 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemReader: From Passive to Active Extraction for Long-Term Agent Memory
Apr 09, 2026Long-term memory is fundamental for personalized and autonomous agents, yet populating it remains a bottleneck. Existing systems treat memory extraction as a one-shot, passive transcription from context to structured entries, which struggles with noisy dialogue, missing references, and cross-turn dependencies, leading to memory pollution, low-value writes, and inconsistency. In this paper, we introduce the MemReader family for active long-term memory extraction in agent systems: MemReader-0.6B, a compact and cost-efficient passive extractor distilled for accurate and schema-consistent structured outputs, and MemReader-4B, an active extractor optimized with Group Relative Policy Optimization (GRPO) to make memory writing decisions. Under a ReAct-style paradigm, MemReader-4B explicitly evaluates information value, reference ambiguity, and completeness before acting, and can selectively write memories, defer incomplete inputs, retrieve historical context, or discard irrelevant chatter. Experiments on LOCOMO, LongMemEval, and HaluMem show that MemReader consistently outperforms existing extraction-based baselines. In particular, MemReader-4B achieves state-of-the-art performance on tasks involving knowledge updating, temporal reasoning, and hallucination reduction. These results suggest that effective agent memory requires not merely extracting more information, but performing reasoning-driven and selective memory extraction to build low-noise and dynamically evolving long-term memory. Furthermore, MemReader has been integrated into MemOS and is being deployed in real-world applications. To support future research and adoption, we release the models and provide public API access.
MemFactory: Unified Inference & Training Framework for Agent Memory
Apr 02, 2026Memory-augmented Large Language Models (LLMs) are essential for developing capable, long-term AI agents. Recently, applying Reinforcement Learning (RL) to optimize memory operations, such as extraction, updating, and retrieval, has emerged as a highly promising research direction. However, existing implementations remain highly fragmented and task-specific, lacking a unified infrastructure to streamline the integration, training, and evaluation of these complex pipelines. To address this gap, we present MemFactory, the first unified, highly modular training and inference framework specifically designed for memory-augmented agents. Inspired by the success of unified fine-tuning frameworks like LLaMA-Factory, MemFactory abstracts the memory lifecycle into atomic, plug-and-play components, enabling researchers to seamlessly construct custom memory agents via a "Lego-like" architecture. Furthermore, the framework natively integrates Group Relative Policy Optimization (GRPO) to fine-tune internal memory management policies driven by multi-dimensional environmental rewards. MemFactory provides out-of-the-box support for recent cutting-edge paradigms, including Memory-R1, RMM, and MemAgent. We empirically validate MemFactory on the open-source MemAgent architecture using its publicly available training and evaluation data. Across the evaluation sets, MemFactory improves performance over the corresponding base models on average, with relative gains of up to 14.8%. By providing a standardized, extensible, and easy-to-use infrastructure, MemFactory significantly lowers the barrier to entry, paving the way for future innovations in memory-driven AI agents.
PERMA: Benchmarking Personalized Memory Agents via Event-Driven Preference and Realistic Task Environments
Mar 24, 2026Empowering large language models with long-term memory is crucial for building agents that adapt to users' evolving needs. However, prior evaluations typically interleave preference-related dialogues with irrelevant conversations, reducing the task to needle-in-a-haystack retrieval while ignoring relationships between events that drive the evolution of user preferences. Such settings overlook a fundamental characteristic of real-world personalization: preferences emerge gradually and accumulate across interactions within noisy contexts. To bridge this gap, we introduce PERMA, a benchmark designed to evaluate persona consistency over time beyond static preference recall. Additionally, we incorporate (1) text variability and (2) linguistic alignment to simulate erratic user inputs and individual idiolects in real-world data. PERMA consists of temporally ordered interaction events spanning multiple sessions and domains, with preference-related queries inserted over time. We design both multiple-choice and interactive tasks to probe the model's understanding of persona along the interaction timeline. Experiments demonstrate that by linking related interactions, advanced memory systems can extract more precise preferences and reduce token consumption, outperforming traditional semantic retrieval of raw dialogues. Nevertheless, they still struggle to maintain a coherent persona across temporal depth and cross-domain interference, highlighting the need for more robust personalized memory management in agents. Our code and data are open-sourced at https://github.com/PolarisLiu1/PERMA.
