 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-/Uni-Cast Non-Orthogonal Multiple Access-Based INAC
May 26, 2026With the rapid development of satellite communication and navigation, there is an urgent need to integrate both technologies to achieve reliable communication and precise navigation services within the same satellite system. By combining multi-/uni-cast (MUC) and non-orthogonal multiple access (NOMA) technologies, we propose a novel MUC-NOMA-based integrated navigation and communication (INAC) signal structure, in which the navigation and communication signals share a common pseudo noise (PN) sequence, thereby integrating satellite communication and navigation at the signal level. According to different power allocation strategies, two scenarios are defined: multi-cast-oriented (MO-) INAC and uni-cast-oriented (UO-) INAC, where a greater portion of power is assigned to either the multi-cast or the uni-cast signal, respectively. To mitigate co-channel interference, we employ successive interference cancellation (SIC) at the receiver and design a signal processing algorithm for the proposed INAC signal. Then, closed-form expressions are subsequently derived for the bit error rates (BER) of both the navigation and communication signals, along with the positioning accuracy of the navigation signal. To gain further insights, the impacts of power allocation factors and communication rates are evaluated. Our analysis results show that: i) In the MO-INAC scenario, the positioning and BER performance of navigation signal are excellent when more power is assigned to the multi-cast signal; ii) In the UO-INAC scenario, interference in the shared resources is reduced when more power is assigned to the uni-cast signal; iii) The ranging accuracy decreases as the communication data rate increases. Numerical results confirm the superior BER and positioning accuracy of the MO-INAC scenario for MEO satellites.
Integrated Positioning and Communications for PASS: A Robust Approach
May 26, 2026The pinching-antenna systems (PASS), which dynamically activate and relocate the pinching-antennas (PAs) along the dielectric waveguide, offer unprecedented potential for integrated positioning and communication. The multi-waveguide-based uplink positioning approaches for indoor environments are first proposed in this paper, and the downlink communication performance is analyzed. Two possible scenarios, multi-waveguide single-PA (MWSP) and multi-waveguide multi-PA (MWMP), are considered under the assumptions of line-of-sight channels and a single, stationary user. For the MWSP scenario, the received signal strength indication (RSSI)-based ranging method and the MWSP-based least square (LS) positioning algorithm are developed. To gain deeper insights, a comprehensive error analysis of the LS positioning algorithm is conducted. Subsequently, for the MWMP scenario, the closed-form expression of the superposed signal is derived. According to the signal power, the MWMP-based grid search algorithm is proposed and the estimation error of proposed algorithm is analyzed. Then, based on the user's positioning result, the PAs are relocated to provide downlink communication service, and the achievable data rate of MWSP and MWMP scenarios are analyzed. Numerical results validate the correctness of our analysis, which show that: i) For the MWSP scenario, a smaller geometric dilution of precision (GDoP) leads to a lower average positioning error. Furthermore, even when the GDoP is large, the regions where the distances to PAs are nearly equal achieve the best accuracy. ii) For the MWMP scenario, non-parallel waveguide deployment improves positioning accuracy, although errors increase with the number of PAs. iii) The noise has a serious double-impact on data rate. There is a trade-off between positioning accuracy and communication performance.
Determinism in the Undetermined: Deterministic Output in Charge-Conserving Continuous-Time Neuromorphic Systems with Temporal Stochasticity
Mar 16, 2026Achieving deterministic computation results in asynchronous neuromorphic systems remains a fundamental challenge due to the inherent temporal stochasticity of continuous-time hardware. To address this, we develop a unified continuous-time framework for spiking neural networks (SNNs) that couples the Law of Charge Conservation with minimal neuron-level constraints. This integration ensures that the terminal state depends solely on the aggregate input charge, providing a unique cumulated output invariant to temporal stochasticity. We prove that this mapping is strictly invariant to spike timing in acyclic networks, whereas recurrent connectivity can introduce temporal sensitivity. Furthermore, we establish an exact representational correspondence between these charge-conserving SNNs and quantized artificial neural networks, bridging the gap between static deep learning and event-driven dynamics without approximation errors. These results establish a rigorous theoretical basis for designing continuous-time neuromorphic systems that harness the efficiency of asynchronous processing while maintaining algorithmic determinism.
