 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinyu AI Search: Enhanced Relevance and Comprehensive Results with Rich Answer Presentations
May 28, 2025Traditional search engines struggle to synthesize fragmented information for complex queries, while generative AI search engines face challenges in relevance, comprehensiveness, and presentation. To address these limitations, we introduce Xinyu AI Search, a novel system that incorporates a query-decomposition graph to dynamically break down complex queries into sub-queries, enabling stepwise retrieval and generation. Our retrieval pipeline enhances diversity through multi-source aggregation and query expansion, while filtering and re-ranking strategies optimize passage relevance. Additionally, Xinyu AI Search introduces a novel approach for fine-grained, precise built-in citation and innovates in result presentation by integrating timeline visualization and textual-visual choreography. Evaluated on recent real-world queries, Xinyu AI Search outperforms eight existing technologies in human assessments, excelling in relevance, comprehensiveness, and insightfulness. Ablation studies validate the necessity of its key sub-modules. Our work presents the first comprehensive framework for generative AI search engines, bridging retrieval, generation, and user-centric presentation.
Token-level Accept or Reject: A Micro Alignment Approach for Large Language Models
May 26, 2025With the rapid development of Large Language Models (LLMs), aligning these models with human preferences and values is critical to ensuring ethical and safe applications. However, existing alignment techniques such as RLHF or DPO often require direct fine-tuning on LLMs with billions of parameters, resulting in substantial computational costs and inefficiencies. To address this, we propose Micro token-level Accept-Reject Aligning (MARA) approach designed to operate independently of the language models. MARA simplifies the alignment process by decomposing sentence-level preference learning into token-level binary classification, where a compact three-layer fully-connected network determines whether candidate tokens are "Accepted" or "Rejected" as part of the response. Extensive experiments across seven different LLMs and three open-source datasets show that MARA achieves significant improvements in alignment performance while reducing computational costs.
An Efficient Private GPT Never Autoregressively Decodes
May 21, 2025The wide deployment of the generative pre-trained transformer (GPT) has raised privacy concerns for both clients and servers. While cryptographic primitives can be employed for secure GPT inference to protect the privacy of both parties, they introduce considerable performance overhead.To accelerate secure inference, this study proposes a public decoding and secure verification approach that utilizes public GPT models, motivated by the observation that securely decoding one and multiple tokens takes a similar latency. The client uses the public model to generate a set of tokens, which are then securely verified by the private model for acceptance. The efficiency of our approach depends on the acceptance ratio of tokens proposed by the public model, which we improve from two aspects: (1) a private sampling protocol optimized for cryptographic primitives and (2) model alignment using knowledge distillation. Our approach improves the efficiency of secure decoding while maintaining the same level of privacy and generation quality as standard secure decoding. Experiments demonstrate a $2.1\times \sim 6.0\times$ speedup compared to standard decoding across three pairs of public-private models and different network conditions.
