 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNimbus: Secure and Efficient Two-Party Inference for Transformers
Nov 24, 2024


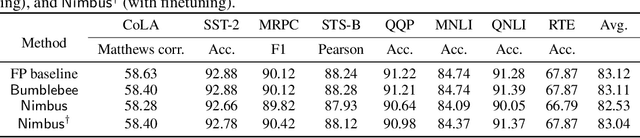
Transformer models have gained significant attention due to their power in machine learning tasks. Their extensive deployment has raised concerns about the potential leakage of sensitive information during inference. However, when being applied to Transformers, existing approaches based on secure two-party computation (2PC) bring about efficiency limitations in two folds: (1) resource-intensive matrix multiplications in linear layers, and (2) complex non-linear activation functions like $\mathsf{GELU}$ and $\mathsf{Softmax}$. This work presents a new two-party inference framework $\mathsf{Nimbus}$ for Transformer models. For the linear layer, we propose a new 2PC paradigm along with an encoding approach to securely compute matrix multiplications based on an outer-product insight, which achieves $2.9\times \sim 12.5\times$ performance improvements compared to the state-of-the-art (SOTA) protocol. For the non-linear layer, through a new observation of utilizing the input distribution, we propose an approach of low-degree polynomial approximation for $\mathsf{GELU}$ and $\mathsf{Softmax}$, which improves the performance of the SOTA polynomial approximation by $2.9\times \sim 4.0\times$, where the average accuracy loss of our approach is 0.08\% compared to the non-2PC inference without privacy. Compared with the SOTA two-party inference, $\mathsf{Nimbus}$ improves the end-to-end performance of \bert{} inference by $2.7\times \sim 4.7\times$ across different network settings.
Ditto: Quantization-aware Secure Inference of Transformers upon MPC
May 09, 2024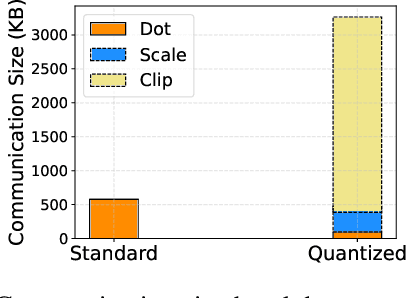
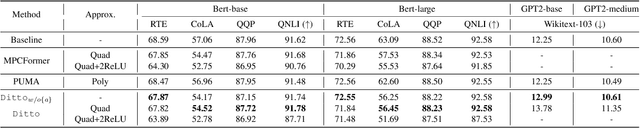
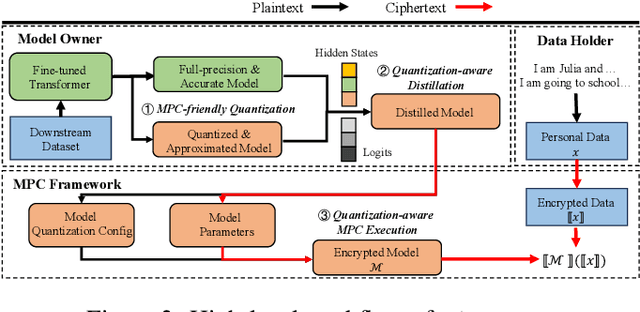
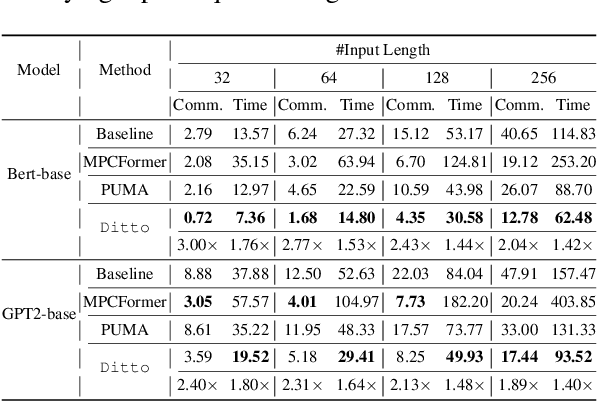
Due to the rising privacy concerns on sensitive client data and trained models like Transformers, secure multi-party computation (MPC) techniques are employed to enable secure inference despite attendant overhead. Existing works attempt to reduce the overhead using more MPC-friendly non-linear function approximations. However, the integration of quantization widely used in plaintext inference into the MPC domain remains unclear. To bridge this gap, we propose the framework named Ditto to enable more efficient quantization-aware secure Transformer inference. Concretely, we first incorporate an MPC-friendly quantization into Transformer inference and employ a quantization-aware distillation procedure to maintain the model utility. Then, we propose novel MPC primitives to support the type conversions that are essential in quantization and implement the quantization-aware MPC execution of secure quantized inference. This approach significantly decreases both computation and communication overhead, leading to improvements in overall efficiency. We conduct extensive experiments on Bert and GPT2 models to evaluate the performance of Ditto. The results demonstrate that Ditto is about $3.14\sim 4.40\times$ faster than MPCFormer (ICLR 2023) and $1.44\sim 2.35\times$ faster than the state-of-the-art work PUMA with negligible utility degradation.