 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGF-DiT: Scheduling Parallelism for Diffusion Transformer Serving
Jun 11, 2026Diffusion Transformers (DiTs) have become the dominant architecture for image and video generation, creating growing demand for efficient DiT serving. Existing systems assign each request a fixed parallel configuration throughout its lifetime. However, DiT workloads exhibit substantial heterogeneity across requests, execution stages, and system conditions, making static parallelism inefficient and often leading to poor GPU utilization and degraded service quality. This paper argues that DiT serving should treat GPU parallelism as a first-class schedulable resource. We present GF-DiT, a policy-programmable runtime for elastic DiT serving that dynamically adapts the parallelism of running requests according to workload demands and service objectives. GF-DiT introduces an asynchronous execution abstraction that decomposes requests into independently schedulable trajectory tasks and enables online GPU reallocation. To make elastic parallelism practical, GF-DiT further proposes group-free collectives, a lightweight communication abstraction that supports low-overhead online formation and reconfiguration of arbitrary execution groups. We implement GF-DiT in vLLM-Omni and evaluate it on representative image and video diffusion workloads. Compared with fixed-pipeline execution with static parallelism, GF-DiT improves throughput by up to 6.01$\times$, reduces mean latency by up to 95%, lowers SLO violation rates by up to 90%, and reduces communication-group setup overhead from 778 ms to approximately 60 $μ$s.
CuBridge: An LLM-Based Framework for Understanding and Reconstructing High-Performance Attention Kernels
May 06, 2026Efficient CUDA implementations of attention mechanisms are critical to modern deep learning systems, yet supporting diverse and evolving attention variants remains challenging. Existing frameworks and compilers trade performance for flexibility, while expert-written kernels achieve high efficiency but are difficult to adapt. Recent work explores large language models (LLMs) for GPU kernel generation, but prior studies report unstable correctness and significant performance gaps for complex operators such as attention. We present CuBridge, an LLM-based framework that adapts expert-written attention kernels through a structured lift-transfer-lower workflow. CuBridge starts from expert-written CUDA attention kernels and lifts them into an executable intermediate representation that makes execution orchestration explicit while abstracting low-level CUDA syntax. Given a user-provided PyTorch specification, CuBridge generates and verifies a target IR program, then reconstructs optimized CUDA code via reference-guided lowering. Across diverse attention variants and GPU platforms, CuBridge consistently produces correct kernels and substantially outperforms general frameworks, compiler-based approaches, and prior LLM-based methods.
On the (In-)Security of the Shuffling Defense in the Transformer Secure Inference
May 06, 2026For Transformer models, cryptographically secure inference ensures that the client learns only the final output, while the server learns nothing about the client's input. However, securely computing nonlinear layers remains a major efficiency bottleneck due to the substantial communication rounds and data transmission required. To address this issue, prior works reveal intermediate activations to the client, allowing nonlinear operations to be computed in plaintext. Although this approach significantly improves efficiency, exposing activations enables adversaries to extract model weights. To mitigate this risk, existing works employ a shuffling defense that reveals only randomly permuted activations to the client. In this work, we show that the shuffling defense is not as robust as previously claimed. We propose an attack that aligns differently shuffled activations to a common permutation and subsequently exploits them to extract model weights. Experiments on Pythia-70m and GPT-2 demonstrate that the proposed attack can align shuffled activations with mean squared errors ranging from $10^{-9}$ to $10^{-6}$. With a query cost of approximately \$1, the adversary can recover model weights with L1-norm differences ranging from $10^{-4}$ to $10^{-2}$ compared to the oracle weights.
DASH: Deterministic Attention Scheduling for High-throughput Reproducible LLM Training
Jan 29, 2026Determinism is indispensable for reproducibility in large language model (LLM) training, yet it often exacts a steep performance cost. In widely used attention implementations such as FlashAttention-3, the deterministic backward pass can incur up to a 37.9% throughput reduction relative to its non-deterministic counterpart, primarily because gradient accumulation operations must be serialized to guarantee numerical consistency. This performance loss stems from suboptimal scheduling of compute and gradient-reduction phases, leading to significant hardware underutilization. To address this challenge, we formulate the backward pass of deterministic attention as a scheduling problem on a Directed Acyclic Graph (DAG) and derive schedules that minimize the critical path length. Building on this formulation, we present DASH (Deterministic Attention Scheduling for High-Throughput), which encapsulates two complementary scheduling strategies: (i) Descending Q-Tile Iteration, a reversed query-block traversal that shrinks pipeline stalls in causal attention, and (ii) Shift Scheduling, a theoretically optimal schedule within our DAG model that reduces pipeline stalls for both full and causal masks. Our empirical evaluations on NVIDIA H800 GPUs demonstrate that DASH narrows the performance gap of deterministic attention. The proposed strategies improve the throughput of the attention backward pass by up to 1.28$\times$ compared to the baseline, significantly advancing the efficiency of reproducible LLM training. Our code is open-sourced at https://github.com/SJTU-Liquid/deterministic-FA3.
