 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding principle of homogeneous neural network for classification problem
May 18, 2025Understanding the convergence points and optimization landscape of neural networks is crucial, particularly for homogeneous networks where Karush-Kuhn-Tucker (KKT) points of the associated maximum-margin problem often characterize solutions. This paper investigates the relationship between such KKT points across networks of different widths generated via neuron splitting. We introduce and formalize the \textbf{KKT point embedding principle}, establishing that KKT points of a homogeneous network's max-margin problem ($P_{\Phi}$) can be embedded into the KKT points of a larger network's problem ($P_{\tilde{\Phi}}$) via specific linear isometric transformations corresponding to neuron splitting. We rigorously prove this principle holds for neuron splitting in both two-layer and deep homogeneous networks. Furthermore, we connect this static embedding to the dynamics of gradient flow training with smooth losses. We demonstrate that trajectories initiated from appropriately mapped points remain mapped throughout training and that the resulting $\omega$-limit sets of directions are correspondingly mapped ($T(L(\theta(0))) = L(\boldsymbol{\eta}(0))$), thereby preserving the alignment with KKT directions dynamically when directional convergence occurs. Our findings offer insights into the effects of network width, parameter redundancy, and the structural connections between solutions found via optimization in homogeneous networks of varying sizes.
Candidate Pseudolabel Learning: Enhancing Vision-Language Models by Prompt Tuning with Unlabeled Data
Jun 15, 2024Fine-tuning vision-language models (VLMs) with abundant unlabeled data recently has attracted increasing attention. Existing methods that resort to the pseudolabeling strategy would suffer from heavily incorrect hard pseudolabels when VLMs exhibit low zero-shot performance in downstream tasks. To alleviate this issue, we propose a Candidate Pseudolabel Learning method, termed CPL, to fine-tune VLMs with suitable candidate pseudolabels of unlabeled data in downstream tasks. The core of our method lies in the generation strategy of candidate pseudolabels, which progressively generates refined candidate pseudolabels by both intra- and inter-instance label selection, based on a confidence score matrix for all unlabeled data. This strategy can result in better performance in true label inclusion and class-balanced instance selection. In this way, we can directly apply existing loss functions to learn with generated candidate psueudolabels. Extensive experiments on nine benchmark datasets with three learning paradigms demonstrate the effectiveness of our method. Our code can be found at https://github.com/vanillaer/CPL-ICML2024.
Cycle-guided Denoising Diffusion Probability Model for 3D Cross-modality MRI Synthesis
Apr 28, 2023This study aims to develop a novel Cycle-guided Denoising Diffusion Probability Model (CG-DDPM) for cross-modality MRI synthesis. The CG-DDPM deploys two DDPMs that condition each other to generate synthetic images from two different MRI pulse sequences. The two DDPMs exchange random latent noise in the reverse processes, which helps to regularize both DDPMs and generate matching images in two modalities. This improves image-to-image translation ac-curacy. We evaluated the CG-DDPM quantitatively using mean absolute error (MAE), multi-scale structural similarity index measure (MSSIM), and peak sig-nal-to-noise ratio (PSNR), as well as the network synthesis consistency, on the BraTS2020 dataset. Our proposed method showed high accuracy and reliable consistency for MRI synthesis. In addition, we compared the CG-DDPM with several other state-of-the-art networks and demonstrated statistically significant improvements in the image quality of synthetic MRIs. The proposed method enhances the capability of current multimodal MRI synthesis approaches, which could contribute to more accurate diagnosis and better treatment planning for patients by synthesizing additional MRI modalities.
Self-supervised Training Sample Difficulty Balancing for Local Descriptor Learning
Mar 10, 2023