Semi-Gradient SARSA Routing with Theoretical Guarantee on Traffic Stability and Weight Convergence
Mar 19, 2025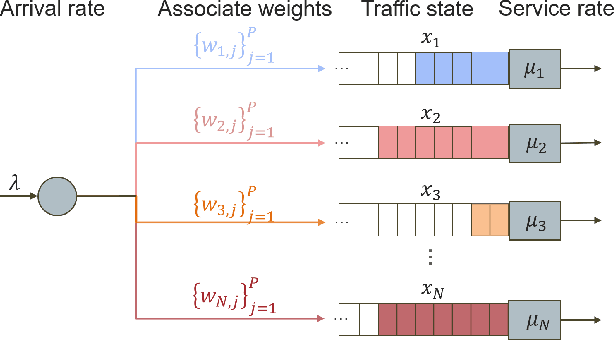
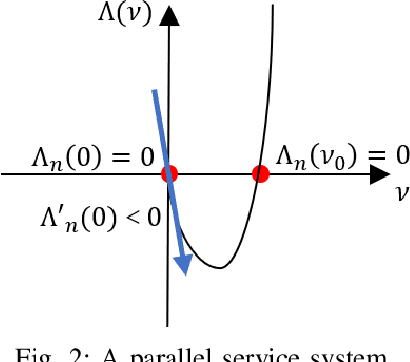
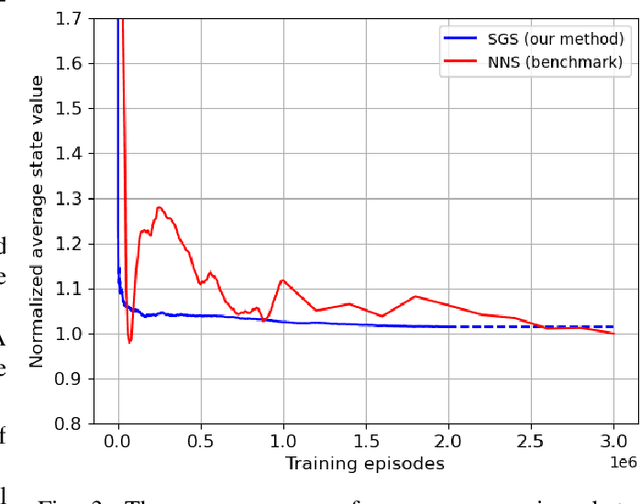

We consider the traffic control problem of dynamic routing over parallel servers, which arises in a variety of engineering systems such as transportation and data transmission. We propose a semi-gradient, on-policy algorithm that learns an approximate optimal routing policy. The algorithm uses generic basis functions with flexible weights to approximate the value function across the unbounded state space. Consequently, the training process lacks Lipschitz continuity of the gradient, boundedness of the temporal-difference error, and a prior guarantee on ergodicity, which are the standard prerequisites in existing literature on reinforcement learning theory. To address this, we combine a Lyapunov approach and an ordinary differential equation-based method to jointly characterize the behavior of traffic state and approximation weights. Our theoretical analysis proves that the training scheme guarantees traffic state stability and ensures almost surely convergence of the weights to the approximate optimum. We also demonstrate via simulations that our algorithm attains significantly faster convergence than neural network-based methods with an insignificant approximation error.
Nimbus: Secure and Efficient Two-Party Inference for Transformers
Nov 24, 2024


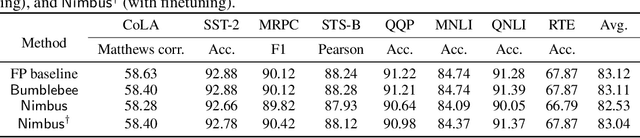
Transformer models have gained significant attention due to their power in machine learning tasks. Their extensive deployment has raised concerns about the potential leakage of sensitive information during inference. However, when being applied to Transformers, existing approaches based on secure two-party computation (2PC) bring about efficiency limitations in two folds: (1) resource-intensive matrix multiplications in linear layers, and (2) complex non-linear activation functions like $\mathsf{GELU}$ and $\mathsf{Softmax}$. This work presents a new two-party inference framework $\mathsf{Nimbus}$ for Transformer models. For the linear layer, we propose a new 2PC paradigm along with an encoding approach to securely compute matrix multiplications based on an outer-product insight, which achieves $2.9\times \sim 12.5\times$ performance improvements compared to the state-of-the-art (SOTA) protocol. For the non-linear layer, through a new observation of utilizing the input distribution, we propose an approach of low-degree polynomial approximation for $\mathsf{GELU}$ and $\mathsf{Softmax}$, which improves the performance of the SOTA polynomial approximation by $2.9\times \sim 4.0\times$, where the average accuracy loss of our approach is 0.08\% compared to the non-2PC inference without privacy. Compared with the SOTA two-party inference, $\mathsf{Nimbus}$ improves the end-to-end performance of \bert{} inference by $2.7\times \sim 4.7\times$ across different network settings.