AutoAgent: Evolving Cognition and Elastic Memory Orchestration for Adaptive Agents
Mar 10, 2026Autonomous agent frameworks still struggle to reconcile long-term experiential learning with real-time, context-sensitive decision-making. In practice, this gap appears as static cognition, rigid workflow dependence, and inefficient context usage, which jointly limit adaptability in open-ended and non-stationary environments. To address these limitations, we present AutoAgent, a self-evolving multi-agent framework built on three tightly coupled components: evolving cognition, on-the-fly contextual decision-making, and elastic memory orchestration. At the core of AutoAgent, each agent maintains structured prompt-level cognition over tools, self-capabilities, peer expertise, and task knowledge. During execution, this cognition is combined with live task context to select actions from a unified space that includes tool calls, LLM-based generation, and inter-agent requests. To support efficient long-horizon reasoning, an Elastic Memory Orchestrator dynamically organizes interaction history by preserving raw records, compressing redundant trajectories, and constructing reusable episodic abstractions, thereby reducing token overhead while retaining decision-critical evidence. These components are integrated through a closed-loop cognitive evolution process that aligns intended actions with observed outcomes to continuously update cognition and expand reusable skills, without external retraining. Empirical results across retrieval-augmented reasoning, tool-augmented agent benchmarks, and embodied task environments show that AutoAgent consistently improves task success, tool-use efficiency, and collaborative robustness over static and memory-augmented baselines. Overall, AutoAgent provides a unified and practical foundation for adaptive autonomous agents that must learn from experience while making reliable context-aware decisions in dynamic environments.
Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
Jan 27, 2026We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.
Inside Out: Evolving User-Centric Core Memory Trees for Long-Term Personalized Dialogue Systems
Jan 08, 2026Existing long-term personalized dialogue systems struggle to reconcile unbounded interaction streams with finite context constraints, often succumbing to memory noise accumulation, reasoning degradation, and persona inconsistency. To address these challenges, this paper proposes Inside Out, a framework that utilizes a globally maintained PersonaTree as the carrier of long-term user profiling. By constraining the trunk with an initial schema and updating the branches and leaves, PersonaTree enables controllable growth, achieving memory compression while preserving consistency. Moreover, we train a lightweight MemListener via reinforcement learning with process-based rewards to produce structured, executable, and interpretable {ADD, UPDATE, DELETE, NO_OP} operations, thereby supporting the dynamic evolution of the personalized tree. During response generation, PersonaTree is directly leveraged to enhance outputs in latency-sensitive scenarios; when users require more details, the agentic mode is triggered to introduce details on-demand under the constraints of the PersonaTree. Experiments show that PersonaTree outperforms full-text concatenation and various personalized memory systems in suppressing contextual noise and maintaining persona consistency. Notably, the small MemListener model achieves memory-operation decision performance comparable to, or even surpassing, powerful reasoning models such as DeepSeek-R1-0528 and Gemini-3-Pro.
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
Jan 06, 2026The hallmark of human intelligence is the ability to master new skills through Constructive Episodic Simulation-retrieving past experiences to synthesize solutions for novel tasks. While Large Language Models possess strong reasoning capabilities, they struggle to emulate this self-evolution: fine-tuning is computationally expensive and prone to catastrophic forgetting, while existing memory-based methods rely on passive semantic matching that often retrieves noise. To address these challenges, we propose MemRL, a framework that enables agents to self-evolve via non-parametric reinforcement learning on episodic memory. MemRL explicitly separates the stable reasoning of a frozen LLM from the plastic, evolving memory. Unlike traditional methods, MemRL employs a Two-Phase Retrieval mechanism that filters candidates by semantic relevance and then selects them based on learned Q-values (utility). These utilities are continuously refined via environmental feedback in an trial-and-error manner, allowing the agent to distinguish high-value strategies from similar noise. Extensive experiments on HLE, BigCodeBench, ALFWorld, and Lifelong Agent Bench demonstrate that MemRL significantly outperforms state-of-the-art baselines. Our analysis experiments confirm that MemRL effectively reconciles the stability-plasticity dilemma, enabling continuous runtime improvement without weight updates.
TAdaRAG: Task Adaptive Retrieval-Augmented Generation via On-the-Fly Knowledge Graph Construction
Nov 16, 2025Retrieval-Augmented Generation (RAG) improves large language models by retrieving external knowledge, often truncated into smaller chunks due to the input context window, which leads to information loss, resulting in response hallucinations and broken reasoning chains. Moreover, traditional RAG retrieves unstructured knowledge, introducing irrelevant details that hinder accurate reasoning. To address these issues, we propose TAdaRAG, a novel RAG framework for on-the-fly task-adaptive knowledge graph construction from external sources. Specifically, we design an intent-driven routing mechanism to a domain-specific extraction template, followed by supervised fine-tuning and a reinforcement learning-based implicit extraction mechanism, ensuring concise, coherent, and non-redundant knowledge integration. Evaluations on six public benchmarks and a real-world business benchmark (NowNewsQA) across three backbone models demonstrate that TAdaRAG outperforms existing methods across diverse domains and long-text tasks, highlighting its strong generalization and practical effectiveness.
