 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Classification and Calibration Performance in Decision-Making LLMs via Calibration Aware Reinforcement Learning
Jan 19, 2026Large language models (LLMs) are increasingly deployed in decision-making tasks, where not only accuracy but also reliable confidence estimates are essential. Well-calibrated confidence enables downstream systems to decide when to trust a model and when to defer to fallback mechanisms. In this work, we conduct a systematic study of calibration in two widely used fine-tuning paradigms: supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). We show that while RLVR improves task performance, it produces extremely overconfident models, whereas SFT yields substantially better calibration, even under distribution shift, though with smaller performance gains. Through targeted experiments, we diagnose RLVR's failure, showing that decision tokens act as extraction steps of the decision in reasoning traces and do not carry confidence information, which prevents reinforcement learning from surfacing calibrated alternatives. Based on this insight, we propose a calibration-aware reinforcement learning formulation that directly adjusts decision-token probabilities. Our method preserves RLVR's accuracy level while mitigating overconfidence, reducing ECE scores up to 9 points.
Journey Before Destination: On the importance of Visual Faithfulness in Slow Thinking
Dec 19, 2025Reasoning-augmented vision language models (VLMs) generate explicit chains of thought that promise greater capability and transparency but also introduce new failure modes: models may reach correct answers via visually unfaithful intermediate steps, or reason faithfully yet fail on the final prediction. Standard evaluations that only measure final-answer accuracy cannot distinguish these behaviors. We introduce the visual faithfulness of reasoning chains as a distinct evaluation dimension, focusing on whether the perception steps of a reasoning chain are grounded in the image. We propose a training- and reference-free framework that decomposes chains into perception versus reasoning steps and uses off-the-shelf VLM judges for step-level faithfulness, additionally verifying this approach through a human meta-evaluation. Building on this metric, we present a lightweight self-reflection procedure that detects and locally regenerates unfaithful perception steps without any training. Across multiple reasoning-trained VLMs and perception-heavy benchmarks, our method reduces Unfaithful Perception Rate while preserving final-answer accuracy, improving the reliability of multimodal reasoning.
Computation-aware Energy-harvesting Federated Learning: Cyclic Scheduling with Selective Participation
Nov 14, 2025Federated Learning (FL) is a powerful paradigm for distributed learning, but its increasing complexity leads to significant energy consumption from client-side computations for training models. In particular, the challenge is critical in energy-harvesting FL (EHFL) systems where participation availability of each device oscillates due to limited energy. To address this, we propose FedBacys, a battery-aware EHFL framework using cyclic client participation based on users' battery levels. By clustering clients and scheduling them sequentially, FedBacys minimizes redundant computations, reduces system-wide energy usage, and improves learning stability. We also introduce FedBacys-Odd, a more energy-efficient variant that allows clients to participate selectively, further reducing energy costs without compromising performance. We provide a convergence analysis for our framework and demonstrate its superior energy efficiency and robustness compared to existing algorithms through numerical experiments.
Pareto-Optimal Sampling and Resource Allocation for Timely Communication in Shared-Spectrum Low-Altitude Networks
Oct 30, 2025Guaranteeing stringent data freshness for low-altitude unmanned aerial vehicles (UAVs) in shared spectrum forces a critical trade-off between two operational costs: the UAV's own energy consumption and the occupation of terrestrial channel resources. The core challenge is to satisfy the aerial data freshness while finding a Pareto-optimal balance between these costs. Leveraging predictive channel models and predictive UAV trajectories, we formulate a bi-objective Pareto optimization problem over a long-term planning horizon to jointly optimize the sampling timing for aerial traffic and the power and spectrum allocation for fair coexistence. However, the problem's non-convex, mixed-integer nature renders classical methods incapable of fully characterizing the complete Pareto frontier. Notably, we show monotonicity properties of the frontier, building on which we transform the bi-objective problem into several single-objective problems. We then propose a new graph-based algorithm and prove that it can find the complete set of Pareto optima with low complexity, linear in the horizon and near-quadratic in the resource block (RB) budget. Numerical comparisons show that our approach meets the stringent timeliness requirement and achieves a six-fold reduction in RB utilization or a 6 dB energy saving compared to benchmarks.
Rethinking Federated Learning Over the Air: The Blessing of Scaling Up
Aug 25, 2025Federated learning facilitates collaborative model training across multiple clients while preserving data privacy. However, its performance is often constrained by limited communication resources, particularly in systems supporting a large number of clients. To address this challenge, integrating over-the-air computations into the training process has emerged as a promising solution to alleviate communication bottlenecks. The system significantly increases the number of clients it can support in each communication round by transmitting intermediate parameters via analog signals rather than digital ones. This improvement, however, comes at the cost of channel-induced distortions, such as fading and noise, which affect the aggregated global parameters. To elucidate these effects, this paper develops a theoretical framework to analyze the performance of over-the-air federated learning in large-scale client scenarios. Our analysis reveals three key advantages of scaling up the number of participating clients: (1) Enhanced Privacy: The mutual information between a client's local gradient and the server's aggregated gradient diminishes, effectively reducing privacy leakage. (2) Mitigation of Channel Fading: The channel hardening effect eliminates the impact of small-scale fading in the noisy global gradient. (3) Improved Convergence: Reduced thermal noise and gradient estimation errors benefit the convergence rate. These findings solidify over-the-air model training as a viable approach for federated learning in networks with a large number of clients. The theoretical insights are further substantiated through extensive experimental evaluations.
Towards Long Context Hallucination Detection
Apr 28, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various tasks. However, they are prone to contextual hallucination, generating information that is either unsubstantiated or contradictory to the given context. Although many studies have investigated contextual hallucinations in LLMs, addressing them in long-context inputs remains an open problem. In this work, we take an initial step toward solving this problem by constructing a dataset specifically designed for long-context hallucination detection. Furthermore, we propose a novel architecture that enables pre-trained encoder models, such as BERT, to process long contexts and effectively detect contextual hallucinations through a decomposition and aggregation mechanism. Our experimental results show that the proposed architecture significantly outperforms previous models of similar size as well as LLM-based models across various metrics, while providing substantially faster inference.
Battery-aware Cyclic Scheduling in Energy-harvesting Federated Learning
Apr 16, 2025