Learning Code Preference via Synthetic Evolution
Oct 04, 2024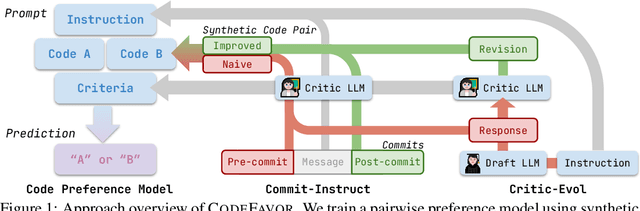

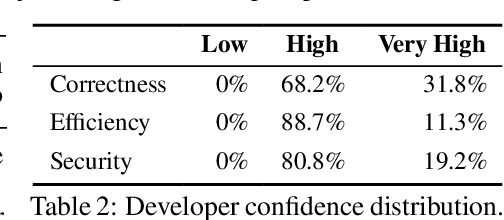
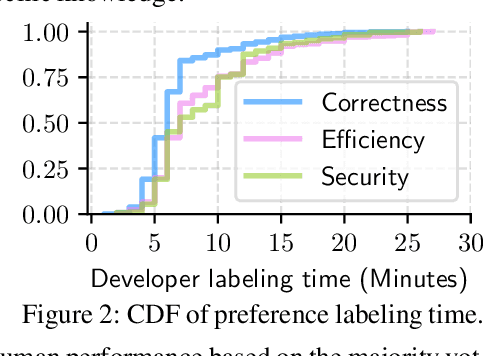
Large Language Models (LLMs) have recently demonstrated remarkable coding capabilities. However, assessing code generation based on well-formed properties and aligning it with developer preferences remains challenging. In this paper, we explore two key questions under the new challenge of code preference learning: (i) How do we train models to predict meaningful preferences for code? and (ii) How do human and LLM preferences align with verifiable code properties and developer code tastes? To this end, we propose CodeFavor, a framework for training pairwise code preference models from synthetic evolution data, including code commits and code critiques. To evaluate code preferences, we introduce CodePrefBench, a benchmark comprising 1364 rigorously curated code preference tasks to cover three verifiable properties-correctness, efficiency, and security-along with human preference. Our evaluation shows that CodeFavor holistically improves the accuracy of model-based code preferences by up to 28.8%. Meanwhile, CodeFavor models can match the performance of models with 6-9x more parameters while being 34x more cost-effective. We also rigorously validate the design choices in CodeFavor via a comprehensive set of controlled experiments. Furthermore, we discover the prohibitive costs and limitations of human-based code preference: despite spending 23.4 person-minutes on each task, 15.1-40.3% of tasks remain unsolved. Compared to model-based preference, human preference tends to be more accurate under the objective of code correctness, while being sub-optimal for non-functional objectives.
Xinyu: An Efficient LLM-based System for Commentary Generation
Aug 21, 2024



Commentary provides readers with a deep understanding of events by presenting diverse arguments and evidence. However, creating commentary is a time-consuming task, even for skilled commentators. Large language models (LLMs) have simplified the process of natural language generation, but their direct application in commentary creation still faces challenges due to unique task requirements. These requirements can be categorized into two levels: 1) fundamental requirements, which include creating well-structured and logically consistent narratives, and 2) advanced requirements, which involve generating quality arguments and providing convincing evidence. In this paper, we introduce Xinyu, an efficient LLM-based system designed to assist commentators in generating Chinese commentaries. To meet the fundamental requirements, we deconstruct the generation process into sequential steps, proposing targeted strategies and supervised fine-tuning (SFT) for each step. To address the advanced requirements, we present an argument ranking model for arguments and establish a comprehensive evidence database that includes up-to-date events and classic books, thereby strengthening the substantiation of the evidence with retrieval augmented generation (RAG) technology. To evaluate the generated commentaries more fairly, corresponding to the two-level requirements, we introduce a comprehensive evaluation metric that considers five distinct perspectives in commentary generation. Our experiments confirm the effectiveness of our proposed system. We also observe a significant increase in the efficiency of commentators in real-world scenarios, with the average time spent on creating a commentary dropping from 4 hours to 20 minutes. Importantly, such an increase in efficiency does not compromise the quality of the commentaries.
$\text{Memory}^3$: Language Modeling with Explicit Memory
Jul 01, 2024



The training and inference of large language models (LLMs) are together a costly process that transports knowledge from raw data to meaningful computation. Inspired by the memory hierarchy of the human brain, we reduce this cost by equipping LLMs with explicit memory, a memory format cheaper than model parameters and text retrieval-augmented generation (RAG). Conceptually, with most of its knowledge externalized to explicit memories, the LLM can enjoy a smaller parameter size, training cost, and inference cost, all proportional to the amount of remaining "abstract knowledge". As a preliminary proof of concept, we train from scratch a 2.4B LLM, which achieves better performance than much larger LLMs as well as RAG models, and maintains higher decoding speed than RAG. The model is named $\text{Memory}^3$, since explicit memory is the third form of memory in LLMs after implicit memory (model parameters) and working memory (context key-values). We introduce a memory circuitry theory to support the externalization of knowledge, and present novel techniques including a memory sparsification mechanism that makes storage tractable and a two-stage pretraining scheme that facilitates memory formation.
