 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aware Command and Control Transmission for Multi-UAVs
Jan 29, 2026Uncrewed aerial vehicles (UAVs) have played an important role in the low-altitude economy and have been used in various applications. However, with the increasing number of UAVs and explosive wireless data, the existing bit-oriented communication network has approached the Shannon capacity, which cannot satisfy the quality of service (QoS) with ultra-reliable low-latency communication (URLLC) requirements for command and control (C\&C) transmission in bit-oriented UAV communication networks. To address this issue, we propose a novel semantic-aware C\&C transmission for multi-UAVs under limited wireless resources. Specifically, we leverage semantic similarity to measure the variation in C\&C messages for each UAV over continuous transmission time intervals (TTIs) and capture the correlation of C\&C messages among UAVs, enabling multicast transmission. Based on the semantic similarity and the importance of UAV commands, we design a trigger function to quantify the QoS of UAVs. Then, to maximize the long-term QoS and exploit multicast opportunities of C\&C messages induced by semantic similarity, we develop a proximal policy optimization (PPO) algorithm to jointly determine the transmission mode (unicast/multicast/idle) and the allocation of limited resource blocks (RBs) between a base station (BS) and UAVs. Experimental results show that our proposed semantic-aware framework significantly increases transmission efficiency and improves effectiveness compared with bit-oriented UAV transmission.
Meta-SurDiff: Classification Diffusion Model Optimized by Meta Learning is Reliable for Online Surgical Phase Recognition
Jun 17, 2025



Online surgical phase recognition has drawn great attention most recently due to its potential downstream applications closely related to human life and health. Despite deep models have made significant advances in capturing the discriminative long-term dependency of surgical videos to achieve improved recognition, they rarely account for exploring and modeling the uncertainty in surgical videos, which should be crucial for reliable online surgical phase recognition. We categorize the sources of uncertainty into two types, frame ambiguity in videos and unbalanced distribution among surgical phases, which are inevitable in surgical videos. To address this pivot issue, we introduce a meta-learning-optimized classification diffusion model (Meta-SurDiff), to take full advantage of the deep generative model and meta-learning in achieving precise frame-level distribution estimation for reliable online surgical phase recognition. For coarse recognition caused by ambiguous video frames, we employ a classification diffusion model to assess the confidence of recognition results at a finer-grained frame-level instance. For coarse recognition caused by unbalanced phase distribution, we use a meta-learning based objective to learn the diffusion model, thus enhancing the robustness of classification boundaries for different surgical phases.We establish effectiveness of Meta-SurDiff in online surgical phase recognition through extensive experiments on five widely used datasets using more than four practical metrics. The datasets include Cholec80, AutoLaparo, M2Cai16, OphNet, and NurViD, where OphNet comes from ophthalmic surgeries, NurViD is the daily care dataset, while the others come from laparoscopic surgeries. We will release the code upon acceptance.
Federated Dropout: Convergence Analysis and Resource Allocation
Dec 31, 2024



Federated Dropout is an efficient technique to overcome both communication and computation bottlenecks for deploying federated learning at the network edge. In each training round, an edge device only needs to update and transmit a sub-model, which is generated by the typical method of dropout in deep learning, and thus effectively reduces the per-round latency. \textcolor{blue}{However, the theoretical convergence analysis for Federated Dropout is still lacking in the literature, particularly regarding the quantitative influence of dropout rate on convergence}. To address this issue, by using the Taylor expansion method, we mathematically show that the gradient variance increases with a scaling factor of $\gamma/(1-\gamma)$, with $\gamma \in [0, \theta)$ denoting the dropout rate and $\theta$ being the maximum dropout rate ensuring the loss function reduction. Based on the above approximation, we provide the convergence analysis for Federated Dropout. Specifically, it is shown that a larger dropout rate of each device leads to a slower convergence rate. This provides a theoretical foundation for reducing the convergence latency by making a tradeoff between the per-round latency and the overall rounds till convergence. Moreover, a low-complexity algorithm is proposed to jointly optimize the dropout rate and the bandwidth allocation for minimizing the loss function in all rounds under a given per-round latency and limited network resources. Finally, numerical results are provided to verify the effectiveness of the proposed algorithm.