Yggdrasil: Bridging Dynamic Speculation and Static Runtime for Latency-Optimal Tree-Based LLM Decoding
Dec 29, 2025Speculative decoding improves LLM inference by generating and verifying multiple tokens in parallel, but existing systems suffer from suboptimal performance due to a mismatch between dynamic speculation and static runtime assumptions. We present Yggdrasil, a co-designed system that enables latency-optimal speculative decoding through context-aware tree drafting and compiler-friendly execution. Yggdrasil introduces an equal-growth tree structure for static graph compatibility, a latency-aware optimization objective for draft selection, and stage-based scheduling to reduce overhead. Yggdrasil supports unmodified LLMs and achieves up to $3.98\times$ speedup over state-of-the-art baselines across multiple hardware setups.
TIMERIPPLE: Accelerating vDiTs by Understanding the Spatio-Temporal Correlations in Latent Space
Nov 15, 2025



The recent surge in video generation has shown the growing demand for high-quality video synthesis using large vision models. Existing video generation models are predominantly based on the video diffusion transformer (vDiT), however, they suffer from substantial inference delay due to self-attention. While prior studies have focused on reducing redundant computations in self-attention, they often overlook the inherent spatio-temporal correlations in video streams and directly leverage sparsity patterns from large language models to reduce attention computations. In this work, we take a principled approach to accelerate self-attention in vDiTs by leveraging the spatio-temporal correlations in the latent space. We show that the attention patterns within vDiT are primarily due to the dominant spatial and temporal correlations at the token channel level. Based on this insight, we propose a lightweight and adaptive reuse strategy that approximates attention computations by reusing partial attention scores of spatially or temporally correlated tokens along individual channels. We demonstrate that our method achieves significantly higher computational savings (85\%) compared to state-of-the-art techniques over 4 vDiTs, while preserving almost identical video quality ($<$0.06\% loss on VBench).
ClusterFusion: Expanding Operator Fusion Scope for LLM Inference via Cluster-Level Collective Primitive
Aug 26, 2025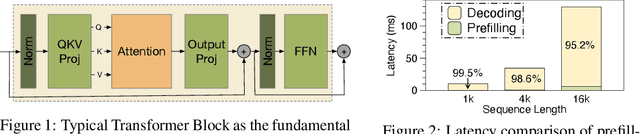
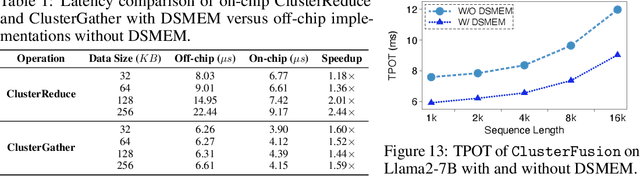
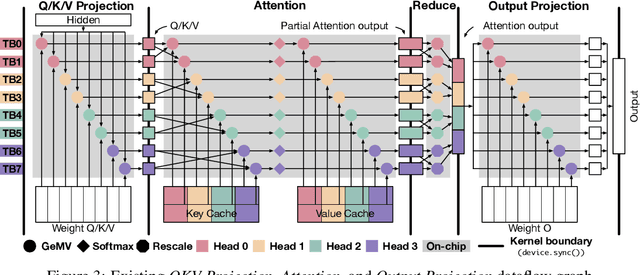
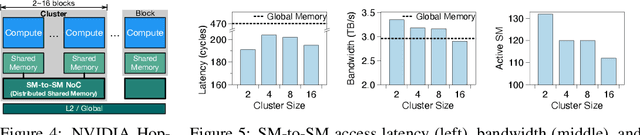
Large language model (LLM) decoding suffers from high latency due to fragmented execution across operators and heavy reliance on off-chip memory for data exchange and reduction. This execution model limits opportunities for fusion and incurs significant memory traffic and kernel launch overhead. While modern architectures such as NVIDIA Hopper provide distributed shared memory and low-latency intra-cluster interconnects, they expose only low-level data movement instructions, lacking structured abstractions for collective on-chip communication. To bridge this software-hardware gap, we introduce two cluster-level communication primitives, ClusterReduce and ClusterGather, which abstract common communication patterns and enable structured, high-speed data exchange and reduction between thread blocks within a cluster, allowing intermediate results to be on-chip without involving off-chip memory. Building on these abstractions, we design ClusterFusion, an execution framework that schedules communication and computation jointly to expand operator fusion scope by composing decoding stages such as QKV Projection, Attention, and Output Projection into a single fused kernels. Evaluations on H100 GPUs show that ClusterFusion outperforms state-of-the-art inference frameworks by 1.61x on average in end-to-end latency across different models and configurations. The source code is available at https://github.com/xinhao-luo/ClusterFusion.