FastMem: Fast Memorization of Prompt Improves Context Awareness of Large Language Models
Jun 23, 2024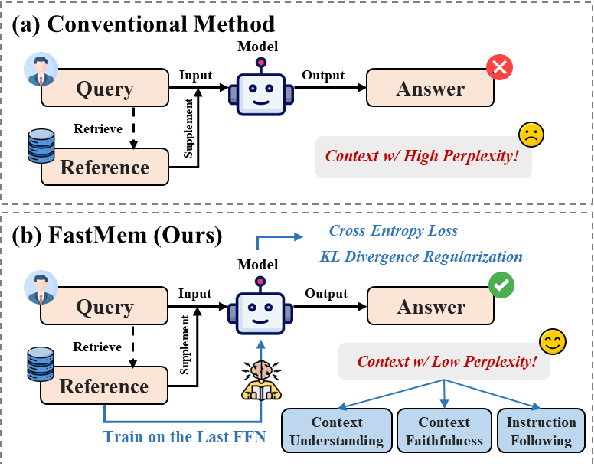
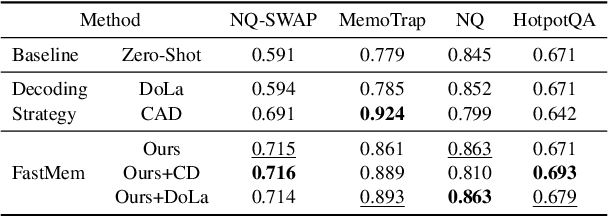
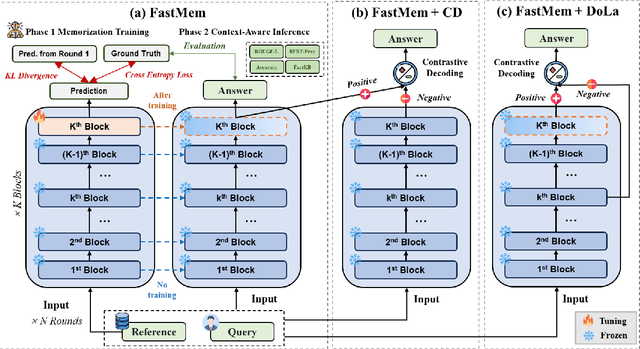
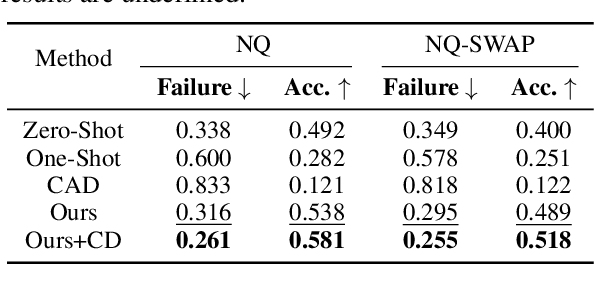
Large language models (LLMs) excel in generating coherent text, but they often struggle with context awareness, leading to inaccuracies in tasks requiring faithful adherence to provided information. We introduce FastMem, a novel method designed to enhance instruction fine-tuned LLMs' context awareness through fast memorization of the prompt. FastMem maximizes the likelihood of the prompt before inference by fine-tuning only the last Feed-Forward Network (FFN) module. This targeted approach ensures efficient optimization without overfitting, significantly improving the model's ability to comprehend and accurately follow the context. Our experiments demonstrate substantial gains in reading comprehension, text summarization and adherence to output structures. For instance, FastMem improves the accuracy of Llama 3-8B-Inst on the NQ-SWAP dataset from 59.1% to 71.6%, and reduces the output structure failure rate of Qwen 1.5-4B-Chat from 34.9% to 25.5%. Extensive experimental results highlight FastMem's potential to offer a robust solution to enhance the reliability and accuracy of LLMs in various applications. Our code is available at: https://github.com/IAAR-Shanghai/FastMem
Knowledge Graph Pruning for Recommendation
May 19, 2024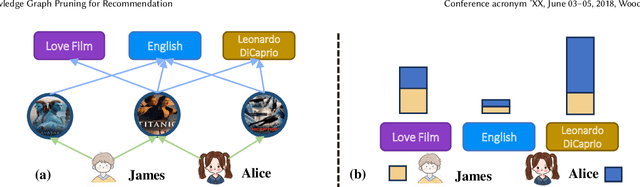
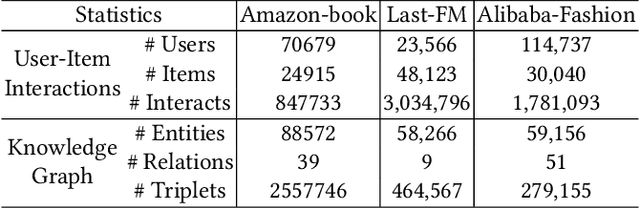
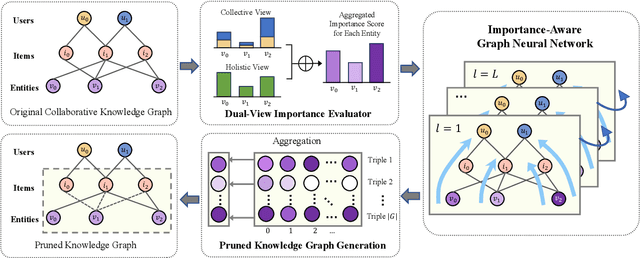
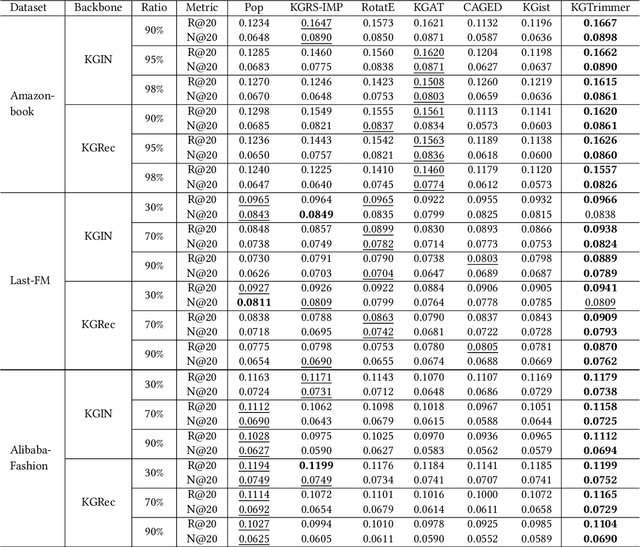