Computation and Communication Efficient Federated Learning over Wireless Networks
Sep 21, 2023



Federated learning (FL) enables distributed learning across edge devices while protecting data privacy. However, the learning accuracy decreases due to the heterogeneity of devices' data, and the computation and communication latency increase when updating large-scale learning models on devices with limited computational capability and wireless resources. We consider a novel FL framework with partial model pruning and personalization to overcome these challenges. This framework splits the learning model into a global part with model pruning shared with all devices to learn data representations and a personalized part to be fine-tuned for a specific device, which adapts the model size during FL to reduce both computation and communication latency and increases the learning accuracy for the device with non-independent and identically distributed (non-IID) data. Then, the computation and communication latency and the convergence analysis of the proposed FL framework are mathematically analyzed. To maximize the convergence rate and guarantee learning accuracy, Karush Kuhn Tucker (KKT) conditions are deployed to jointly optimize the pruning ratio and bandwidth allocation. Finally, experimental results demonstrate that the proposed FL framework achieves a remarkable reduction of approximately 50 percents computation and communication latency compared with the scheme only with model personalization.
Adaptive Federated Pruning in Hierarchical Wireless Networks
May 15, 2023



Federated Learning (FL) is a promising privacy-preserving distributed learning framework where a server aggregates models updated by multiple devices without accessing their private datasets. Hierarchical FL (HFL), as a device-edge-cloud aggregation hierarchy, can enjoy both the cloud server's access to more datasets and the edge servers' efficient communications with devices. However, the learning latency increases with the HFL network scale due to the increasing number of edge servers and devices with limited local computation capability and communication bandwidth. To address this issue, in this paper, we introduce model pruning for HFL in wireless networks to reduce the neural network scale. We present the convergence analysis of an upper on the l2 norm of gradients for HFL with model pruning, analyze the computation and communication latency of the proposed model pruning scheme, and formulate an optimization problem to maximize the convergence rate under a given latency threshold by jointly optimizing the pruning ratio and wireless resource allocation. By decoupling the optimization problem and using Karush Kuhn Tucker (KKT) conditions, closed-form solutions of pruning ratio and wireless resource allocation are derived. Simulation results show that our proposed HFL with model pruning achieves similar learning accuracy compared with the HFL without model pruning and reduces about 50 percent communication cost.
Federated and Meta learning over Non-Wireless and Wireless Networks: A Tutorial
Oct 24, 2022



In recent years, various machine learning (ML) solutions have been developed to solve resource management, interference management, autonomy, and decision-making problems in non-wireless and wireless networks. Standard ML approaches require collecting data at a central server for training, which cannot preserve the data privacy of devices. To address this issue, federated learning (FL) is an effective method to allow edge devices to collaboratively train ML models without sharing local datasets for data privacy. Typically, FL focuses on learning a global model for a given task and all devices and hence cannot adapt the model to devices with different data distributions. In such cases, meta learning can be employed to adapt learning models to different data distributions using a few data samples. In this tutorial, we conduct a comprehensive review on FL, meta learning, and federated meta learning (FedMeta). Compared to other tutorial papers, our objective is to leverage how FL/meta-learning/FedMeta can be designed, optimized, and evolved over non-wireless and wireless networks. Furthermore, we analyze not only the relationship among these learning algorithms but also their advantages and disadvantages in real-world applications.