Astraea: A GPU-Oriented Token-wise Acceleration Framework for Video Diffusion Transformers
Jun 06, 2025
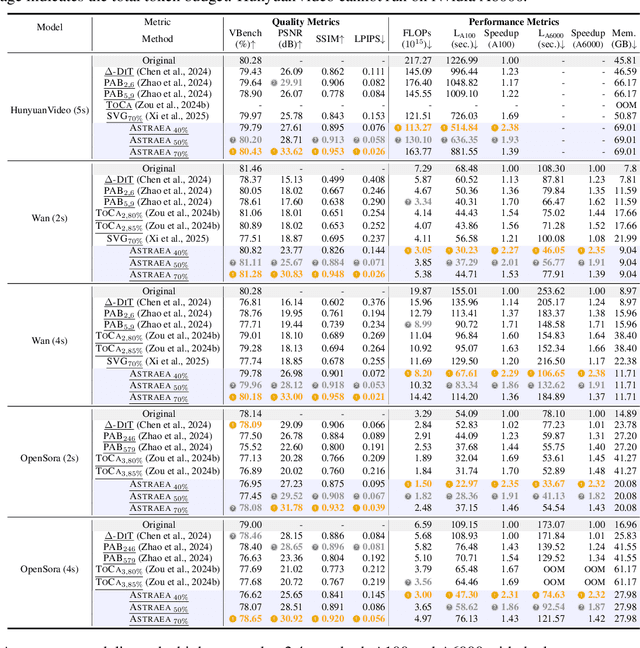
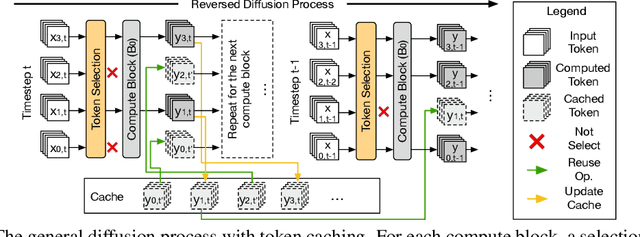
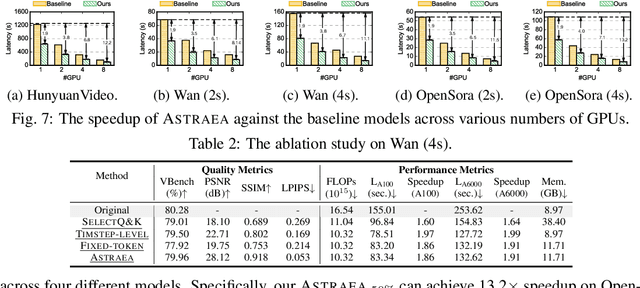
Video diffusion transformers (vDiTs) have made impressive progress in text-to-video generation, but their high computational demands present major challenges for practical deployment. While existing acceleration methods reduce workload at various granularities, they often rely on heuristics, limiting their applicability. We introduce ASTRAEA, an automatic framework that searches for near-optimal configurations for vDiT-based video generation. At its core, ASTRAEA proposes a lightweight token selection mechanism and a memory-efficient, GPU-parallel sparse attention strategy, enabling linear reductions in execution time with minimal impact on generation quality. To determine optimal token reduction for different timesteps, we further design a search framework that leverages a classic evolutionary algorithm to automatically determine the distribution of the token budget effectively. Together, ASTRAEA achieves up to 2.4x inference speedup on a single GPU with great scalability (up to 13.2x speedup on 8 GPUs) while retaining better video quality compared to the state-of-the-art methods (<0.5% loss on the VBench score compared to the baseline vDiT models).