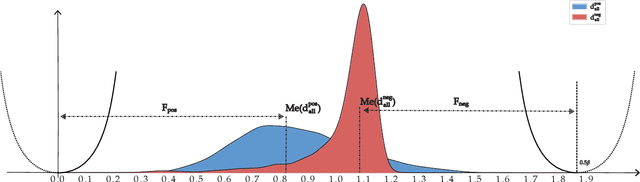

In the case of an imbalance between positive and negative samples, hard negative mining strategies have been shown to help models learn more subtle differences between positive and negative samples, thus improving recognition performance. However, if too strict mining strategies are promoted in the dataset, there may be a risk of introducing false negative samples. Meanwhile, the implementation of the mining strategy disrupts the difficulty distribution of samples in the real dataset, which may cause the model to over-fit these difficult samples. Therefore, in this paper, we investigate how to trade off the difficulty of the mined samples in order to obtain and exploit high-quality negative samples, and try to solve the problem in terms of both the loss function and the training strategy. The proposed balance loss provides an effective discriminant for the quality of negative samples by combining a self-supervised approach to the loss function, and uses a dynamic gradient modulation strategy to achieve finer gradient adjustment for samples of different difficulties. The proposed annealing training strategy then constrains the difficulty of the samples drawn from negative sample mining to provide data sources with different difficulty distributions for the loss function, and uses samples of decreasing difficulty to train the model. Extensive experiments show that our new descriptors outperform previous state-of-the-art descriptors for patch validation, matching, and retrieval tasks.
Reinforcement Learning in Medical Image Analysis: Concepts, Applications, Challenges, and Future Directions
Jun 28, 2022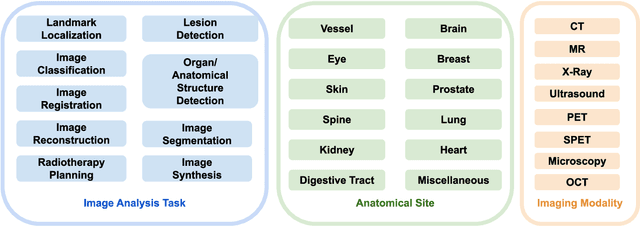
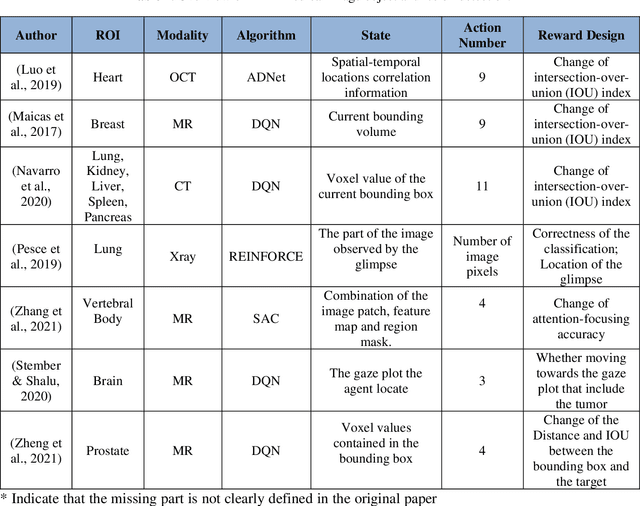
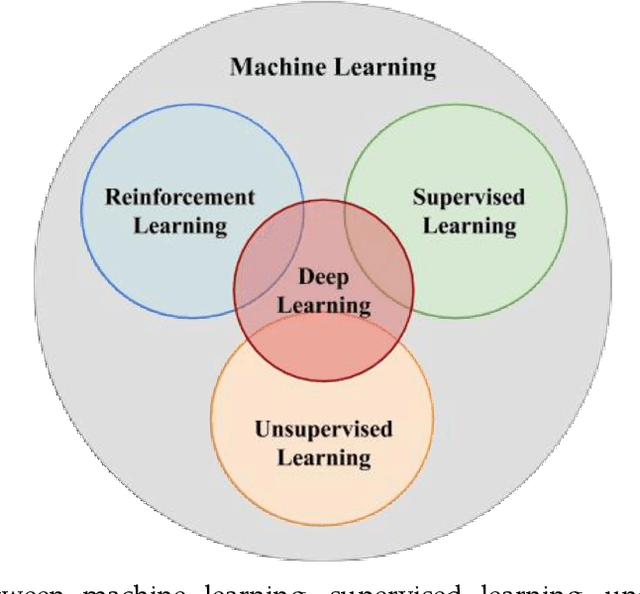

Motivation: Medical image analysis involves tasks to assist physicians in qualitative and quantitative analysis of lesions or anatomical structures, significantly improving the accuracy and reliability of diagnosis and prognosis. Traditionally, these tasks are finished by physicians or medical physicists and lead to two major problems: (i) low efficiency; (ii) biased by personal experience. In the past decade, many machine learning methods have been applied to accelerate and automate the image analysis process. Compared to the enormous deployments of supervised and unsupervised learning models, attempts to use reinforcement learning in medical image analysis are scarce. This review article could serve as the stepping-stone for related research. Significance: From our observation, though reinforcement learning has gradually gained momentum in recent years, many researchers in the medical analysis field find it hard to understand and deploy in clinics. One cause is lacking well-organized review articles targeting readers lacking professional computer science backgrounds. Rather than providing a comprehensive list of all reinforcement learning models in medical image analysis, this paper may help the readers to learn how to formulate and solve their medical image analysis research as reinforcement learning problems. Approach & Results: We selected published articles from Google Scholar and PubMed. Considering the scarcity of related articles, we also included some outstanding newest preprints. The papers are carefully reviewed and categorized according to the type of image analysis task. We first review the basic concepts and popular models of reinforcement learning. Then we explore the applications of reinforcement learning models in landmark detection. Finally, we conclude the article by discussing the reviewed reinforcement learning approaches' limitations and possible improvements.