 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Review and Meta-analysis of AI-driven MRI Motion Artifact Detection and Correction
Sep 05, 2025Background: To systematically review and perform a meta-analysis of artificial intelligence (AI)-driven methods for detecting and correcting magnetic resonance imaging (MRI) motion artifacts, assessing current developments, effectiveness, challenges, and future research directions. Methods: A comprehensive systematic review and meta-analysis were conducted, focusing on deep learning (DL) approaches, particularly generative models, for the detection and correction of MRI motion artifacts. Quantitative data were extracted regarding utilized datasets, DL architectures, and performance metrics. Results: DL, particularly generative models, show promise for reducing motion artifacts and improving image quality; however, limited generalizability, reliance on paired training data, and risk of visual distortions remain key challenges that motivate standardized datasets and reporting. Conclusions: AI-driven methods, particularly DL generative models, show significant potential for improving MRI image quality by effectively addressing motion artifacts. However, critical challenges must be addressed, including the need for comprehensive public datasets, standardized reporting protocols for artifact levels, and more advanced, adaptable DL techniques to reduce reliance on extensive paired datasets. Addressing these aspects could substantially enhance MRI diagnostic accuracy, reduce healthcare costs, and improve patient care outcomes.
Automatic Treatment Planning using Reinforcement Learning for High-dose-rate Prostate Brachytherapy
Jun 11, 2025Purpose: In high-dose-rate (HDR) prostate brachytherapy procedures, the pattern of needle placement solely relies on physician experience. We investigated the feasibility of using reinforcement learning (RL) to provide needle positions and dwell times based on patient anatomy during pre-planning stage. This approach would reduce procedure time and ensure consistent plan quality. Materials and Methods: We train a RL agent to adjust the position of one selected needle and all the dwell times on it to maximize a pre-defined reward function after observing the environment. After adjusting, the RL agent then moves on to the next needle, until all needles are adjusted. Multiple rounds are played by the agent until the maximum number of rounds is reached. Plan data from 11 prostate HDR boost patients (1 for training, and 10 for testing) treated in our clinic were included in this study. The dosimetric metrics and the number of used needles of RL plan were compared to those of the clinical results (ground truth). Results: On average, RL plans and clinical plans have very similar prostate coverage (Prostate V100) and Rectum D2cc (no statistical significance), while RL plans have less prostate hotspot (Prostate V150) and Urethra D20% plans with statistical significance. Moreover, RL plans use 2 less needles than clinical plan on average. Conclusion: We present the first study demonstrating the feasibility of using reinforcement learning to autonomously generate clinically practical HDR prostate brachytherapy plans. This RL-based method achieved equal or improved plan quality compared to conventional clinical approaches while requiring fewer needles. With minimal data requirements and strong generalizability, this approach has substantial potential to standardize brachytherapy planning, reduce clinical variability, and enhance patient outcomes.
