 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn overview of condensation phenomenon in deep learning
Apr 13, 2025In this paper, we provide an overview of a common phenomenon, condensation, observed during the nonlinear training of neural networks: During the nonlinear training of neural networks, neurons in the same layer tend to condense into groups with similar outputs. Empirical observations suggest that the number of condensed clusters of neurons in the same layer typically increases monotonically as training progresses. Neural networks with small weight initializations or Dropout optimization can facilitate this condensation process. We also examine the underlying mechanisms of condensation from the perspectives of training dynamics and the structure of the loss landscape. The condensation phenomenon offers valuable insights into the generalization abilities of neural networks and correlates to stronger reasoning abilities in transformer-based language models.
A rationale from frequency perspective for grokking in training neural network
May 24, 2024



Grokking is the phenomenon where neural networks NNs initially fit the training data and later generalize to the test data during training. In this paper, we empirically provide a frequency perspective to explain the emergence of this phenomenon in NNs. The core insight is that the networks initially learn the less salient frequency components present in the test data. We observe this phenomenon across both synthetic and real datasets, offering a novel viewpoint for elucidating the grokking phenomenon by characterizing it through the lens of frequency dynamics during the training process. Our empirical frequency-based analysis sheds new light on understanding the grokking phenomenon and its underlying mechanisms.
Towards Understanding How Transformer Perform Multi-step Reasoning with Matching Operation
May 24, 2024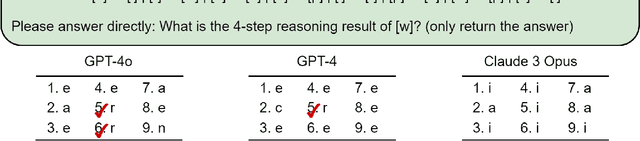
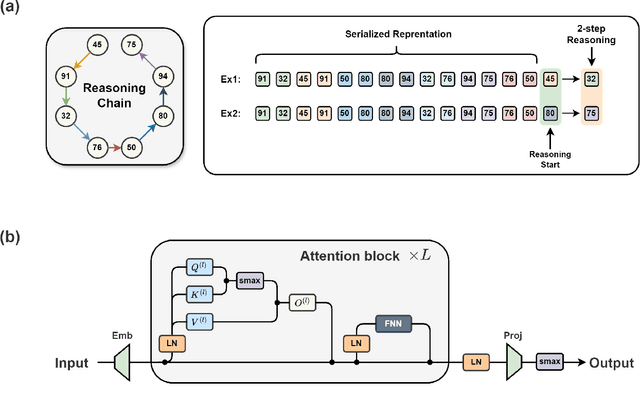
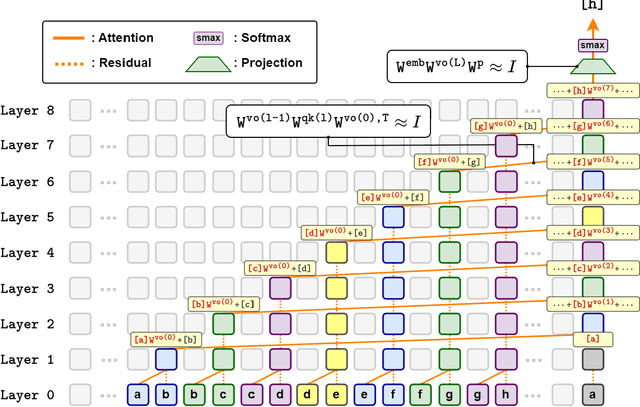
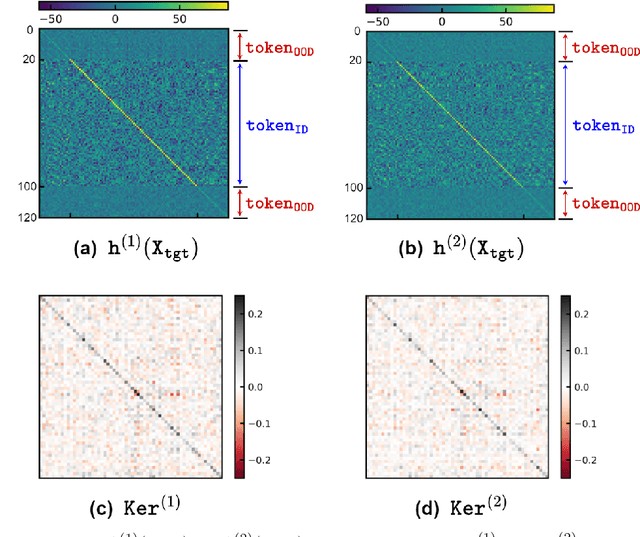
Large language models have consistently struggled with complex reasoning tasks, such as mathematical problem-solving. Investigating the internal reasoning mechanisms of these models can help us design better model architectures and training strategies, ultimately enhancing their reasoning capabilities. In this study, we examine the matching mechanism employed by Transformer for multi-step reasoning on a constructed dataset. We investigate factors that influence the model's matching mechanism and discover that small initialization and post-LayerNorm can facilitate the formation of the matching mechanism, thereby enhancing the model's reasoning ability. Moreover, we propose a method to improve the model's reasoning capability by adding orthogonal noise. Finally, we investigate the parallel reasoning mechanism of Transformers and propose a conjecture on the upper bound of the model's reasoning ability based on this phenomenon. These insights contribute to a deeper understanding of the reasoning processes in large language models and guide designing more effective reasoning architectures and training strategies.
Anchor function: a type of benchmark functions for studying language models
