 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNimbus: Secure and Efficient Two-Party Inference for Transformers
Paper and Code



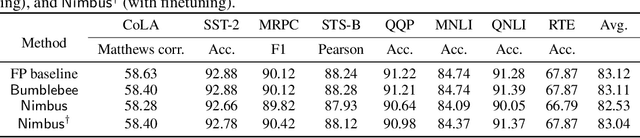
Transformer models have gained significant attention due to their power in machine learning tasks. Their extensive deployment has raised concerns about the potential leakage of sensitive information during inference. However, when being applied to Transformers, existing approaches based on secure two-party computation (2PC) bring about efficiency limitations in two folds: (1) resource-intensive matrix multiplications in linear layers, and (2) complex non-linear activation functions like $\mathsf{GELU}$ and $\mathsf{Softmax}$. This work presents a new two-party inference framework $\mathsf{Nimbus}$ for Transformer models. For the linear layer, we propose a new 2PC paradigm along with an encoding approach to securely compute matrix multiplications based on an outer-product insight, which achieves $2.9\times \sim 12.5\times$ performance improvements compared to the state-of-the-art (SOTA) protocol. For the non-linear layer, through a new observation of utilizing the input distribution, we propose an approach of low-degree polynomial approximation for $\mathsf{GELU}$ and $\mathsf{Softmax}$, which improves the performance of the SOTA polynomial approximation by $2.9\times \sim 4.0\times$, where the average accuracy loss of our approach is 0.08\% compared to the non-2PC inference without privacy. Compared with the SOTA two-party inference, $\mathsf{Nimbus}$ improves the end-to-end performance of \bert{} inference by $2.7\times \sim 4.7\times$ across different network settings.