 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Browser-Use Learning for Agentic Information Seeking
Dec 29, 2025Information-seeking (IS) agents have achieved strong performance across a range of wide and deep search tasks, yet their tool use remains largely restricted to API-level snippet retrieval and URL-based page fetching, limiting access to the richer information available through real browsing. While full browser interaction could unlock deeper capabilities, its fine-grained control and verbose page content returns introduce substantial complexity for ReAct-style function-calling agents. To bridge this gap, we propose Nested Browser-Use Learning (NestBrowse), which introduces a minimal and complete browser-action framework that decouples interaction control from page exploration through a nested structure. This design simplifies agentic reasoning while enabling effective deep-web information acquisition. Empirical results on challenging deep IS benchmarks demonstrate that NestBrowse offers clear benefits in practice. Further in-depth analyses underscore its efficiency and flexibility.
Scaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
Sep 16, 2025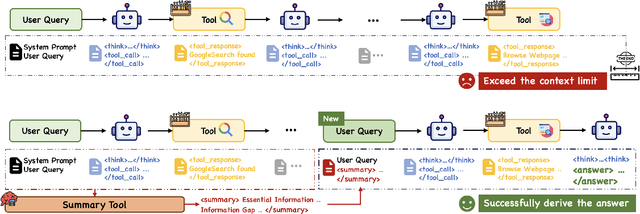
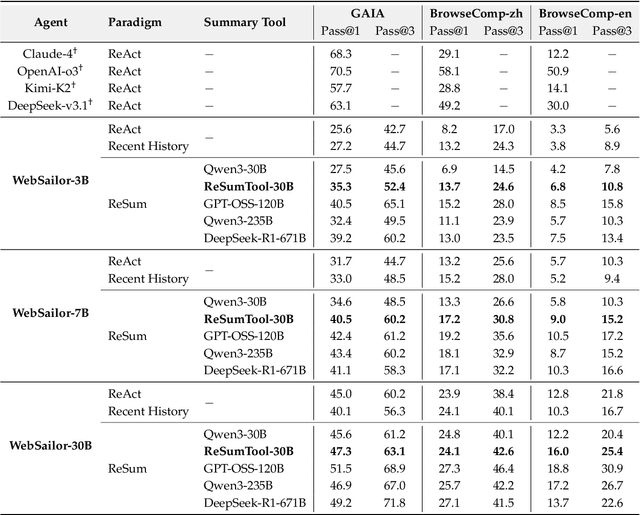
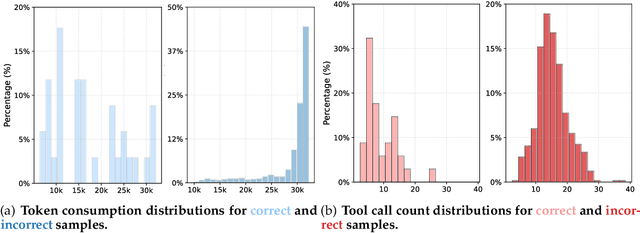
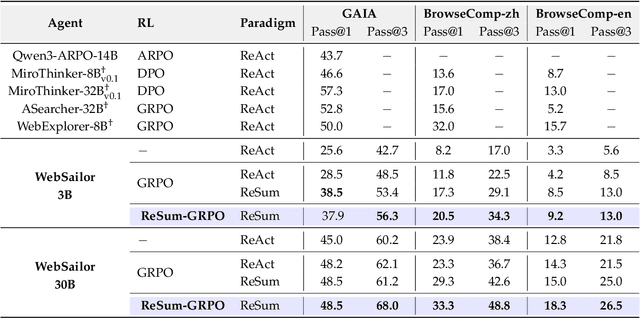
Large Language Model (LLM)-based web agents demonstrate strong performance on knowledge-intensive tasks but are hindered by context window limitations in paradigms like ReAct. Complex queries involving multiple entities, intertwined relationships, and high uncertainty demand extensive search cycles that rapidly exhaust context budgets before reaching complete solutions. To overcome this challenge, we introduce ReSum, a novel paradigm that enables indefinite exploration through periodic context summarization. ReSum converts growing interaction histories into compact reasoning states, maintaining awareness of prior discoveries while bypassing context constraints. For paradigm adaptation, we propose ReSum-GRPO, integrating GRPO with segmented trajectory training and advantage broadcasting to familiarize agents with summary-conditioned reasoning. Extensive experiments on web agents of varying scales across three benchmarks demonstrate that ReSum delivers an average absolute improvement of 4.5\% over ReAct, with further gains of up to 8.2\% following ReSum-GRPO training. Notably, with only 1K training samples, our WebResummer-30B (a ReSum-GRPO-trained version of WebSailor-30B) achieves 33.3\% Pass@1 on BrowseComp-zh and 18.3\% on BrowseComp-en, surpassing existing open-source web agents.
WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
Sep 16, 2025



Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all open-source agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
WebSailor: Navigating Super-human Reasoning for Web Agent
Jul 03, 2025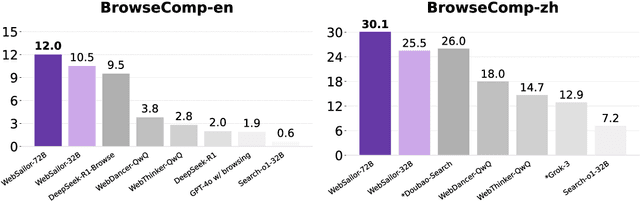
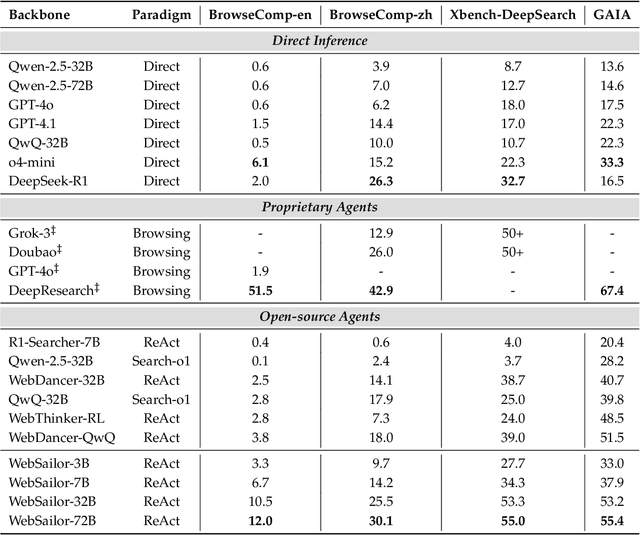
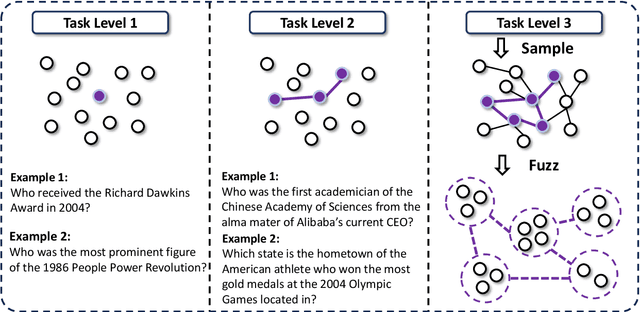

Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all opensource agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
Scalable Complexity Control Facilitates Reasoning Ability of LLMs
May 29, 2025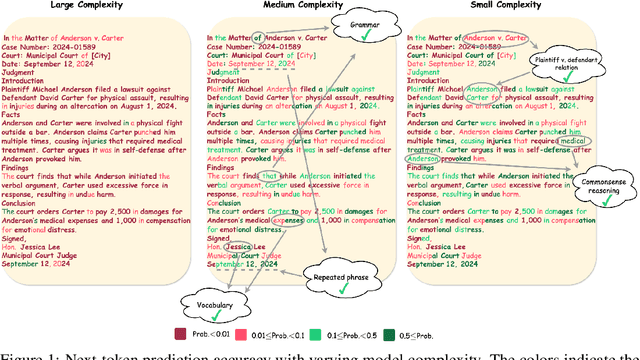
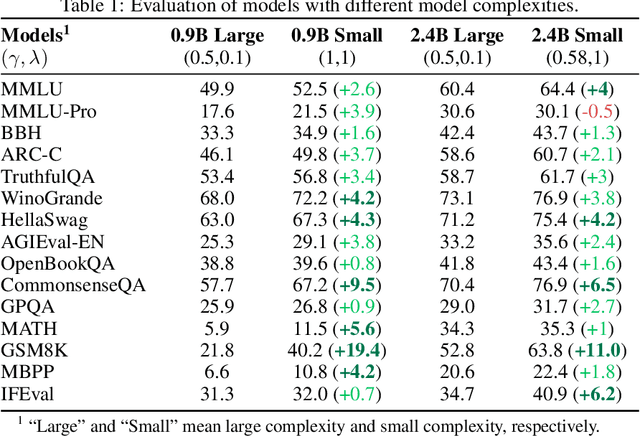
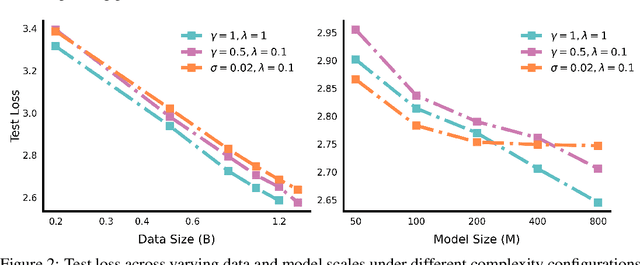
The reasoning ability of large language models (LLMs) has been rapidly advancing in recent years, attracting interest in more fundamental approaches that can reliably enhance their generalizability. This work demonstrates that model complexity control, conveniently implementable by adjusting the initialization rate and weight decay coefficient, improves the scaling law of LLMs consistently over varying model sizes and data sizes. This gain is further illustrated by comparing the benchmark performance of 2.4B models pretrained on 1T tokens with different complexity hyperparameters. Instead of fixing the initialization std, we found that a constant initialization rate (the exponent of std) enables the scaling law to descend faster in both model and data sizes. These results indicate that complexity control is a promising direction for the continual advancement of LLMs.
An Analysis for Reasoning Bias of Language Models with Small Initialization
Feb 05, 2025Transformer-based Large Language Models (LLMs) have revolutionized Natural Language Processing by demonstrating exceptional performance across diverse tasks. This study investigates the impact of the parameter initialization scale on the training behavior and task preferences of LLMs. We discover that smaller initialization scales encourage models to favor reasoning tasks, whereas