 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite-box Multimodal Jailbreaks Against Large Vision-Language Models
May 28, 2024



Recent advancements in Large Vision-Language Models (VLMs) have underscored their superiority in various multimodal tasks. However, the adversarial robustness of VLMs has not been fully explored. Existing methods mainly assess robustness through unimodal adversarial attacks that perturb images, while assuming inherent resilience against text-based attacks. Different from existing attacks, in this work we propose a more comprehensive strategy that jointly attacks both text and image modalities to exploit a broader spectrum of vulnerability within VLMs. Specifically, we propose a dual optimization objective aimed at guiding the model to generate affirmative responses with high toxicity. Our attack method begins by optimizing an adversarial image prefix from random noise to generate diverse harmful responses in the absence of text input, thus imbuing the image with toxic semantics. Subsequently, an adversarial text suffix is integrated and co-optimized with the adversarial image prefix to maximize the probability of eliciting affirmative responses to various harmful instructions. The discovered adversarial image prefix and text suffix are collectively denoted as a Universal Master Key (UMK). When integrated into various malicious queries, UMK can circumvent the alignment defenses of VLMs and lead to the generation of objectionable content, known as jailbreaks. The experimental results demonstrate that our universal attack strategy can effectively jailbreak MiniGPT-4 with a 96% success rate, highlighting the vulnerability of VLMs and the urgent need for new alignment strategies.
Understanding Time Series Anomaly State Detection through One-Class Classification
Feb 03, 2024



For a long time, research on time series anomaly detection has mainly focused on finding outliers within a given time series. Admittedly, this is consistent with some practical problems, but in other practical application scenarios, people are concerned about: assuming a standard time series is given, how to judge whether another test time series deviates from the standard time series, which is more similar to the problem discussed in one-class classification (OCC). Therefore, in this article, we try to re-understand and define the time series anomaly detection problem through OCC, which we call 'time series anomaly state detection problem'. We first use stochastic processes and hypothesis testing to strictly define the 'time series anomaly state detection problem', and its corresponding anomalies. Then, we use the time series classification dataset to construct an artificial dataset corresponding to the problem. We compile 38 anomaly detection algorithms and correct some of the algorithms to adapt to handle this problem. Finally, through a large number of experiments, we fairly compare the actual performance of various time series anomaly detection algorithms, providing insights and directions for future research by researchers.
Understanding the Initial Condensation of Convolutional Neural Networks
May 17, 2023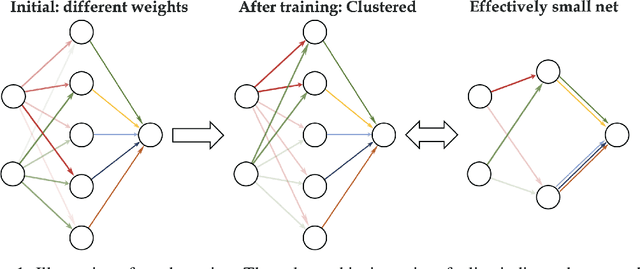
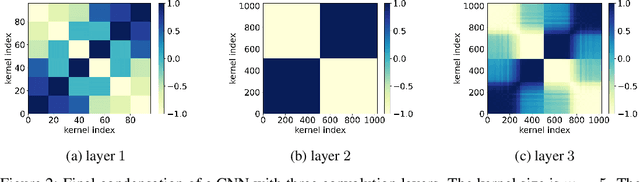
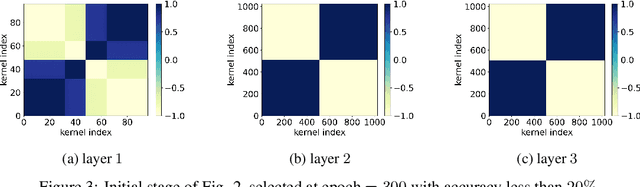
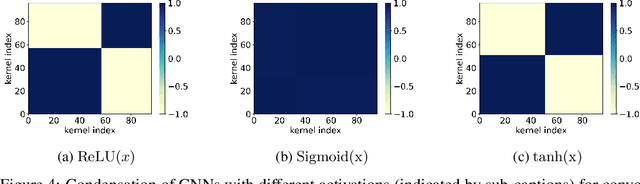
Previous research has shown that fully-connected networks with small initialization and gradient-based training methods exhibit a phenomenon known as condensation during training. This phenomenon refers to the input weights of hidden neurons condensing into isolated orientations during training, revealing an implicit bias towards simple solutions in the parameter space. However, the impact of neural network structure on condensation has not been investigated yet. In this study, we focus on the investigation of convolutional neural networks (CNNs). Our experiments suggest that when subjected to small initialization and gradient-based training methods, kernel weights within the same CNN layer also cluster together during training, demonstrating a significant degree of condensation. Theoretically, we demonstrate that in a finite training period, kernels of a two-layer CNN with small initialization will converge to one or a few directions. This work represents a step towards a better understanding of the non-linear training behavior exhibited by neural networks with specialized structures.