Deep Learning Based Apparent Diffusion Coefficient Map Generation1 from Multi-parametric MR Images for Patients with Diffuse Gliomas
Jul 02, 2024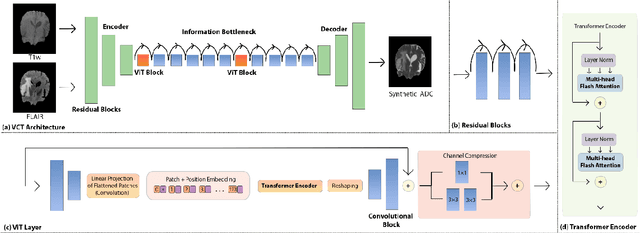
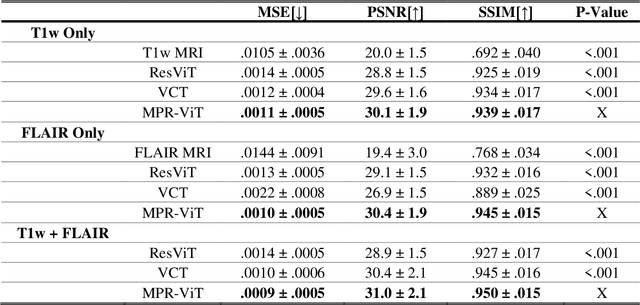
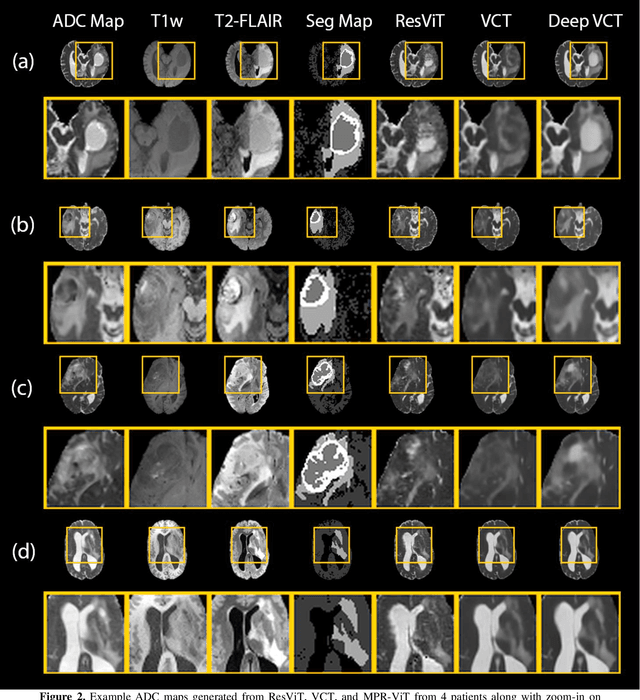
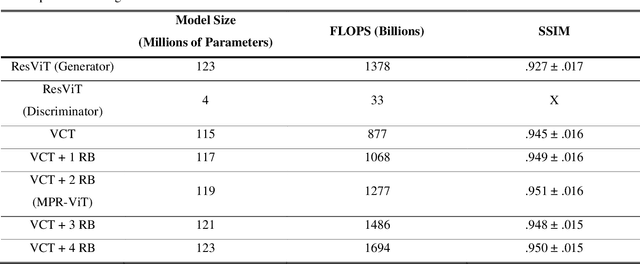
Purpose: Apparent diffusion coefficient (ADC) maps derived from diffusion weighted (DWI) MRI provides functional measurements about the water molecules in tissues. However, DWI is time consuming and very susceptible to image artifacts, leading to inaccurate ADC measurements. This study aims to develop a deep learning framework to synthesize ADC maps from multi-parametric MR images. Methods: We proposed the multiparametric residual vision transformer model (MPR-ViT) that leverages the long-range context of ViT layers along with the precision of convolutional operators. Residual blocks throughout the network significantly increasing the representational power of the model. The MPR-ViT model was applied to T1w and T2- fluid attenuated inversion recovery images of 501 glioma cases from a publicly available dataset including preprocessed ADC maps. Selected patients were divided into training (N=400), validation (N=50) and test (N=51) sets, respectively. Using the preprocessed ADC maps as ground truth, model performance was evaluated and compared against the Vision Convolutional Transformer (VCT) and residual vision transformer (ResViT) models. Results: The results are as follows using T1w + T2-FLAIR MRI as inputs: MPR-ViT - PSNR: 31.0 +/- 2.1, MSE: 0.009 +/- 0.0005, SSIM: 0.950 +/- 0.015. In addition, ablation studies showed the relative impact on performance of each input sequence. Both qualitative and quantitative results indicate that the proposed MR- ViT model performs favorably against the ground truth data. Conclusion: We show that high-quality ADC maps can be synthesized from structural MRI using a MPR- VCT model. Our predicted images show better conformality to the ground truth volume than ResViT and VCT predictions. These high-quality synthetic ADC maps would be particularly useful for disease diagnosis and intervention, especially when ADC maps have artifacts or are unavailable.