Towards Understanding Adam Convergence on Highly Degenerate Polynomials
Mar 10, 2026Adam is a widely used optimization algorithm in deep learning, yet the specific class of objective functions where it exhibits inherent advantages remains underexplored. Unlike prior studies requiring external schedulers and $β_2$ near 1 for convergence, this work investigates the "natural" auto-convergence properties of Adam. We identify a class of highly degenerate polynomials where Adam converges automatically without additional schedulers. Specifically, we derive theoretical conditions for local asymptotic stability on degenerate polynomials and demonstrate strong alignment between theoretical bounds and experimental results. We prove that Adam achieves local linear convergence on these degenerate functions, significantly outperforming the sub-linear convergence of Gradient Descent and Momentum. This acceleration stems from a decoupling mechanism between the second moment $v_t$ and squared gradient $g_t^2$, which exponentially amplifies the effective learning rate. Finally, we characterize Adam's hyperparameter phase diagram, identifying three distinct behavioral regimes: stable convergence, spikes, and SignGD-like oscillation.
Adaptive Preconditioners Trigger Loss Spikes in Adam
Jun 05, 2025Loss spikes emerge commonly during training across neural networks of varying architectures and scales when using the Adam optimizer. In this work, we investigate the underlying mechanism responsible for Adam spikes. While previous explanations attribute these phenomena to the lower-loss-as-sharper characteristics of the loss landscape, our analysis reveals that Adam's adaptive preconditioners themselves can trigger spikes. Specifically, we identify a critical regime where squared gradients become substantially smaller than the second-order moment estimates, causing the latter to undergo a $\beta_2$-exponential decay and to respond sluggishly to current gradient information. This mechanism can push the maximum eigenvalue of the preconditioned Hessian beyond the classical stability threshold $2/\eta$ for a sustained period, inducing instability. This instability further leads to an alignment between the gradient and the maximum eigendirection, and a loss spike occurs precisely when the gradient-directional curvature exceeds $2/\eta$. We verify this mechanism through extensive experiments on fully connected networks, convolutional networks, and Transformer architectures.
Scalable Complexity Control Facilitates Reasoning Ability of LLMs
May 29, 2025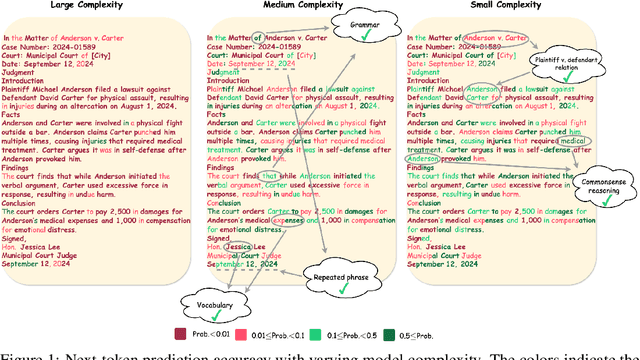
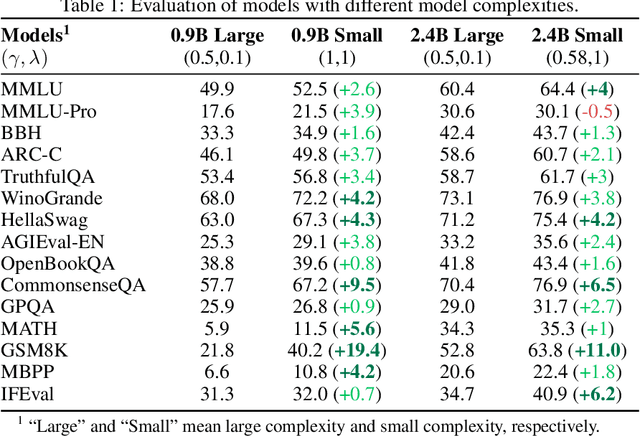
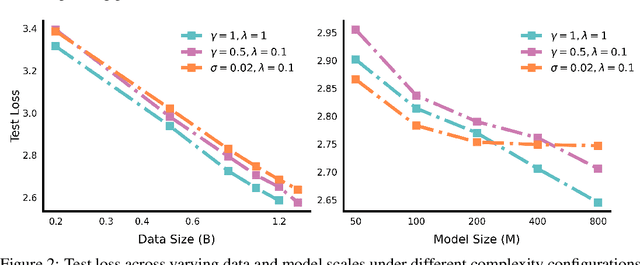
The reasoning ability of large language models (LLMs) has been rapidly advancing in recent years, attracting interest in more fundamental approaches that can reliably enhance their generalizability. This work demonstrates that model complexity control, conveniently implementable by adjusting the initialization rate and weight decay coefficient, improves the scaling law of LLMs consistently over varying model sizes and data sizes. This gain is further illustrated by comparing the benchmark performance of 2.4B models pretrained on 1T tokens with different complexity hyperparameters. Instead of fixing the initialization std, we found that a constant initialization rate (the exponent of std) enables the scaling law to descend faster in both model and data sizes. These results indicate that complexity control is a promising direction for the continual advancement of LLMs.