Task-Oriented and Semantics-Aware 6G Networks
Oct 17, 2022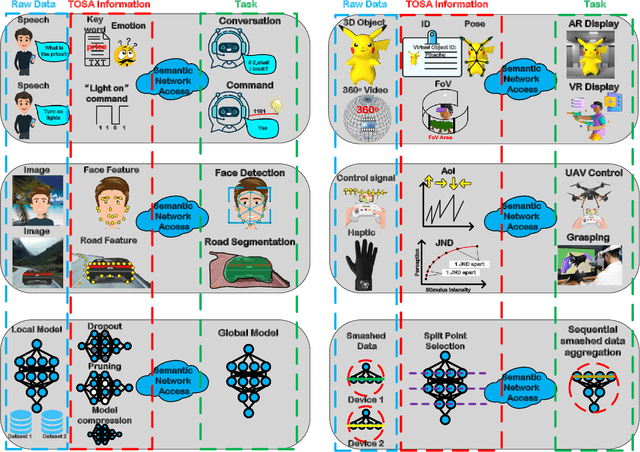
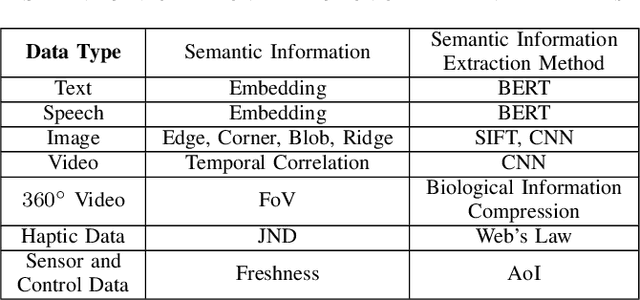
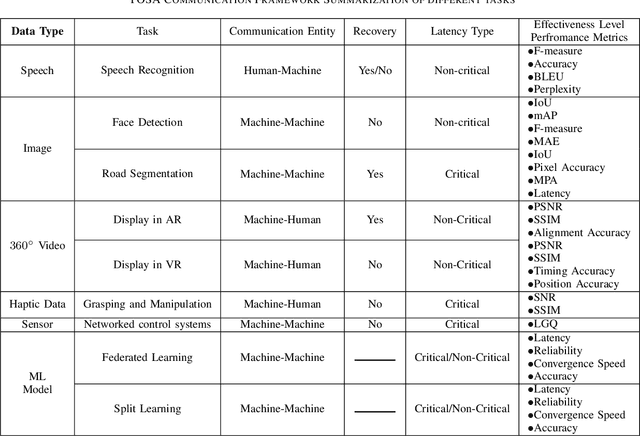
Upon the arrival of emerging devices, including Extended Reality (XR) and Unmanned Aerial Vehicles (UAVs), the traditional bit-oriented communication framework is approaching Shannon's physical capacity limit and fails to guarantee the massive amount of transmission within latency requirements. By jointly exploiting the context of data and its importance to the task, an emerging communication paradigm shift to semantic level and effectiveness level is envisioned to be a key revolution in Sixth Generation (6G) networks. However, an explicit and systematic communication framework incorporating both semantic level and effectiveness level has not been proposed yet. In this article, we propose a generic task-oriented and semantics-aware (TOSA) communication framework for various tasks with diverse data types, which incorporates both semantic level information and effectiveness level performance metrics. We first analyze the unique characteristics of all data types, and summarise the semantic information, along with corresponding extraction methods. We then propose a detailed TOSA communication framework for different time critical and non-critical tasks. In the TOSA framework, we present the TOSA information, extraction methods, recovery methods, and effectiveness level performance metrics. Last but not least, we present a TOSA framework tailored for Virtual Reality (VR) data with interactive VR tasks to validate the effectiveness of the proposed TOSA communication framework.
Learning-based Prediction, Rendering and Transmission for Interactive Virtual Reality in RIS-Assisted Terahertz Networks
Jul 27, 2021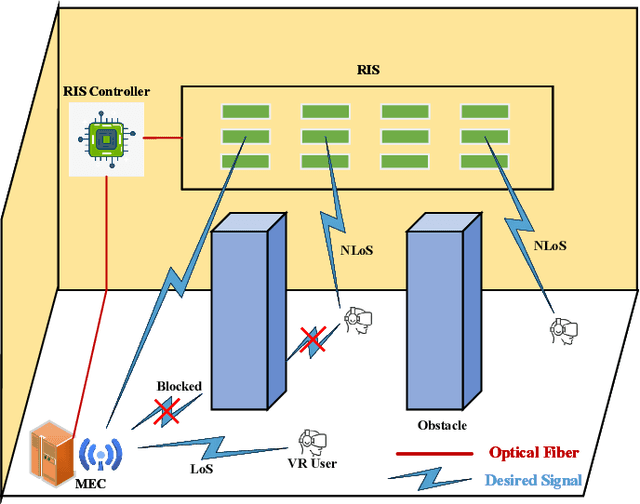
