 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffiSkill: Agent Skill Based Automated Code Efficiency Optimization
Mar 29, 2026Code efficiency is a fundamental aspect of software quality, yet how to harness large language models (LLMs) to optimize programs remains challenging. Prior approaches have sought for one-shot rewriting, retrieved exemplars, or prompt-based search, but they do not explicitly distill reusable optimization knowledge, which limits generalization beyond individual instances. In this paper, we present EffiSkill, a framework for code-efficiency optimization that builds a portable optimization toolbox for LLM-based agents. The key idea is to model recurring slow-to-fast transformations as reusable agent skills that capture both concrete transformation mechanisms and higher-level optimization strategies. EffiSkill adopts a two-stage design: Stage I mines Operator and Meta Skills from large-scale slow/fast program pairs to build a skill library; Stage II applies this library to unseen programs through execution-free diagnosis, skill retrieval, plan composition, and candidate generation, without runtime feedback. Results on EffiBench-X show that EffiSkill achieves higher optimization success rates, improving over the strongest baseline by 3.69 to 12.52 percentage points across model and language settings. These findings suggest that mechanism-level skill reuse provides a useful foundation for execution-free code optimization, and that the resulting skill library can serve as a reusable resource for broader agent workflows.
Reasoning in Trees: Improving Retrieval-Augmented Generation for Multi-Hop Question Answering
Jan 16, 2026Retrieval-Augmented Generation (RAG) has demonstrated significant effectiveness in enhancing large language models (LLMs) for complex multi-hop question answering (QA). For multi-hop QA tasks, current iterative approaches predominantly rely on LLMs to self-guide and plan multi-step exploration paths during retrieval, leading to substantial challenges in maintaining reasoning coherence across steps from inaccurate query decomposition and error propagation. To address these issues, we introduce Reasoning Tree Guided RAG (RT-RAG), a novel hierarchical framework for complex multi-hop QA. RT-RAG systematically decomposes multi-hop questions into explicit reasoning trees, minimizing inaccurate decomposition through structured entity analysis and consensus-based tree selection that clearly separates core queries, known entities, and unknown entities. Subsequently, a bottom-up traversal strategy employs iterative query rewriting and refinement to collect high-quality evidence, thereby mitigating error propagation. Comprehensive experiments show that RT-RAG substantially outperforms state-of-the-art methods by 7.0% F1 and 6.0% EM, demonstrating the effectiveness of RT-RAG in complex multi-hop QA.
Learning to Wait: Synchronizing Agents with the Physical World
Dec 18, 2025Real-world agentic tasks, unlike synchronous Markov Decision Processes (MDPs), often involve non-blocking actions with variable latencies, creating a fundamental \textit{Temporal Gap} between action initiation and completion. Existing environment-side solutions, such as blocking wrappers or frequent polling, either limit scalability or dilute the agent's context window with redundant observations. In this work, we propose an \textbf{Agent-side Approach} that empowers Large Language Models (LLMs) to actively align their \textit{Cognitive Timeline} with the physical world. By extending the Code-as-Action paradigm to the temporal domain, agents utilize semantic priors and In-Context Learning (ICL) to predict precise waiting durations (\texttt{time.sleep(t)}), effectively synchronizing with asynchronous environment without exhaustive checking. Experiments in a simulated Kubernetes cluster demonstrate that agents can precisely calibrate their internal clocks to minimize both query overhead and execution latency, validating that temporal awareness is a learnable capability essential for autonomous evolution in open-ended environments.