Diffeomorphic Transformer-based Abdomen MRI-CT Deformable Image Registration
May 04, 2024



This paper aims to create a deep learning framework that can estimate the deformation vector field (DVF) for directly registering abdominal MRI-CT images. The proposed method assumed a diffeomorphic deformation. By using topology-preserved deformation features extracted from the probabilistic diffeomorphic registration model, abdominal motion can be accurately obtained and utilized for DVF estimation. The model integrated Swin transformers, which have demonstrated superior performance in motion tracking, into the convolutional neural network (CNN) for deformation feature extraction. The model was optimized using a cross-modality image similarity loss and a surface matching loss. To compute the image loss, a modality-independent neighborhood descriptor (MIND) was used between the deformed MRI and CT images. The surface matching loss was determined by measuring the distance between the warped coordinates of the surfaces of contoured structures on the MRI and CT images. The deformed MRI image was assessed against the CT image using the target registration error (TRE), Dice similarity coefficient (DSC), and mean surface distance (MSD) between the deformed contours of the MRI image and manual contours of the CT image. When compared to only rigid registration, DIR with the proposed method resulted in an increase of the mean DSC values of the liver and portal vein from 0.850 and 0.628 to 0.903 and 0.763, a decrease of the mean MSD of the liver from 7.216 mm to 3.232 mm, and a decrease of the TRE from 26.238 mm to 8.492 mm. The proposed deformable image registration method based on a diffeomorphic transformer provides an effective and efficient way to generate an accurate DVF from an MRI-CT image pair of the abdomen. It could be utilized in the current treatment planning workflow for liver radiotherapy.