Empirical Phase Diagram for Three-layer Neural Networks with Infinite Width
May 24, 2022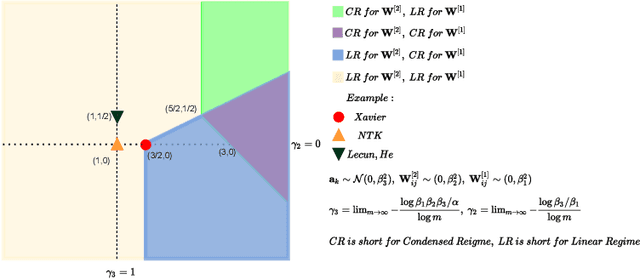

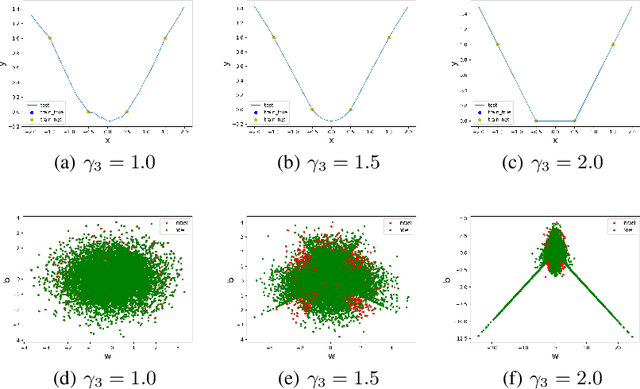
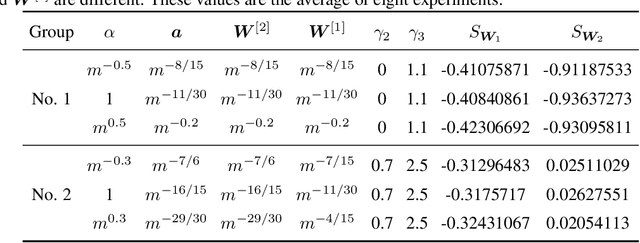
Substantial work indicates that the dynamics of neural networks (NNs) is closely related to their initialization of parameters. Inspired by the phase diagram for two-layer ReLU NNs with infinite width (Luo et al., 2021), we make a step towards drawing a phase diagram for three-layer ReLU NNs with infinite width. First, we derive a normalized gradient flow for three-layer ReLU NNs and obtain two key independent quantities to distinguish different dynamical regimes for common initialization methods. With carefully designed experiments and a large computation cost, for both synthetic datasets and real datasets, we find that the dynamics of each layer also could be divided into a linear regime and a condensed regime, separated by a critical regime. The criteria is the relative change of input weights (the input weight of a hidden neuron consists of the weight from its input layer to the hidden neuron and its bias term) as the width approaches infinity during the training, which tends to $0$, $+\infty$ and $O(1)$, respectively. In addition, we also demonstrate that different layers can lie in different dynamical regimes in a training process within a deep NN. In the condensed regime, we also observe the condensation of weights in isolated orientations with low complexity. Through experiments under three-layer condition, our phase diagram suggests a complicated dynamical regimes consisting of three possible regimes, together with their mixture, for deep NNs and provides a guidance for studying deep NNs in different initialization regimes, which reveals the possibility of completely different dynamics emerging within a deep NN for its different layers.