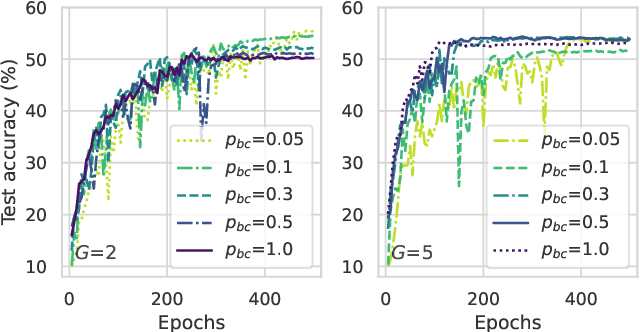
Federated Learning (FL) has emerged as a promising framework for distributed learning, but its growing complexity has led to significant energy consumption, particularly from computations on the client side. This challenge is especially critical in energy-harvesting FL (EHFL) systems, where device availability fluctuates due to limited and time-varying energy resources. We propose FedBacys, a battery-aware FL framework that introduces cyclic client participation based on users' battery levels to cope with these issues. FedBacys enables clients to save energy and strategically perform local training just before their designated transmission time by clustering clients and scheduling their involvement sequentially. This design minimizes redundant computation, reduces system-wide energy usage, and improves learning stability. Our experiments demonstrate that FedBacys outperforms existing approaches in terms of energy efficiency and performance consistency, exhibiting robustness even under non-i.i.d. training data distributions and with very infrequent battery charging. This work presents the first comprehensive evaluation of cyclic client participation in EHFL, incorporating both communication and computation costs into a unified, resource-aware scheduling strategy.
Pull-Based Query Scheduling for Goal-Oriented Semantic Communication
Mar 09, 2025



This paper addresses query scheduling for goal-oriented semantic communication in pull-based status update systems. We consider a system where multiple sensing agents (SAs) observe a source characterized by various attributes and provide updates to multiple actuation agents (AAs), which act upon the received information to fulfill their heterogeneous goals at the endpoint. A hub serves as an intermediary, querying the SAs for updates on observed attributes and maintaining a knowledge base, which is then broadcast to the AAs. The AAs leverage the knowledge to perform their actions effectively. To quantify the semantic value of updates, we introduce a grade of effectiveness (GoE) metric. Furthermore, we integrate cumulative perspective theory (CPT) into the long-term effectiveness analysis to account for risk awareness and loss aversion in the system. Leveraging this framework, we compute effect-aware scheduling policies aimed at maximizing the expected discounted sum of CPT-based total GoE provided by the transmitted updates while complying with a given query cost constraint. To achieve this, we propose a model-based solution based on dynamic programming and model-free solutions employing state-of-the-art deep reinforcement learning (DRL) algorithms. Our findings demonstrate that effect-aware scheduling significantly enhances the effectiveness of communicated updates compared to benchmark scheduling methods, particularly in settings with stringent cost constraints where optimal query scheduling is vital for system performance and overall effectiveness.
DiverseAgentEntropy: Quantifying Black-Box LLM Uncertainty through Diverse Perspectives and Multi-Agent Interaction
Dec 12, 2024



Quantifying the uncertainty in the factual parametric knowledge of Large Language Models (LLMs), especially in a black-box setting, poses a significant challenge. Existing methods, which gauge a model's uncertainty through evaluating self-consistency in responses to the original query, do not always capture true uncertainty. Models might respond consistently to the origin query with a wrong answer, yet respond correctly to varied questions from different perspectives about the same query, and vice versa. In this paper, we propose a novel method, DiverseAgentEntropy, for evaluating a model's uncertainty using multi-agent interaction under the assumption that if a model is certain, it should consistently recall the answer to the original query across a diverse collection of questions about the same original query. We further implement an abstention policy to withhold responses when uncertainty is high. Our method offers a more accurate prediction of the model's reliability and further detects hallucinations, outperforming other self-consistency-based methods. Additionally, it demonstrates that existing models often fail to consistently retrieve the correct answer to the same query under diverse varied questions even when knowing the correct answer.
Coexistence of Real-Time Source Reconstruction and Broadband Services Over Wireless Networks
Nov 20, 2024Achieving a flexible and efficient sharing of wireless resources among a wide range of novel applications and services is one of the major goals of the sixth-generation of mobile systems (6G). Accordingly, this work investigates the performance of a real-time system that coexists with a broadband service in a frame-based wireless channel. Specifically, we consider real-time remote tracking of an information source, where a device monitors its evolution and sends updates to a base station (BS), which is responsible for real-time source reconstruction and, potentially, remote actuation. To achieve this, the BS employs a grant-free access mechanism to serve the monitoring device together with a broadband user, which share the available wireless resources through orthogonal or non-orthogonal multiple access schemes. We analyse the performance of the system with time-averaged reconstruction error, time-averaged cost of actuation error, and update-delivery cost as performance metrics. Furthermore, we analyse the performance of the broadband user in terms of throughput and energy efficiency. Our results show that an orthogonal resource sharing between the users is beneficial in most cases where the broadband user requires maximum throughput. However, sharing the resources in a non-orthogonal manner leads to a far greater energy efficiency.