 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEDP: A Hybrid Energy-Distance Prompt-based Framework for Domain Incremental Learning
May 07, 2026Domain Incremental Learning is a critical scenario that requires models to continuously adapt to new data domains without retraining. However, domain shifts often cause severe performance degradation. To address this, we propose Hybrid Energy-Distance Prompt, a domain-incremental framework inspired by Helmholtz free energy. HEDP introduces an energy regularization loss to enhance the separability of domain representations and a hybrid energy-distance weighted mechanism that fuses energy-based and distance-based cues to improve domain selection and generalization. Experiments on multiple benchmarks, including CORe50, show that HEDP achieves superior performance on unseen domains with a 2.57\% accuracy gain, effectively mitigating catastrophic forgetting and enhancing open-world adaptability. Our code is \href{https://github.com/dannis97500/HEDP/}{available here}.
On the (In-)Security of the Shuffling Defense in the Transformer Secure Inference
May 06, 2026For Transformer models, cryptographically secure inference ensures that the client learns only the final output, while the server learns nothing about the client's input. However, securely computing nonlinear layers remains a major efficiency bottleneck due to the substantial communication rounds and data transmission required. To address this issue, prior works reveal intermediate activations to the client, allowing nonlinear operations to be computed in plaintext. Although this approach significantly improves efficiency, exposing activations enables adversaries to extract model weights. To mitigate this risk, existing works employ a shuffling defense that reveals only randomly permuted activations to the client. In this work, we show that the shuffling defense is not as robust as previously claimed. We propose an attack that aligns differently shuffled activations to a common permutation and subsequently exploits them to extract model weights. Experiments on Pythia-70m and GPT-2 demonstrate that the proposed attack can align shuffled activations with mean squared errors ranging from $10^{-9}$ to $10^{-6}$. With a query cost of approximately \$1, the adversary can recover model weights with L1-norm differences ranging from $10^{-4}$ to $10^{-2}$ compared to the oracle weights.
MultiGO++: Monocular 3D Clothed Human Reconstruction via Geometry-Texture Collaboration
Mar 05, 2026Monocular 3D clothed human reconstruction aims to generate a complete and realistic textured 3D avatar from a single image. Existing methods are commonly trained under multi-view supervision with annotated geometric priors, and during inference, these priors are estimated by the pre-trained network from the monocular input. These methods are constrained by three key limitations: texturally by unavailability of training data, geometrically by inaccurate external priors, and systematically by biased single-modality supervision, all leading to suboptimal reconstruction. To address these issues, we propose a novel reconstruction framework, named MultiGO++, which achieves effective systematic geometry-texture collaboration. It consists of three core parts: (1) A multi-source texture synthesis strategy that constructs 15,000+ 3D textured human scans to improve the performance on texture quality estimation in challenge scenarios; (2) A region-aware shape extraction module that extracts and interacts features of each body region to obtain geometry information and a Fourier geometry encoder that mitigates the modality gap to achieve effective geometry learning; (3) A dual reconstruction U-Net that leverages geometry-texture collaborative features to refine and generate high-fidelity textured 3D human meshes. Extensive experiments on two benchmarks and many in-the-wild cases show the superiority of our method over state-of-the-art approaches.
From Basis to Basis: Gaussian Particle Representation for Interpretable PDE Operators
Feb 25, 2026Learning PDE dynamics for fluids increasingly relies on neural operators and Transformer-based models, yet these approaches often lack interpretability and struggle with localized, high-frequency structures while incurring quadratic cost in spatial samples. We propose representing fields with a Gaussian basis, where learned atoms carry explicit geometry (centers, anisotropic scales, weights) and form a compact, mesh-agnostic, directly visualizable state. Building on this representation, we introduce a Gaussian Particle Operator that acts in modal space: learned Gaussian modal windows perform a Petrov-Galerkin measurement, and PG Gaussian Attention enables global cross-scale coupling. This basis-to-basis design is resolution-agnostic and achieves near-linear complexity in N for a fixed modal budget, supporting irregular geometries and seamless 2D-to-3D extension. On standard PDE benchmarks and real datasets, our method attains state-of-the-art competitive accuracy while providing intrinsic interpretability.
TIMERIPPLE: Accelerating vDiTs by Understanding the Spatio-Temporal Correlations in Latent Space
Nov 15, 2025



The recent surge in video generation has shown the growing demand for high-quality video synthesis using large vision models. Existing video generation models are predominantly based on the video diffusion transformer (vDiT), however, they suffer from substantial inference delay due to self-attention. While prior studies have focused on reducing redundant computations in self-attention, they often overlook the inherent spatio-temporal correlations in video streams and directly leverage sparsity patterns from large language models to reduce attention computations. In this work, we take a principled approach to accelerate self-attention in vDiTs by leveraging the spatio-temporal correlations in the latent space. We show that the attention patterns within vDiT are primarily due to the dominant spatial and temporal correlations at the token channel level. Based on this insight, we propose a lightweight and adaptive reuse strategy that approximates attention computations by reusing partial attention scores of spatially or temporally correlated tokens along individual channels. We demonstrate that our method achieves significantly higher computational savings (85\%) compared to state-of-the-art techniques over 4 vDiTs, while preserving almost identical video quality ($<$0.06\% loss on VBench).