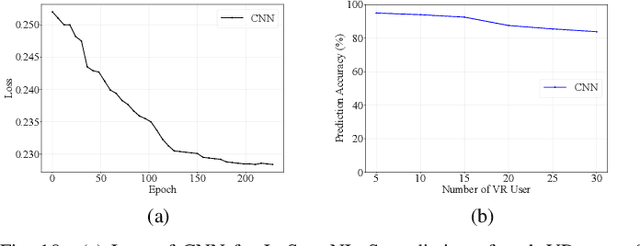
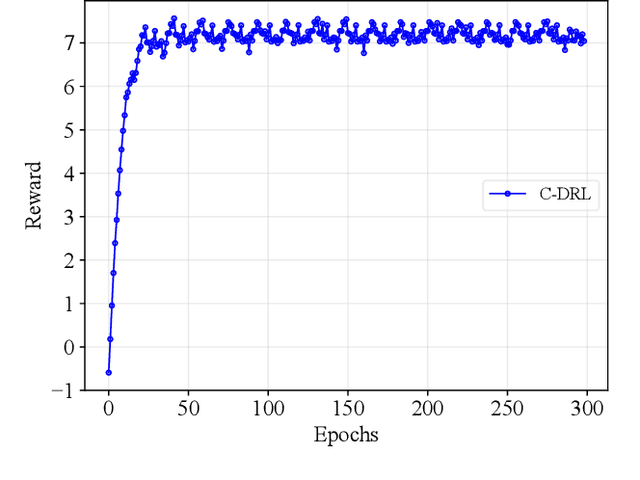
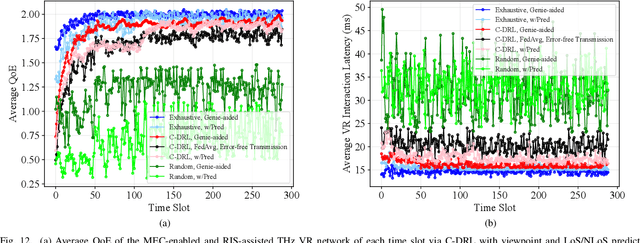
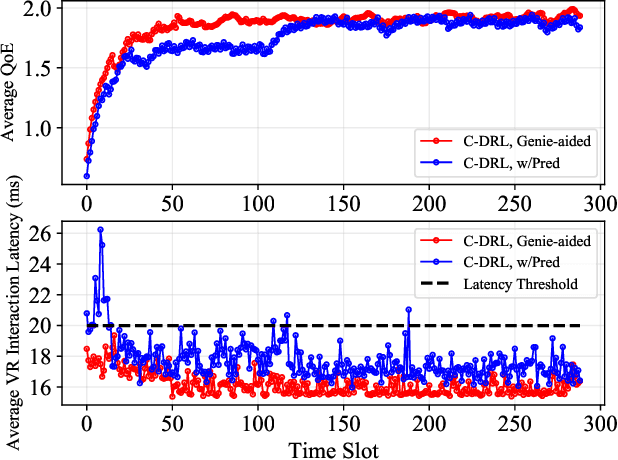
The quality of experience (QoE) requirements of wireless Virtual Reality (VR) can only be satisfied with high data rate, high reliability, and low VR interaction latency. This high data rate over short transmission distances may be achieved via abundant bandwidth in the terahertz (THz) band. However, THz waves suffer from severe signal attenuation, which may be compensated by the reconfigurable intelligent surface (RIS) technology with programmable reflecting elements. Meanwhile, the low VR interaction latency may be achieved with the mobile edge computing (MEC) network architecture due to its high computation capability. Motivated by these considerations, in this paper, we propose a MEC-enabled and RIS-assisted THz VR network in an indoor scenario, by taking into account the uplink viewpoint prediction and position transmission, MEC rendering, and downlink transmission. We propose two methods, which are referred to as centralized online Gated Recurrent Unit (GRU) and distributed Federated Averaging (FedAvg), to predict the viewpoints of VR users. In the uplink, an algorithm that integrates online Long-short Term Memory (LSTM) and Convolutional Neural Networks (CNN) is deployed to predict the locations and the line-of-sight and non-line-of-sight statuses of the VR users over time. In the downlink, we further develop a constrained deep reinforcement learning algorithm to select the optimal phase shifts of the RIS under latency constraints. Simulation results show that our proposed learning architecture achieves near-optimal QoE as that of the genie-aided benchmark algorithm, and about two times improvement in QoE compared to the random phase shift selection scheme.