A variance principle explains why dropout finds flatter minima
Nov 01, 2021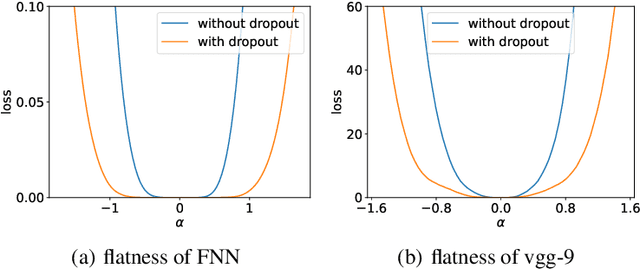
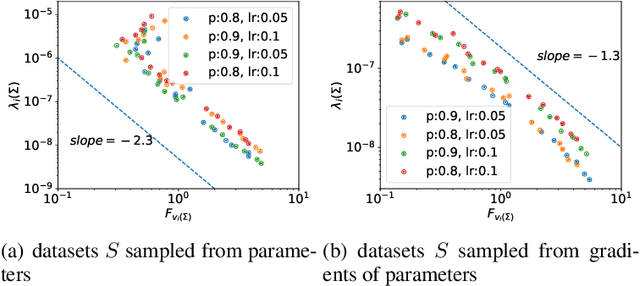
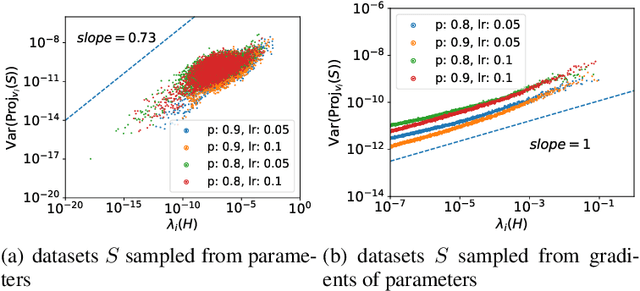
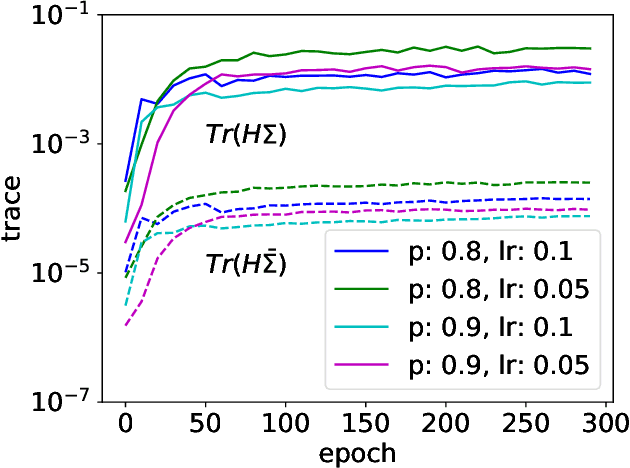
Although dropout has achieved great success in deep learning, little is known about how it helps the training find a good generalization solution in the high-dimensional parameter space. In this work, we show that the training with dropout finds the neural network with a flatter minimum compared with standard gradient descent training. We further study the underlying mechanism of why dropout finds flatter minima through experiments. We propose a {\it Variance Principle} that the variance of a noise is larger at the sharper direction of the loss landscape. Existing works show that SGD satisfies the variance principle, which leads the training to flatter minima. Our work show that the noise induced by the dropout also satisfies the variance principle that explains why dropout finds flatter minima. In general, our work points out that the variance principle is an important similarity between dropout and SGD that lead the training to find flatter minima and obtain good generalization.