HaluMem: Evaluating Hallucinations in Memory Systems of Agents
Nov 05, 2025Memory systems are key components that enable AI systems such as LLMs and AI agents to achieve long-term learning and sustained interaction. However, during memory storage and retrieval, these systems frequently exhibit memory hallucinations, including fabrication, errors, conflicts, and omissions. Existing evaluations of memory hallucinations are primarily end-to-end question answering, which makes it difficult to localize the operational stage within the memory system where hallucinations arise. To address this, we introduce the Hallucination in Memory Benchmark (HaluMem), the first operation level hallucination evaluation benchmark tailored to memory systems. HaluMem defines three evaluation tasks (memory extraction, memory updating, and memory question answering) to comprehensively reveal hallucination behaviors across different operational stages of interaction. To support evaluation, we construct user-centric, multi-turn human-AI interaction datasets, HaluMem-Medium and HaluMem-Long. Both include about 15k memory points and 3.5k multi-type questions. The average dialogue length per user reaches 1.5k and 2.6k turns, with context lengths exceeding 1M tokens, enabling evaluation of hallucinations across different context scales and task complexities. Empirical studies based on HaluMem show that existing memory systems tend to generate and accumulate hallucinations during the extraction and updating stages, which subsequently propagate errors to the question answering stage. Future research should focus on developing interpretable and constrained memory operation mechanisms that systematically suppress hallucinations and improve memory reliability.
MoM: Mixtures of Scenario-Aware Document Memories for Retrieval-Augmented Generation Systems
Oct 16, 2025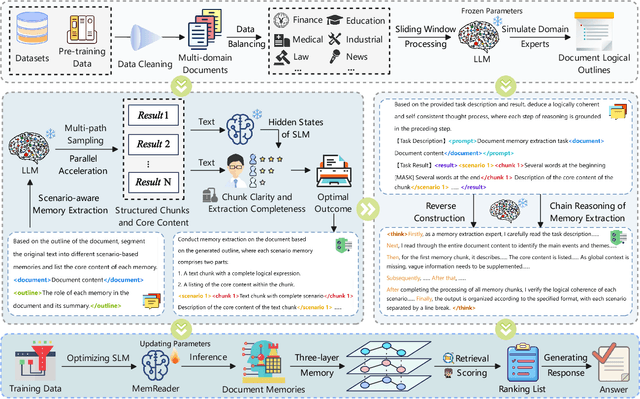
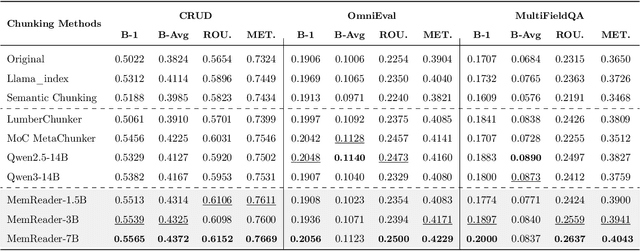
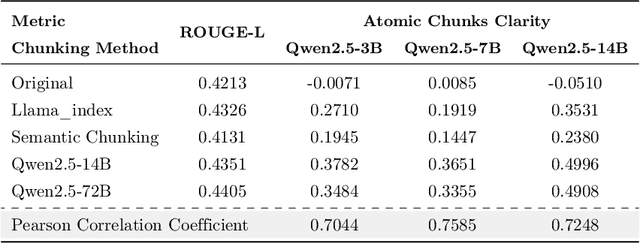
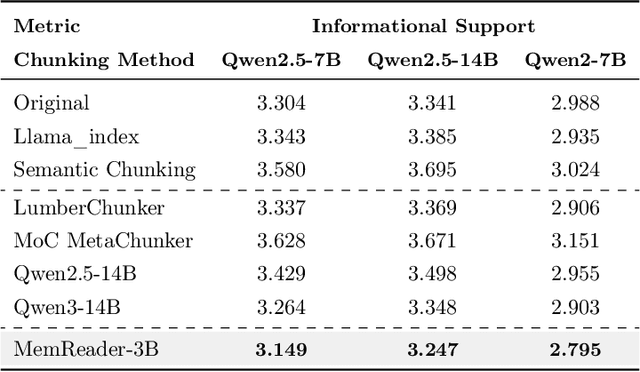
The traditional RAG paradigm, which typically engages in the comprehension of relevant text chunks in response to received queries, inherently restricts both the depth of knowledge internalization and reasoning capabilities. To address this limitation, our research transforms the text processing in RAG from passive chunking to proactive understanding, defining this process as document memory extraction with the objective of simulating human cognitive processes during reading. Building upon this, we propose the Mixtures of scenario-aware document Memories (MoM) framework, engineered to efficiently handle documents from multiple domains and train small language models (SLMs) to acquire the ability to proactively explore and construct document memories. The MoM initially instructs large language models (LLMs) to simulate domain experts in generating document logical outlines, thereby directing structured chunking and core content extraction. It employs a multi-path sampling and multi-perspective evaluation mechanism, specifically designing comprehensive metrics that represent chunk clarity and extraction completeness to select the optimal document memories. Additionally, to infuse deeper human-like reading abilities during the training of SLMs, we incorporate a reverse reasoning strategy, which deduces refined expert thinking paths from high-quality outcomes. Finally, leveraging diverse forms of content generated by MoM, we develop a three-layer document memory retrieval mechanism, which is grounded in our theoretical proof from the perspective of probabilistic modeling. Extensive experimental results across three distinct domains demonstrate that the MoM framework not only resolves text chunking challenges in existing RAG systems, providing LLMs with semantically complete document memories, but also paves the way for SLMs to achieve human-centric intelligent text processing.