ReSpec: Towards Optimizing Speculative Decoding in Reinforcement Learning Systems
Oct 30, 2025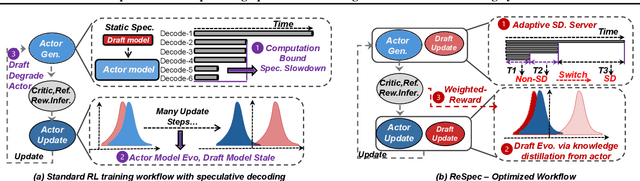

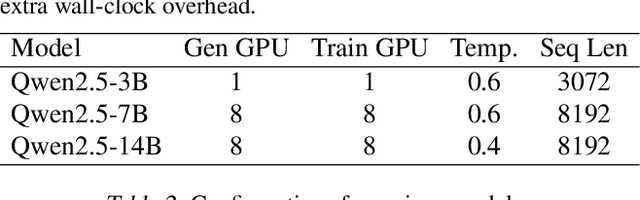

Adapting large language models (LLMs) via reinforcement learning (RL) is often bottlenecked by the generation stage, which can consume over 75\% of the training time. Speculative decoding (SD) accelerates autoregressive generation in serving systems, but its behavior under RL training remains largely unexplored. We identify three critical gaps that hinder the naive integration of SD into RL systems: diminishing speedups at large batch sizes, drafter staleness under continual actor updates, and drafter-induced policy degradation. To address these gaps, we present ReSpec, a system that adapts SD to RL through three complementary mechanisms: dynamically tuning SD configurations, evolving the drafter via knowledge distillation, and weighting updates by rollout rewards. On Qwen models (3B--14B), ReSpec achieves up to 4.5x speedup while preserving reward convergence and training stability, providing a practical solution for efficient RL-based LLM adaptation.
Meta-SurDiff: Classification Diffusion Model Optimized by Meta Learning is Reliable for Online Surgical Phase Recognition
Jun 17, 2025



Online surgical phase recognition has drawn great attention most recently due to its potential downstream applications closely related to human life and health. Despite deep models have made significant advances in capturing the discriminative long-term dependency of surgical videos to achieve improved recognition, they rarely account for exploring and modeling the uncertainty in surgical videos, which should be crucial for reliable online surgical phase recognition. We categorize the sources of uncertainty into two types, frame ambiguity in videos and unbalanced distribution among surgical phases, which are inevitable in surgical videos. To address this pivot issue, we introduce a meta-learning-optimized classification diffusion model (Meta-SurDiff), to take full advantage of the deep generative model and meta-learning in achieving precise frame-level distribution estimation for reliable online surgical phase recognition. For coarse recognition caused by ambiguous video frames, we employ a classification diffusion model to assess the confidence of recognition results at a finer-grained frame-level instance. For coarse recognition caused by unbalanced phase distribution, we use a meta-learning based objective to learn the diffusion model, thus enhancing the robustness of classification boundaries for different surgical phases.We establish effectiveness of Meta-SurDiff in online surgical phase recognition through extensive experiments on five widely used datasets using more than four practical metrics. The datasets include Cholec80, AutoLaparo, M2Cai16, OphNet, and NurViD, where OphNet comes from ophthalmic surgeries, NurViD is the daily care dataset, while the others come from laparoscopic surgeries. We will release the code upon acceptance.
Scaling External Knowledge Input Beyond Context Windows of LLMs via Multi-Agent Collaboration
May 27, 2025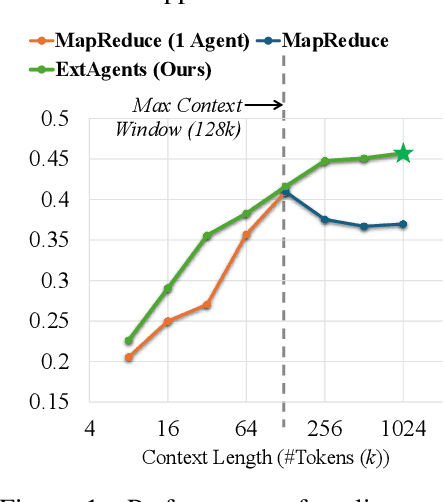

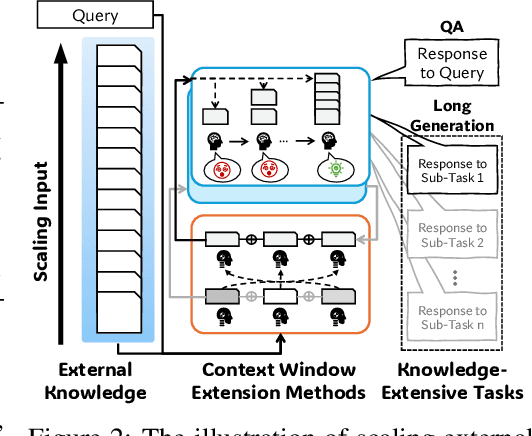
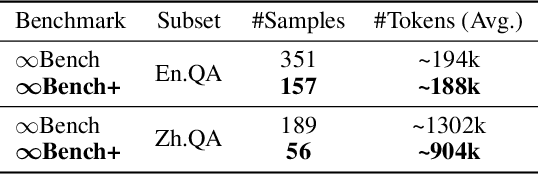
With the rapid advancement of post-training techniques for reasoning and information seeking, large language models (LLMs) can incorporate a large quantity of retrieved knowledge to solve complex tasks. However, the limited context window of LLMs obstructs scaling the amount of external knowledge input, prohibiting further improvement, especially for tasks requiring significant amount of external knowledge. Existing context window extension methods inevitably cause information loss. LLM-based multi-agent methods emerge as a new paradigm to handle massive input in a distributional manner, where we identify two core bottlenecks in existing knowledge synchronization and reasoning processes. In this work, we