Towards Understanding the Condensation of Two-layer Neural Networks at Initial Training
May 29, 2021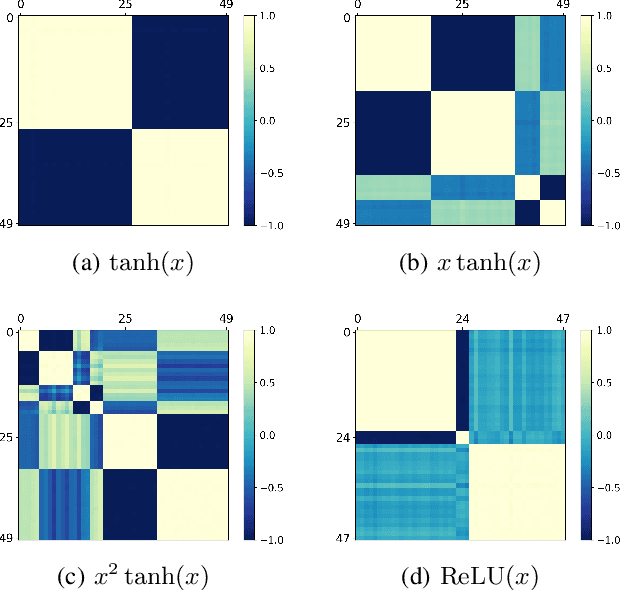
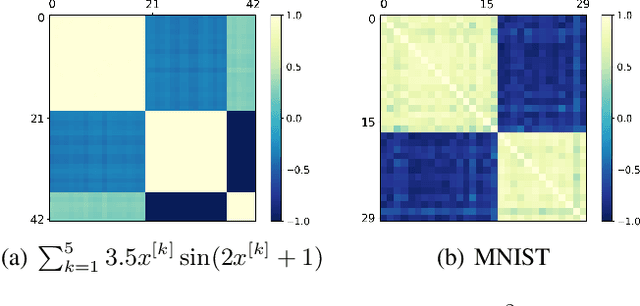
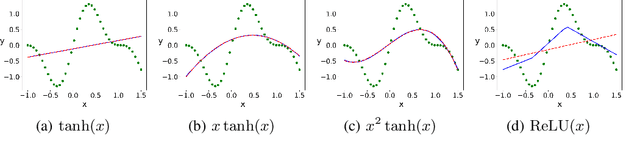
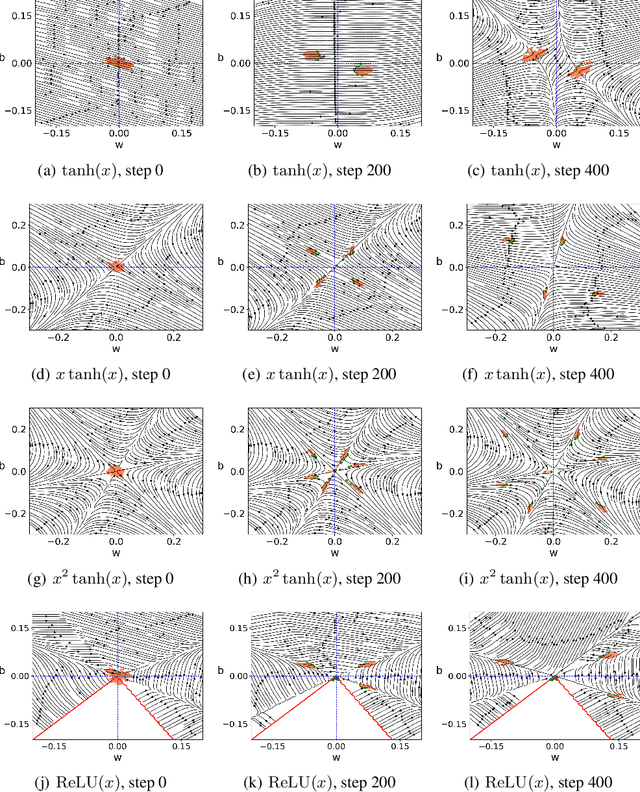
It is important to study what implicit regularization is imposed on the loss function during the training that leads over-parameterized neural networks (NNs) to good performance on real dataset. Empirically, existing works have shown that weights of NNs condense on isolated orientations with small initialization. The condensation implies that the NN learns features from the training data and is effectively a much smaller network. In this work, we show that the singularity of the activation function at original point is a key factor to understanding the condensation at initial training stage. Our experiments suggest that the maximal number of condensed orientations is twice of the singularity order. Our theoretical analysis confirms experiments for two cases, one is for the first-order singularity activation function and the other is for the one-dimensional input. This work takes a step towards understanding how small initialization implicitly leads NNs to condensation at initial training, which is crucial to understand the training and the learning of deep NNs.