Jan 16, 2024Understanding transformer-based language models is becoming increasingly crucial, particularly as they play pivotal roles in advancing towards artificial general intelligence. However, language model research faces significant challenges, especially for academic research groups with constrained resources. These challenges include complex data structures, unknown target functions, high computational costs and memory requirements, and a lack of interpretability in the inference process, etc. Drawing a parallel to the use of simple models in scientific research, we propose the concept of an anchor function. This is a type of benchmark function designed for studying language models in learning tasks that follow an "anchor-key" pattern. By utilizing the concept of an anchor function, we can construct a series of functions to simulate various language tasks. The anchor function plays a role analogous to that of mice in diabetes research, particularly suitable for academic research. We demonstrate the utility of the anchor function with an example, revealing two basic operations by attention structures in language models: shifting tokens and broadcasting one token from one position to many positions. These operations are also commonly observed in large language models. The anchor function framework, therefore, opens up a series of valuable and accessible research questions for further exploration, especially for theoretical study.
Understanding the Initial Condensation of Convolutional Neural Networks
May 17, 2023Previous research has shown that fully-connected networks with small initialization and gradient-based training methods exhibit a phenomenon known as condensation during training. This phenomenon refers to the input weights of hidden neurons condensing into isolated orientations during training, revealing an implicit bias towards simple solutions in the parameter space. However, the impact of neural network structure on condensation has not been investigated yet. In this study, we focus on the investigation of convolutional neural networks (CNNs). Our experiments suggest that when subjected to small initialization and gradient-based training methods, kernel weights within the same CNN layer also cluster together during training, demonstrating a significant degree of condensation. Theoretically, we demonstrate that in a finite training period, kernels of a two-layer CNN with small initialization will converge to one or a few directions. This work represents a step towards a better understanding of the non-linear training behavior exhibited by neural networks with specialized structures.
Phase Diagram of Initial Condensation for Two-layer Neural Networks
Mar 12, 2023


The phenomenon of distinct behaviors exhibited by neural networks under varying scales of initialization remains an enigma in deep learning research. In this paper, based on the earlier work by Luo et al.~\cite{luo2021phase}, we present a phase diagram of initial condensation for two-layer neural networks. Condensation is a phenomenon wherein the weight vectors of neural networks concentrate on isolated orientations during the training process, and it is a feature in non-linear learning process that enables neural networks to possess better generalization abilities. Our phase diagram serves to provide a comprehensive understanding of the dynamical regimes of neural networks and their dependence on the choice of hyperparameters related to initialization. Furthermore, we demonstrate in detail the underlying mechanisms by which small initialization leads to condensation at the initial training stage.