QoE Optimization for Live Video Streaming in UAV-to-UAV Communications via Deep Reinforcement Learning
Feb 21, 2021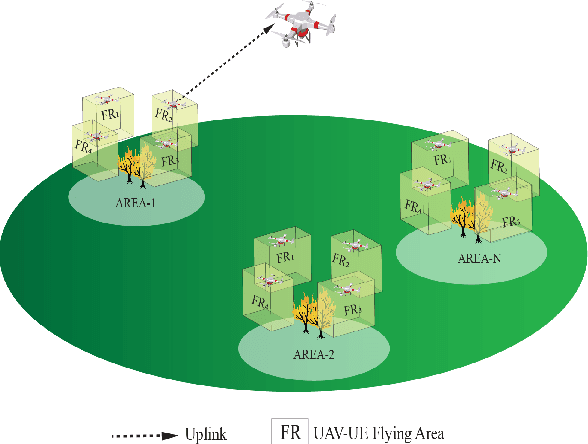
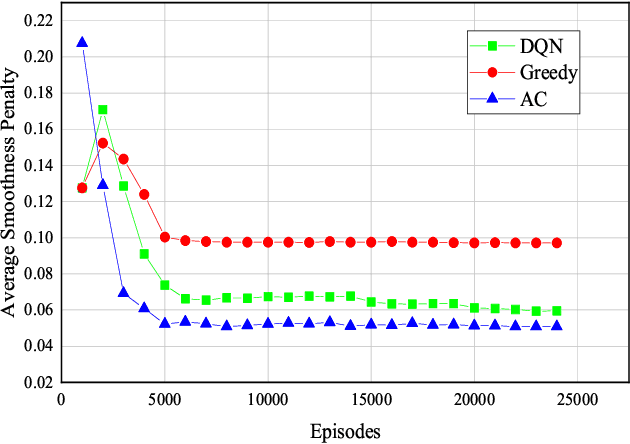
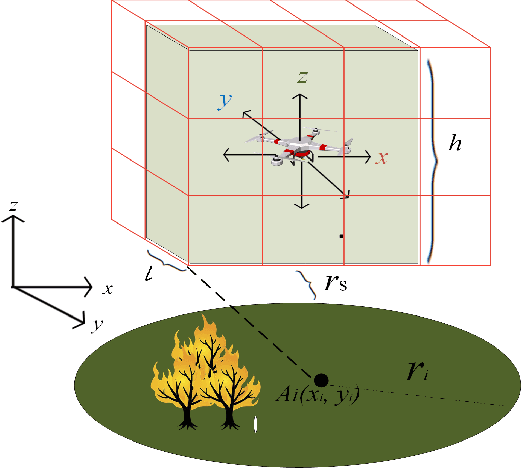
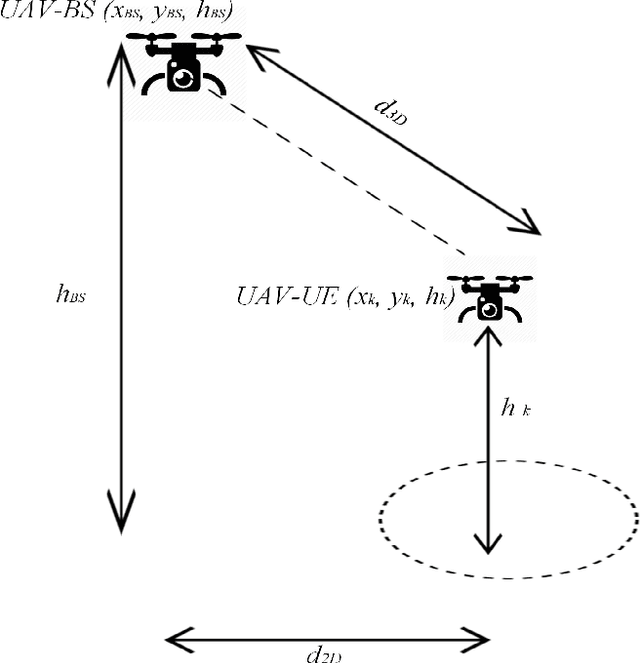
A challenge for rescue teams when fighting against wildfire in remote areas is the lack of information, such as the size and images of fire areas. As such, live streaming from Unmanned Aerial Vehicles (UAVs), capturing videos of dynamic fire areas, is crucial for firefighter commanders in any location to monitor the fire situation with quick response. The 5G network is a promising wireless technology to support such scenarios. In this paper, we consider a UAV-to-UAV (U2U) communication scenario, where a UAV at a high altitude acts as a mobile base station (UAV-BS) to stream videos from other flying UAV-users (UAV-UEs) through the uplink. Due to the mobility of the UAV-BS and UAV-UEs, it is important to determine the optimal movements and transmission powers for UAV-BSs and UAV-UEs in real-time, so as to maximize the data rate of video transmission with smoothness and low latency, while mitigating the interference according to the dynamics in fire areas and wireless channel conditions. In this paper, we co-design the video resolution, the movement, and the power control of UAV-BS and UAV-UEs to maximize the Quality of Experience (QoE) of real-time video streaming. To learn the Deep Q-Network (DQN) and Actor-Critic (AC) to maximize the QoE of video transmission from all UAV-UEs to a single UAVBS. Simulation results show the effectiveness of our proposed algorithm in terms of the QoE, delay and video smoothness as compared to the Greedy algorithm.