Recent years have witnessed the prosperity of knowledge graph based recommendation system (KGRS), which enriches the representation of users, items, and entities by structural knowledge with striking improvement. Nevertheless, its unaffordable computational cost still limits researchers from exploring more sophisticated models. We observe that the bottleneck for training efficiency arises from the knowledge graph, which is plagued by the well-known issue of knowledge explosion. Recently, some works have attempted to slim the inflated KG via summarization techniques. However, these summarized nodes may ignore the collaborative signals and deviate from the facts that nodes in knowledge graph represent symbolic abstractions of entities from the real-world. To this end, in this paper, we propose a novel approach called KGTrimmer for knowledge graph pruning tailored for recommendation, to remove the unessential nodes while minimizing performance degradation. Specifically, we design an importance evaluator from a dual-view perspective. For the collective view, we embrace the idea of collective intelligence by extracting community consensus based on abundant collaborative signals, i.e. nodes are considered important if they attract attention of numerous users. For the holistic view, we learn a global mask to identify the valueless nodes from their inherent properties or overall popularity. Next, we build an end-to-end importance-aware graph neural network, which injects filtered knowledge to enhance the distillation of valuable user-item collaborative signals. Ultimately, we generate a pruned knowledge graph with lightweight, stable, and robust properties to facilitate the following-up recommendation task. Extensive experiments are conducted on three publicly available datasets to prove the effectiveness and generalization ability of KGTrimmer.