An Efficient Private GPT Never Autoregressively Decodes
May 21, 2025The wide deployment of the generative pre-trained transformer (GPT) has raised privacy concerns for both clients and servers. While cryptographic primitives can be employed for secure GPT inference to protect the privacy of both parties, they introduce considerable performance overhead.To accelerate secure inference, this study proposes a public decoding and secure verification approach that utilizes public GPT models, motivated by the observation that securely decoding one and multiple tokens takes a similar latency. The client uses the public model to generate a set of tokens, which are then securely verified by the private model for acceptance. The efficiency of our approach depends on the acceptance ratio of tokens proposed by the public model, which we improve from two aspects: (1) a private sampling protocol optimized for cryptographic primitives and (2) model alignment using knowledge distillation. Our approach improves the efficiency of secure decoding while maintaining the same level of privacy and generation quality as standard secure decoding. Experiments demonstrate a $2.1\times \sim 6.0\times$ speedup compared to standard decoding across three pairs of public-private models and different network conditions.
WeightedKV: Attention Scores Weighted Key-Value Cache Merging for Large Language Models
Mar 03, 2025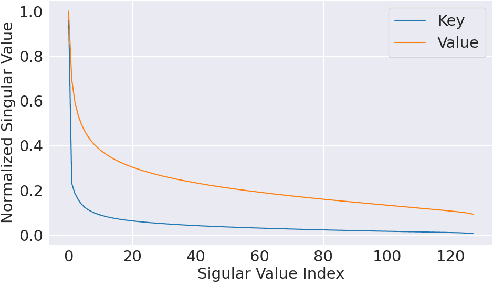
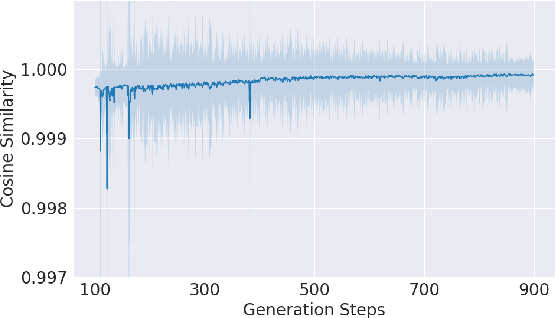
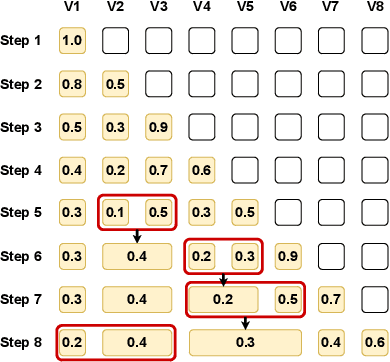
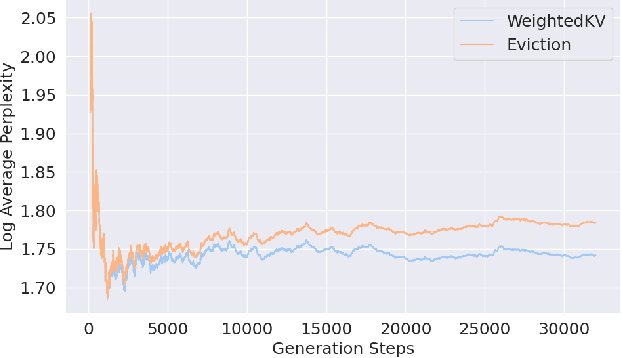
Large Language Models (LLMs) use key-value (KV) cache to reduce redundant computation in autoregressive generation. However, the KV cache size increases linearly during generation, leading to excessive memory usage, especially for long texts. Most KV cache compression methods evict the unimportant KV pairs to maintain a fixed cache size, which leads to the permanent loss of tokens during generation. However, singular value decomposition shows that \textit{values} do not exhibit a strong low-rank property as \textit{keys} do, suggesting that information is distributed more evenly across \textit{values}, in contrast to its more redundant distribution within \textit{keys}. Therefore, methods that evict both \textit{keys} and \textit{values} risk losing crucial information and compromise context integrity, ultimately degrading the output quality. To address this problem, we propose WeightedKV, a novel, training-free approach that discards the \textit{keys} of less important tokens, while merging their \textit{values} into neighboring tokens via a convex combination weighted by their average attention scores. In this way, the retained \textit{keys} serve as anchors that guide the generation process, while the merged \textit{values} provide a rich contextual backdrop. We assess our method on four widely used language modeling datasets, demonstrating superior performance compared to all baseline methods, particularly with a lower budget ratio.