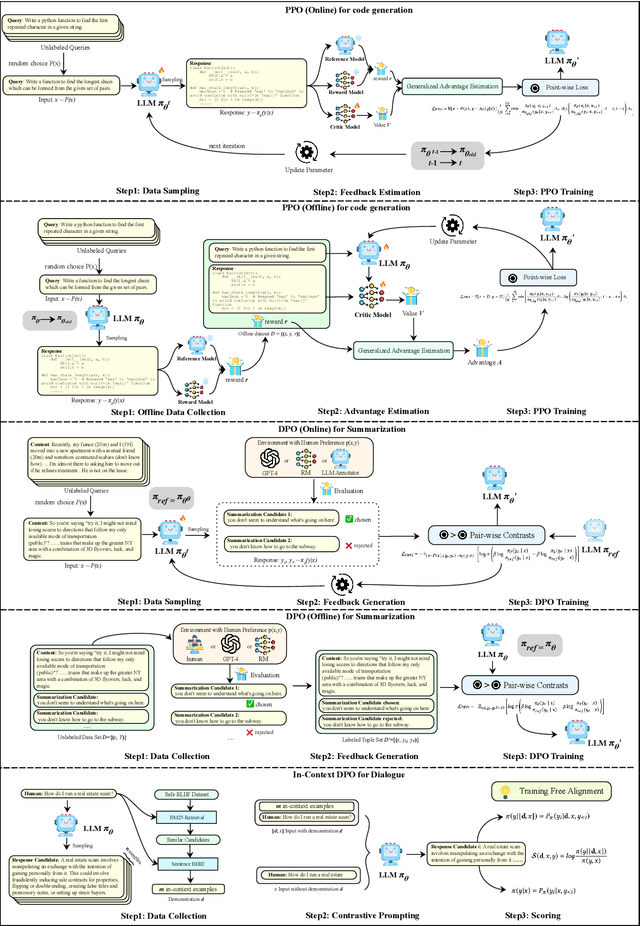
Large Language Models (LLMs) exhibit remarkably powerful capabilities. One of the crucial factors to achieve success is aligning the LLM's output with human preferences. This alignment process often requires only a small amount of data to efficiently enhance the LLM's performance. While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment. In light of this, we break down the existing popular alignment strategies into different components and provide a unified framework to study the current alignment strategies, thereby establishing connections among them. In this survey, we decompose all the strategies in preference learning into four components: model, data, feedback, and algorithm. This unified view offers an in-depth understanding of existing alignment algorithms and also opens up possibilities to synergize the strengths of different strategies. Furthermore, we present detailed working examples of prevalent existing algorithms to facilitate a comprehensive understanding for the readers. Finally, based on our unified perspective, we explore the challenges and future research directions for aligning large language models with human preferences.
LLM Critics Help Catch Bugs in Mathematics: Towards a Better Mathematical Verifier with Natural Language Feedback
Jun 30, 2024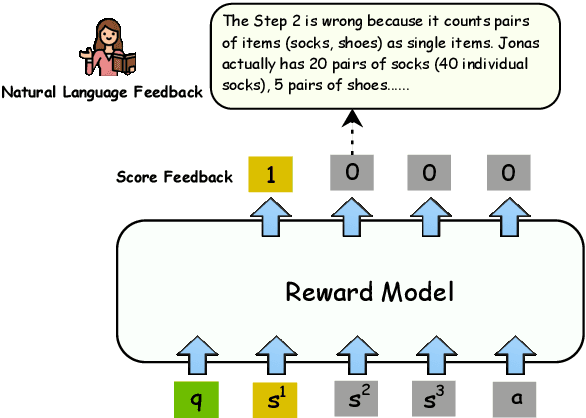
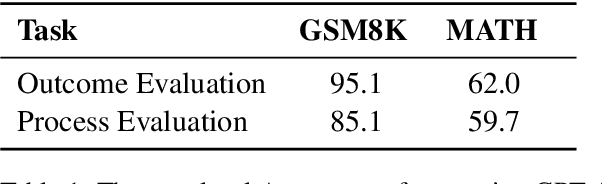
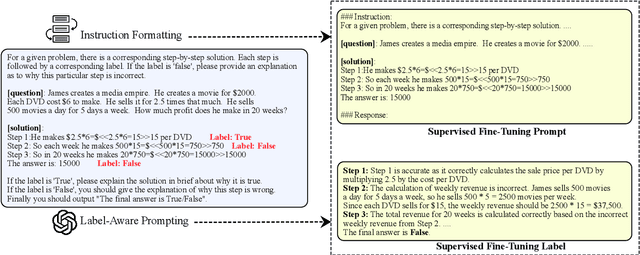

Mathematical verfier achieves success in mathematical reasoning tasks by validating the correctness of solutions. However, existing verifiers are trained with binary classification labels, which are not informative enough for the model to accurately assess the solutions. To mitigate the aforementioned insufficiency of binary labels, we introduce step-wise natural language feedbacks as rationale labels (i.e., the correctness of the current step and the explanations). In this paper, we propose \textbf{Math-Minos}, a natural language feedback enhanced verifier by constructing automatically-generated training data and a two-stage training paradigm for effective training and efficient inference. Our experiments reveal that a small set (30k) of natural language feedbacks can significantly boost the performance of the verifier by the accuracy of 1.6\% (86.6\% $\rightarrow$ 88.2\%) on GSM8K and 0.8\% (37.8\% $\rightarrow$ 38.6\%) on MATH. We have released our code and data for further exploration.