Deep frequency principle towards understanding why deeper learning is faster
Jul 28, 2020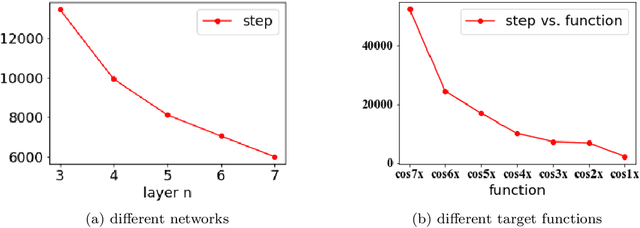
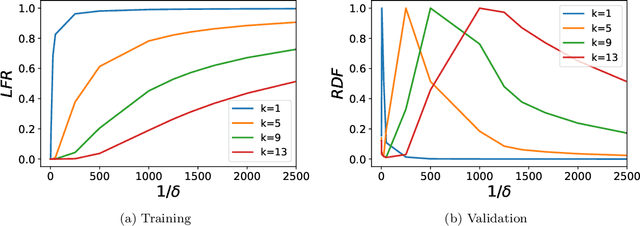
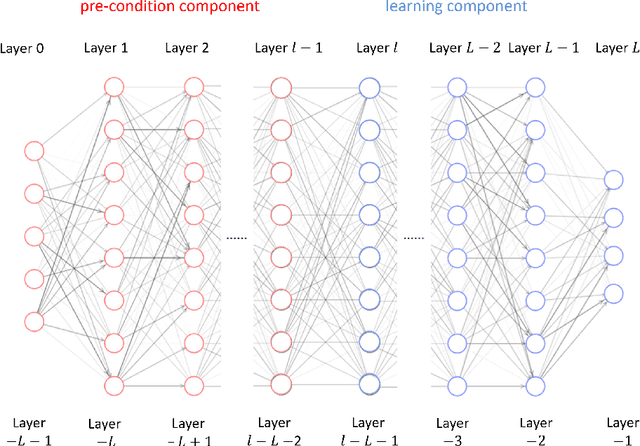
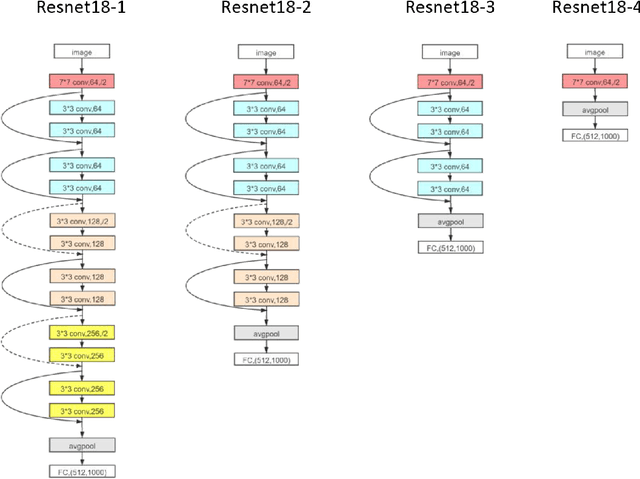
Understanding the effect of depth in deep learning is a critical problem. In this work, we utilize the Fourier analysis to empirically provide a promising mechanism to understand why deeper learning is faster. To this end, we separate a deep neural network into two parts, one is a pre-condition component and the other is a learning component, in which the output of the pre-condition one is the input of the learning one. Based on experiments of deep networks and real dataset, we propose a deep frequency principle, that is, the effective target function for a deeper hidden layer has a bias towards a function with more low frequency during the training. Therefore, the learning component effectively learns a lower frequency function if the pre-condition component has more layers. Due to the well-studied frequency principle, i.e., deep neural networks learn lower frequency functions faster, the deep frequency principle provides a reasonable explanation to why deeper learning is faster. We believe these empirical studies would be valuable for future theoretical studies of the effect of depth in deep learning.