 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Initial Condensation of Convolutional Neural Networks
Paper and Code
May 17, 2023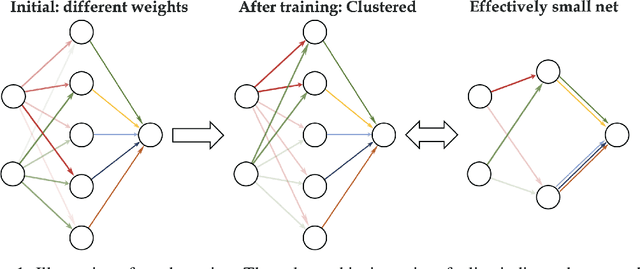
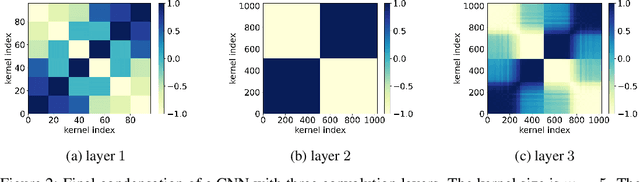
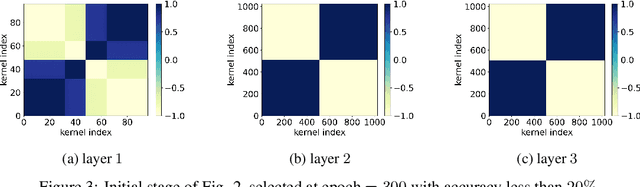
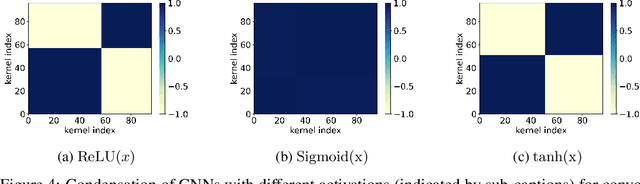
Previous research has shown that fully-connected networks with small initialization and gradient-based training methods exhibit a phenomenon known as condensation during training. This phenomenon refers to the input weights of hidden neurons condensing into isolated orientations during training, revealing an implicit bias towards simple solutions in the parameter space. However, the impact of neural network structure on condensation has not been investigated yet. In this study, we focus on the investigation of convolutional neural networks (CNNs). Our experiments suggest that when subjected to small initialization and gradient-based training methods, kernel weights within the same CNN layer also cluster together during training, demonstrating a significant degree of condensation. Theoretically, we demonstrate that in a finite training period, kernels of a two-layer CNN with small initialization will converge to one or a few directions. This work represents a step towards a better understanding of the non-linear training behavior exhibited by neural networks with specialized structures.