larger initialization scales lead to a preference for memorization tasks. We validate this reasoning bias via real datasets and meticulously designed anchor functions. Further analysis of initial training dynamics suggests that specific model components, particularly the embedding space and self-attention mechanisms, play pivotal roles in shaping these learning biases. We provide a theoretical framework from the perspective of model training dynamics to explain these phenomena. Additionally, experiments on real-world language tasks corroborate our theoretical insights. This work enhances our understanding of how initialization strategies influence LLM performance on reasoning tasks and offers valuable guidelines for training models.
Reasoning Bias of Next Token Prediction Training
Feb 04, 2025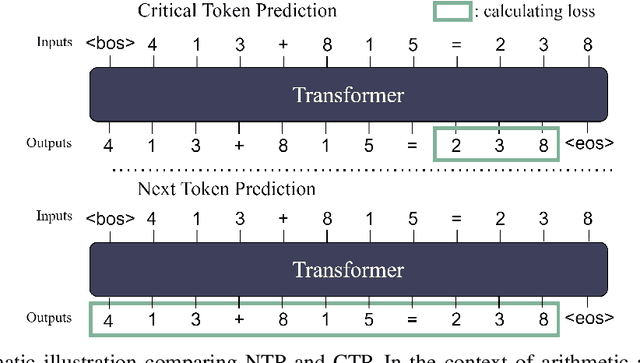
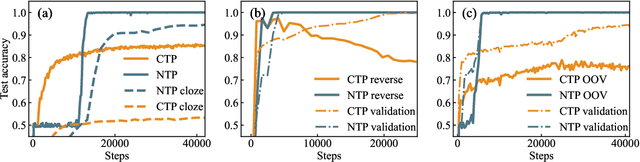


Since the inception of Large Language Models (LLMs), the quest to efficiently train them for superior reasoning capabilities has been a pivotal challenge. The dominant training paradigm for LLMs is based on next token prediction (NTP). Alternative methodologies, called Critical Token Prediction (CTP), focused exclusively on specific critical tokens (such as the answer in Q\&A dataset), aiming to reduce the overfitting of extraneous information and noise. Contrary to initial assumptions, our research reveals that despite NTP's exposure to noise during training, it surpasses CTP in reasoning ability. We attribute this counterintuitive outcome to the regularizing influence of noise on the training dynamics. Our empirical analysis shows that NTP-trained models exhibit enhanced generalization and robustness across various benchmark reasoning datasets, demonstrating greater resilience to perturbations and achieving flatter loss minima. These findings illuminate that NTP is instrumental in fostering reasoning abilities during pretraining, whereas CTP is more effective for finetuning, thereby enriching our comprehension of optimal training strategies in LLM development.