VeriCoT: Neuro-symbolic Chain-of-Thought Validation via Logical Consistency Checks
Nov 06, 2025



LLMs can perform multi-step reasoning through Chain-of-Thought (CoT), but they cannot reliably verify their own logic. Even when they reach correct answers, the underlying reasoning may be flawed, undermining trust in high-stakes scenarios. To mitigate this issue, we introduce VeriCoT, a neuro-symbolic method that extracts and verifies formal logical arguments from CoT reasoning. VeriCoT formalizes each CoT reasoning step into first-order logic and identifies premises that ground the argument in source context, commonsense knowledge, or prior reasoning steps. The symbolic representation enables automated solvers to verify logical validity while the NL premises allow humans and systems to identify ungrounded or fallacious reasoning steps. Experiments on the ProofWriter, LegalBench, and BioASQ datasets show VeriCoT effectively identifies flawed reasoning, and serves as a strong predictor of final answer correctness. We also leverage VeriCoT's verification signal for (1) inference-time self-reflection, (2) supervised fine-tuning (SFT) on VeriCoT-distilled datasets and (3) preference fine-tuning (PFT) with direct preference optimization (DPO) using verification-based pairwise rewards, further improving reasoning validity and accuracy.
Beyond Random Masking: A Dual-Stream Approach for Rotation-Invariant Point Cloud Masked Autoencoders
Sep 18, 2025Existing rotation-invariant point cloud masked autoencoders (MAE) rely on random masking strategies that overlook geometric structure and semantic coherence. Random masking treats patches independently, failing to capture spatial relationships consistent across orientations and overlooking semantic object parts that maintain identity regardless of rotation. We propose a dual-stream masking approach combining 3D Spatial Grid Masking and Progressive Semantic Masking to address these fundamental limitations. Grid masking creates structured patterns through coordinate sorting to capture geometric relationships that persist across different orientations, while semantic masking uses attention-driven clustering to discover semantically meaningful parts and maintain their coherence during masking. These complementary streams are orchestrated via curriculum learning with dynamic weighting, progressing from geometric understanding to semantic discovery. Designed as plug-and-play components, our strategies integrate into existing rotation-invariant frameworks without architectural changes, ensuring broad compatibility across different approaches. Comprehensive experiments on ModelNet40, ScanObjectNN, and OmniObject3D demonstrate consistent improvements across various rotation scenarios, showing substantial performance gains over the baseline rotation-invariant methods.
ClusterFusion: Expanding Operator Fusion Scope for LLM Inference via Cluster-Level Collective Primitive
Aug 26, 2025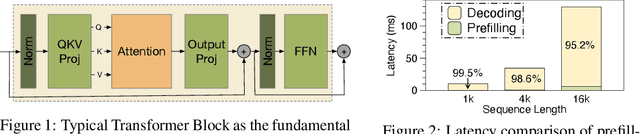
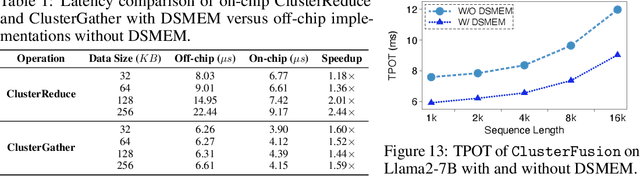
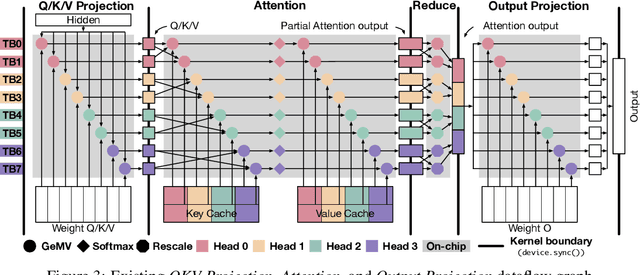
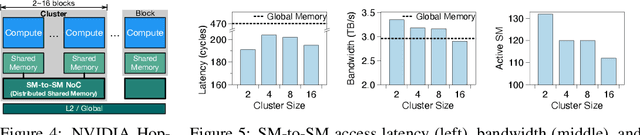
Large language model (LLM) decoding suffers from high latency due to fragmented execution across operators and heavy reliance on off-chip memory for data exchange and reduction. This execution model limits opportunities for fusion and incurs significant memory traffic and kernel launch overhead. While modern architectures such as NVIDIA Hopper provide distributed shared memory and low-latency intra-cluster interconnects, they expose only low-level data movement instructions, lacking structured abstractions for collective on-chip communication. To bridge this software-hardware gap, we introduce two cluster-level communication primitives, ClusterReduce and ClusterGather, which abstract common communication patterns and enable structured, high-speed data exchange and reduction between thread blocks within a cluster, allowing intermediate results to be on-chip without involving off-chip memory. Building on these abstractions, we design ClusterFusion, an execution framework that schedules communication and computation jointly to expand operator fusion scope by composing decoding stages such as QKV Projection, Attention, and Output Projection into a single fused kernels. Evaluations on H100 GPUs show that ClusterFusion outperforms state-of-the-art inference frameworks by 1.61x on average in end-to-end latency across different models and configurations. The source code is available at https://github.com/xinhao-luo/ClusterFusion.