develop a multi-agent framework, $\textbf{ExtAgents}$, to overcome the bottlenecks and enable better scalability in inference-time knowledge integration without longer-context training. Benchmarked with our enhanced multi-hop question answering test, $\textbf{$\boldsymbol{\infty}$Bench+}$, and other public test sets including long survey generation, ExtAgents significantly enhances the performance over existing non-training methods with the same amount of external knowledge input, regardless of whether it falls $\textit{within or exceeds the context window}$. Moreover, the method maintains high efficiency due to high parallelism. Further study in the coordination of LLM agents on increasing external knowledge input could benefit real-world applications.
Time-Continuous Frequency Allocation for Feeder Links of Mega Constellations with Multi-Antenna Gateway Stations
May 18, 2025With the recent rapid advancement of mega low earth orbit (LEO) satellite constellations, multi-antenna gateway station (MAGS) has emerged as a key enabler to support extremely high system capacity via massive feeder links. However, the densification of both space and ground segment leads to reduced spatial separation between links, posing unprecedented challenges of interference exacerbation. This paper investigates graph coloring-based frequency allocation methods for interference mitigation (IM) of mega LEO systems. We first reveal the characteristics of MAGS interference pattern and formulate the IM problem into a $K$-coloring problem using an adaptive threshold method. Then we propose two tailored graph coloring algorithms, namely Generalized Global (GG) and Clique-Based Tabu Search (CTS), to solve this problem. GG employs a low-complexity greedy conflict avoidance strategy, while CTS leverages the unique clique structure brought by MAGSs to enhance IM performance. Subsequently, we innovatively modify them to achieve time-continuous frequency allocation, which is crucial to ensure the stability of feeder links. Moreover, we further devise two mega constellation decomposition methods to alleviate the complexity burden of satellite operators. Finally, we propose a list coloring-based vacant subchannel utilization method to further improve spectrum efficiency and system capacity. Simulation results on Starlink constellation of the first and second generations with 34396 satellites demonstrate the effectiveness and superiority of the proposed methodology.
Inference-Time Scaling for Generalist Reward Modeling
Apr 03, 2025Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that $\textit{proper learning methods could enable effective inference-time scalability}$. A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. In this work, we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the $\textbf{inference-time scalability of generalist RM}$, and further, how to improve the effectiveness of performance-compute scaling with proper learning methods. For the RM approach, we adopt pointwise generative reward modeling (GRM) to enable flexibility for different input types and potential for inference-time scaling. For the learning method, we propose Self-Principled Critique Tuning (SPCT) to foster scalable reward generation behaviors in GRMs through online RL, to generate principles adaptively and critiques accurately, resulting in $\textbf{DeepSeek-GRM}$ models. Furthermore, for effective inference-time scaling, we use parallel sampling to expand compute usage, and introduce a meta RM to guide voting process for better scaling performance. Empirically, we show that SPCT significantly improves the quality and scalability of GRMs, outperforming existing methods and models in various RM benchmarks without severe biases, and could achieve better performance compared to training-time scaling. DeepSeek-GRM still meets challenges in some tasks, which we believe can be addressed by future efforts in generalist reward systems. The models will be released and open-sourced.