Uncovering Critical Sets of Deep Neural Networks via Sample-Independent Critical Lifting
May 19, 2025This paper investigates the sample dependence of critical points for neural networks. We introduce a sample-independent critical lifting operator that associates a parameter of one network with a set of parameters of another, thus defining sample-dependent and sample-independent lifted critical points. We then show by example that previously studied critical embeddings do not capture all sample-independent lifted critical points. Finally, we demonstrate the existence of sample-dependent lifted critical points for sufficiently large sample sizes and prove that saddles appear among them.
Embedding principle of homogeneous neural network for classification problem
May 18, 2025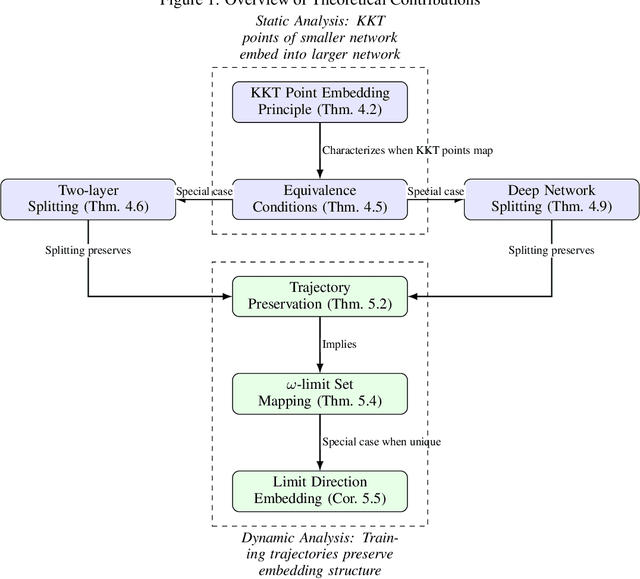
Understanding the convergence points and optimization landscape of neural networks is crucial, particularly for homogeneous networks where Karush-Kuhn-Tucker (KKT) points of the associated maximum-margin problem often characterize solutions. This paper investigates the relationship between such KKT points across networks of different widths generated via neuron splitting. We introduce and formalize the \textbf{KKT point embedding principle}, establishing that KKT points of a homogeneous network's max-margin problem ($P_{\Phi}$) can be embedded into the KKT points of a larger network's problem ($P_{\tilde{\Phi}}$) via specific linear isometric transformations corresponding to neuron splitting. We rigorously prove this principle holds for neuron splitting in both two-layer and deep homogeneous networks. Furthermore, we connect this static embedding to the dynamics of gradient flow training with smooth losses. We demonstrate that trajectories initiated from appropriately mapped points remain mapped throughout training and that the resulting $\omega$-limit sets of directions are correspondingly mapped ($T(L(\theta(0))) = L(\boldsymbol{\eta}(0))$), thereby preserving the alignment with KKT directions dynamically when directional convergence occurs. Our findings offer insights into the effects of network width, parameter redundancy, and the structural connections between solutions found via optimization in homogeneous networks of varying sizes.
An overview of condensation phenomenon in deep learning
Apr 13, 2025



In this paper, we provide an overview of a common phenomenon, condensation, observed during the nonlinear training of neural networks: During the nonlinear training of neural networks, neurons in the same layer tend to condense into groups with similar outputs. Empirical observations suggest that the number of condensed clusters of neurons in the same layer typically increases monotonically as training progresses. Neural networks with small weight initializations or Dropout optimization can facilitate this condensation process. We also examine the underlying mechanisms of condensation from the perspectives of training dynamics and the structure of the loss landscape. The condensation phenomenon offers valuable insights into the generalization abilities of neural networks and correlates to stronger reasoning abilities in transformer-based language models.
Complexity Control Facilitates Reasoning-Based Compositional Generalization in Transformers
Jan 15, 2025



Transformers have demonstrated impressive capabilities across various tasks, yet their performance on compositional problems remains a subject of debate. In this study, we investigate the internal mechanisms underlying Transformers' behavior in compositional tasks. We find that complexity control strategies significantly influence whether the model learns primitive-level rules that generalize out-of-distribution (reasoning-based solutions) or relies solely on memorized mappings (memory-based solutions). By applying masking strategies to the model's information circuits and employing multiple complexity metrics, we reveal distinct internal working mechanisms associated with different solution types. Further analysis reveals that reasoning-based solutions exhibit a lower complexity bias, which aligns with the well-studied neuron condensation phenomenon. This lower complexity bias is hypothesized to be the key factor enabling these solutions to learn reasoning rules. We validate these conclusions across multiple real-world datasets, including image generation and natural language processing tasks, confirming the broad applicability of our findings.