SMPL Normal Map Is All You Need for Single-view Textured Human Reconstruction
Jun 15, 2025Single-view textured human reconstruction aims to reconstruct a clothed 3D digital human by inputting a monocular 2D image. Existing approaches include feed-forward methods, limited by scarce 3D human data, and diffusion-based methods, prone to erroneous 2D hallucinations. To address these issues, we propose a novel SMPL normal map Equipped 3D Human Reconstruction (SEHR) framework, integrating a pretrained large 3D reconstruction model with human geometry prior. SEHR performs single-view human reconstruction without using a preset diffusion model in one forward propagation. Concretely, SEHR consists of two key components: SMPL Normal Map Guidance (SNMG) and SMPL Normal Map Constraint (SNMC). SNMG incorporates SMPL normal maps into an auxiliary network to provide improved body shape guidance. SNMC enhances invisible body parts by constraining the model to predict an extra SMPL normal Gaussians. Extensive experiments on two benchmark datasets demonstrate that SEHR outperforms existing state-of-the-art methods.
STREAMINGGS: Voxel-Based Streaming 3D Gaussian Splatting with Memory Optimization and Architectural Support
Jun 09, 2025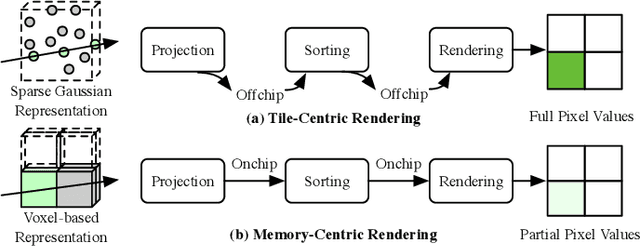
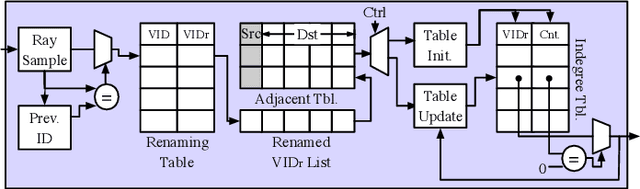
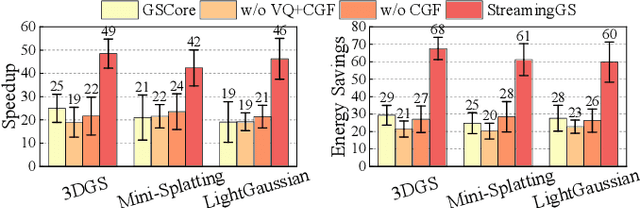
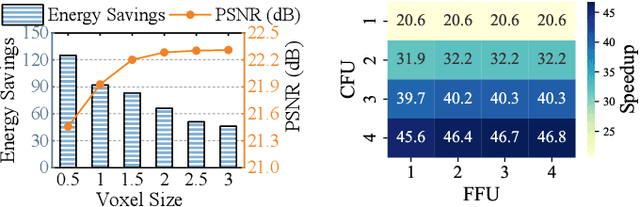
3D Gaussian Splatting (3DGS) has gained popularity for its efficiency and sparse Gaussian-based representation. However, 3DGS struggles to meet the real-time requirement of 90 frames per second (FPS) on resource-constrained mobile devices, achieving only 2 to 9 FPS.Existing accelerators focus on compute efficiency but overlook memory efficiency, leading to redundant DRAM traffic. We introduce STREAMINGGS, a fully streaming 3DGS algorithm-architecture co-design that achieves fine-grained pipelining and reduces DRAM traffic by transforming from a tile-centric rendering to a memory-centric rendering. Results show that our design achieves up to 45.7 $\times$ speedup and 62.9 $\times$ energy savings over mobile Ampere GPUs.