Enhancing Language Multi-Agent Learning with Multi-Agent Credit Re-Assignment for Interactive Environment Generalization
Feb 20, 2025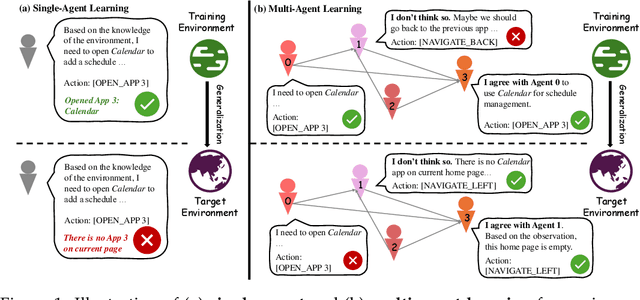
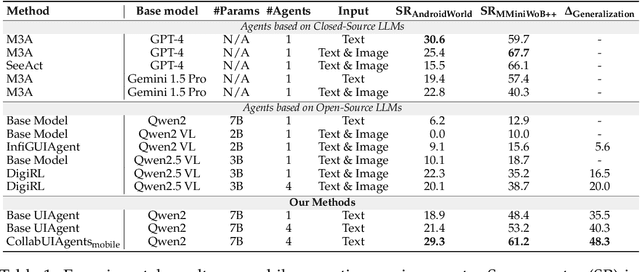
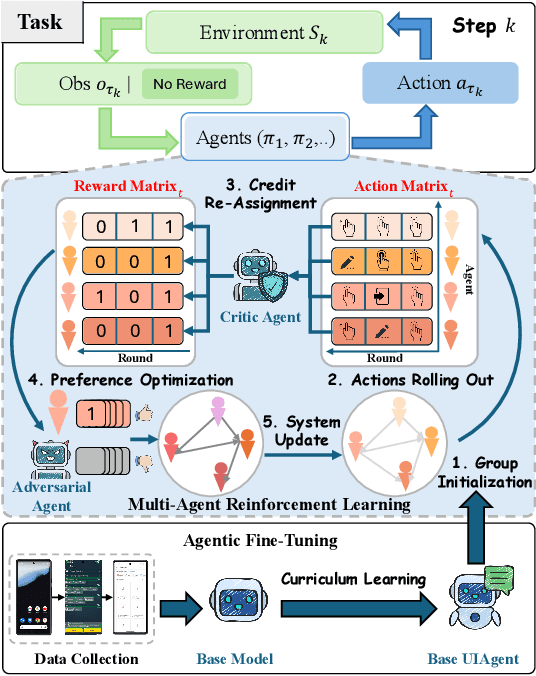
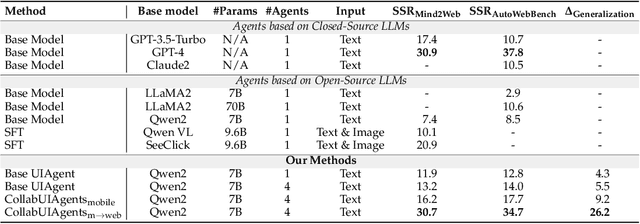
LLM-based agents have made significant advancements in interactive environments, such as mobile operations and web browsing, and other domains beyond computer using. Current multi-agent systems universally excel in performance, compared to single agents, but struggle with generalization across environments due to predefined roles and inadequate strategies for generalizing language agents. The challenge of achieving both strong performance and good generalization has hindered the progress of multi-agent systems for interactive environments. To address these issues, we propose CollabUIAgents, a multi-agent reinforcement learning framework with a novel multi-agent credit re-assignment (CR) strategy, assigning process rewards with LLMs rather than environment-specific rewards and learning with synthesized preference data, in order to foster generalizable, collaborative behaviors among the role-free agents' policies. Empirical results show that our framework improves both performance and cross-environment generalizability of multi-agent systems. Moreover, our 7B-parameter system achieves results on par with or exceed strong closed-source models, and the LLM that guides the CR. We also provide insights in using granular CR rewards effectively for environment generalization, and accommodating trained LLMs in multi-agent systems.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.