Complexity Control Facilitates Reasoning-Based Compositional Generalization in Transformers
Jan 15, 2025



Transformers have demonstrated impressive capabilities across various tasks, yet their performance on compositional problems remains a subject of debate. In this study, we investigate the internal mechanisms underlying Transformers' behavior in compositional tasks. We find that complexity control strategies significantly influence whether the model learns primitive-level rules that generalize out-of-distribution (reasoning-based solutions) or relies solely on memorized mappings (memory-based solutions). By applying masking strategies to the model's information circuits and employing multiple complexity metrics, we reveal distinct internal working mechanisms associated with different solution types. Further analysis reveals that reasoning-based solutions exhibit a lower complexity bias, which aligns with the well-studied neuron condensation phenomenon. This lower complexity bias is hypothesized to be the key factor enabling these solutions to learn reasoning rules. We validate these conclusions across multiple real-world datasets, including image generation and natural language processing tasks, confirming the broad applicability of our findings.
Local Linear Recovery Guarantee of Deep Neural Networks at Overparameterization
Jun 26, 2024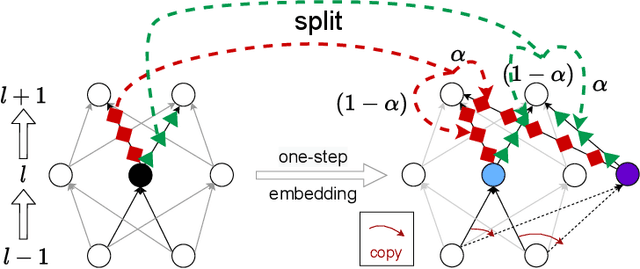
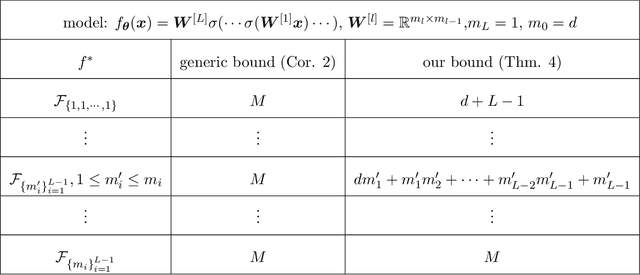
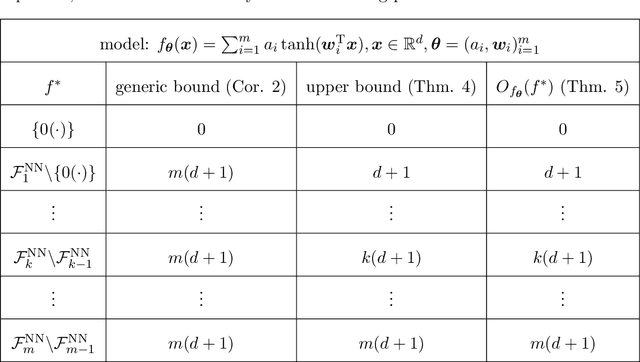
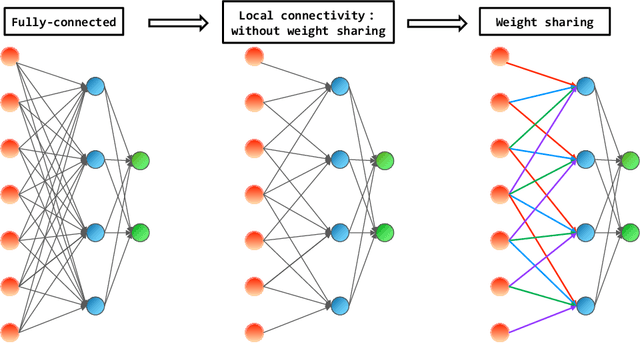
Determining whether deep neural network (DNN) models can reliably recover target functions at overparameterization is a critical yet complex issue in the theory of deep learning. To advance understanding in this area, we introduce a concept we term "local linear recovery" (LLR), a weaker form of target function recovery that renders the problem more amenable to theoretical analysis. In the sense of LLR, we prove that functions expressible by narrower DNNs are guaranteed to be recoverable from fewer samples than model parameters. Specifically, we establish upper limits on the optimistic sample sizes, defined as the smallest sample size necessary to guarantee LLR, for functions in the space of a given DNN. Furthermore, we prove that these upper bounds are achieved in the case of two-layer tanh neural networks. Our research lays a solid groundwork for future investigations into the recovery capabilities of DNNs in overparameterized scenarios.