Learning-based Prediction and Uplink Retransmission for Wireless Virtual Reality (VR) Network
Dec 16, 2020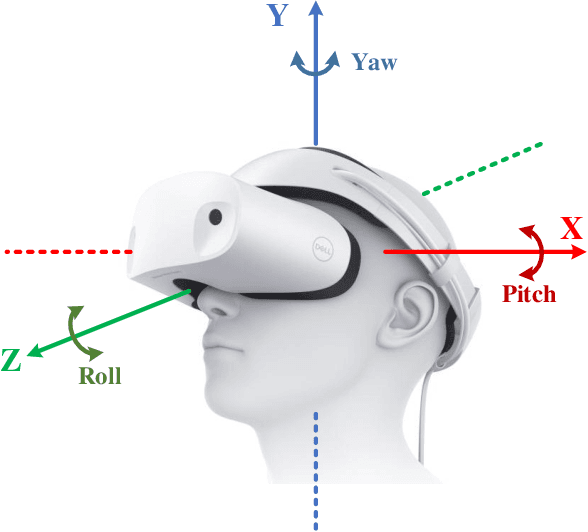

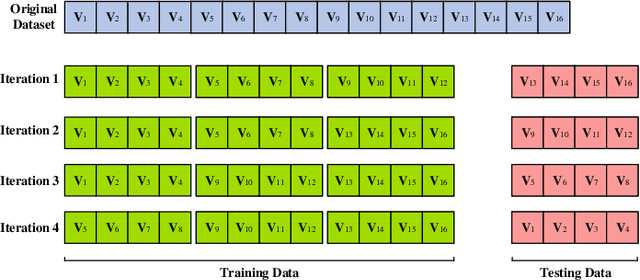
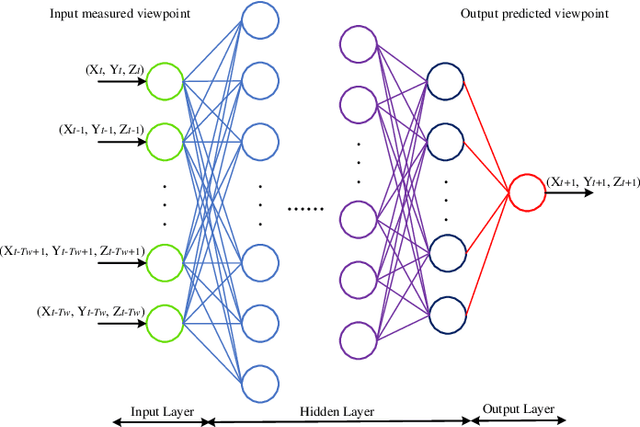
Wireless Virtual Reality (VR) users are able to enjoy immersive experience from anywhere at anytime. However, providing full spherical VR video with high quality under limited VR interaction latency is challenging. If the viewpoint of the VR user can be predicted in advance, only the required viewpoint is needed to be rendered and delivered, which can reduce the VR interaction latency. Therefore, in this paper, we use offline and online learning algorithms to predict viewpoint of the VR user using real VR dataset. For the offline learning algorithm, the trained learning model is directly used to predict the viewpoint of VR users in continuous time slots. While for the online learning algorithm, based on the VR user's actual viewpoint delivered through uplink transmission, we compare it with the predicted viewpoint and update the parameters of the online learning algorithm to further improve the prediction accuracy. To guarantee the reliability of the uplink transmission, we integrate the Proactive retransmission scheme into our proposed online learning algorithm. Simulation results show that our proposed online learning algorithm for uplink wireless VR network with the proactive retransmission scheme only exhibits about 5% prediction error.