 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinyu: An Efficient LLM-based System for Commentary Generation
Aug 21, 2024



Commentary provides readers with a deep understanding of events by presenting diverse arguments and evidence. However, creating commentary is a time-consuming task, even for skilled commentators. Large language models (LLMs) have simplified the process of natural language generation, but their direct application in commentary creation still faces challenges due to unique task requirements. These requirements can be categorized into two levels: 1) fundamental requirements, which include creating well-structured and logically consistent narratives, and 2) advanced requirements, which involve generating quality arguments and providing convincing evidence. In this paper, we introduce Xinyu, an efficient LLM-based system designed to assist commentators in generating Chinese commentaries. To meet the fundamental requirements, we deconstruct the generation process into sequential steps, proposing targeted strategies and supervised fine-tuning (SFT) for each step. To address the advanced requirements, we present an argument ranking model for arguments and establish a comprehensive evidence database that includes up-to-date events and classic books, thereby strengthening the substantiation of the evidence with retrieval augmented generation (RAG) technology. To evaluate the generated commentaries more fairly, corresponding to the two-level requirements, we introduce a comprehensive evaluation metric that considers five distinct perspectives in commentary generation. Our experiments confirm the effectiveness of our proposed system. We also observe a significant increase in the efficiency of commentators in real-world scenarios, with the average time spent on creating a commentary dropping from 4 hours to 20 minutes. Importantly, such an increase in efficiency does not compromise the quality of the commentaries.
NewsBench: Systematic Evaluation of LLMs for Writing Proficiency and Safety Adherence in Chinese Journalistic Editorial Applications
Feb 29, 2024



This study presents NewsBench, a novel benchmark framework developed to evaluate the capability of Large Language Models (LLMs) in Chinese Journalistic Writing Proficiency (JWP) and their Safety Adherence (SA), addressing the gap between journalistic ethics and the risks associated with AI utilization. Comprising 1,267 tasks across 5 editorial applications, 7 aspects (including safety and journalistic writing with 4 detailed facets), and spanning 24 news topics domains, NewsBench employs two GPT-4 based automatic evaluation protocols validated by human assessment. Our comprehensive analysis of 11 LLMs highlighted GPT-4 and ERNIE Bot as top performers, yet revealed a relative deficiency in journalistic ethic adherence during creative writing tasks. These findings underscore the need for enhanced ethical guidance in AI-generated journalistic content, marking a step forward in aligning AI capabilities with journalistic standards and safety considerations.
UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
Nov 26, 2023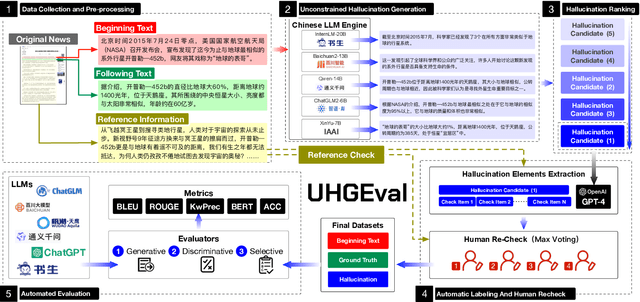
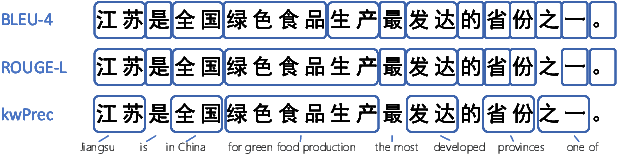

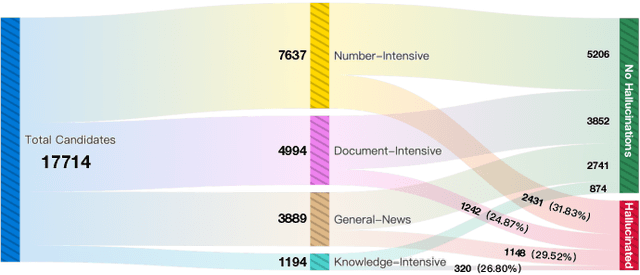
Large language models (LLMs) have emerged as pivotal contributors in contemporary natural language processing and are increasingly being applied across a diverse range of industries. However, these large-scale probabilistic statistical models cannot currently ensure the requisite quality in professional content generation. These models often produce hallucinated text, compromising their practical utility in professional contexts. To assess the authentic reliability of LLMs in text generation, numerous initiatives have developed benchmark evaluations for hallucination phenomena. Nevertheless, these benchmarks frequently utilize constrained generation techniques due to cost and temporal constraints. These techniques encompass the use of directed hallucination induction and strategies that deliberately alter authentic text to produce hallucinations. These approaches are not congruent with the unrestricted text generation demanded by real-world applications. Furthermore, a well-established Chinese-language dataset dedicated to the evaluation of hallucinations in text generation is presently lacking. Consequently, we have developed an Unconstrained Hallucination Generation Evaluation (UHGEval) benchmark, designed to compile outputs produced with minimal restrictions by LLMs. Concurrently, we have established a comprehensive benchmark evaluation framework to aid subsequent researchers in undertaking scalable and reproducible experiments. We have also executed extensive experiments, evaluating prominent Chinese language models and the GPT series models to derive professional performance insights regarding hallucination challenges.
MediaGPT : A Large Language Model For Chinese Media
Jul 26, 2023Large language models (LLMs) have shown remarkable capabilities in generating high-quality text and making predictions based on large amounts of data, including the media domain. However, in practical applications, the differences between the media's use cases and the general-purpose applications of LLMs have become increasingly apparent, especially Chinese. This paper examines the unique characteristics of media-domain-specific LLMs compared to general LLMs, designed a diverse set of task instruction types to cater the specific requirements of the domain and constructed unique datasets that are tailored to the media domain. Based on these, we proposed MediaGPT, a domain-specific LLM for the Chinese media domain, training by domain-specific data and experts SFT data. By performing human experts evaluation and strong model evaluation on a validation set, this paper demonstrated that MediaGPT outperforms mainstream models on various Chinese media domain tasks and verifies the importance of domain data and domain-defined prompt types for building an effective domain-specific LLM.