Image-Domain Material Decomposition for Dual-energy CT using Unsupervised Learning with Data-fidelity Loss
Nov 17, 2023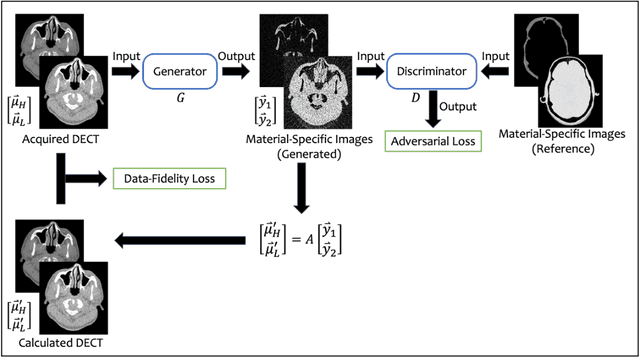
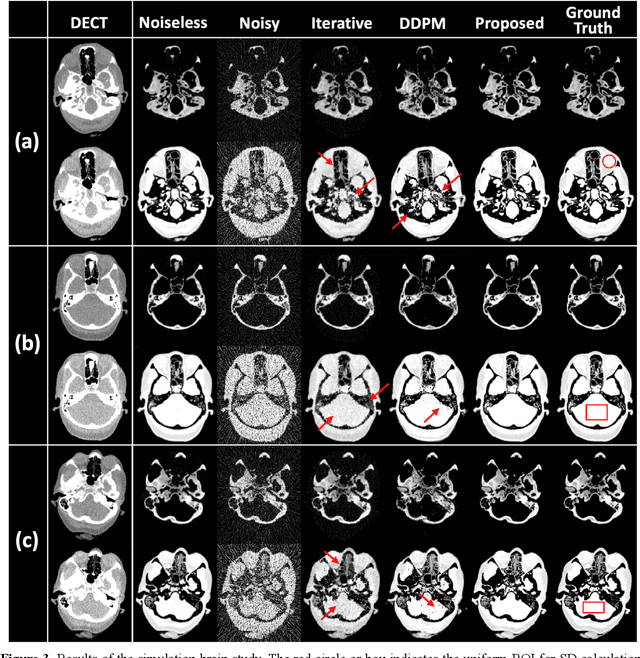
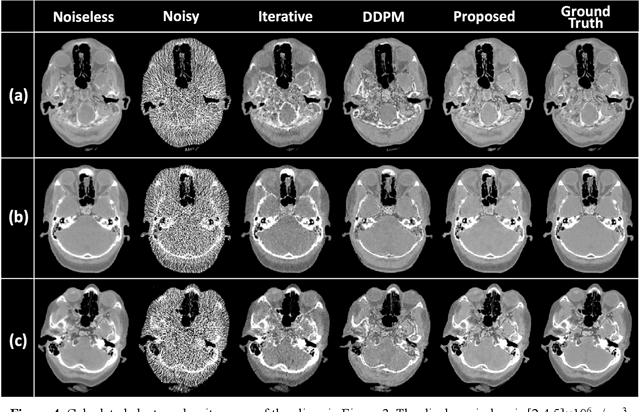
Background: Dual-energy CT (DECT) and material decomposition play vital roles in quantitative medical imaging. However, the decomposition process may suffer from significant noise amplification, leading to severely degraded image signal-to-noise ratios (SNRs). While existing iterative algorithms perform noise suppression using different image priors, these heuristic image priors cannot accurately represent the features of the target image manifold. Although deep learning-based decomposition methods have been reported, these methods are in the supervised-learning framework requiring paired data for training, which is not readily available in clinical settings. Purpose: This work aims to develop an unsupervised-learning framework with data-measurement consistency for image-domain material decomposition in DECT.
Full-dose PET Synthesis from Low-dose PET Using High-efficiency Diffusion Denoising Probabilistic Model
Aug 24, 2023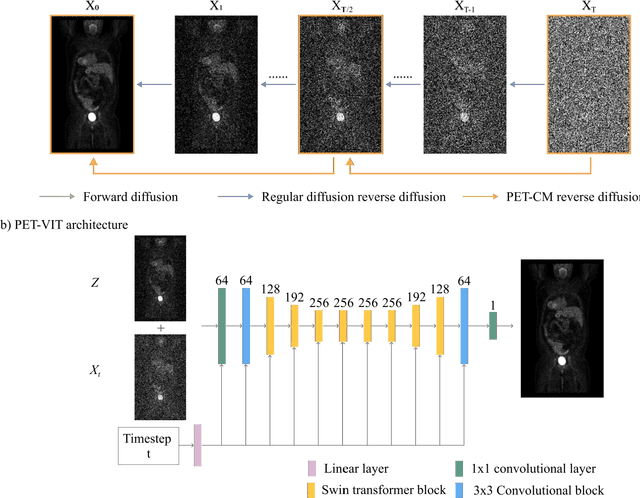


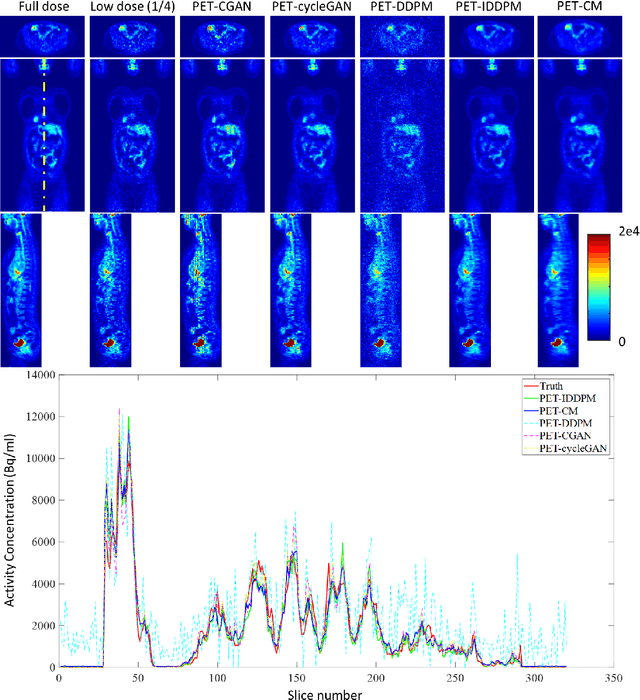
To reduce the risks associated with ionizing radiation, a reduction of radiation exposure in PET imaging is needed. However, this leads to a detrimental effect on image contrast and quantification. High-quality PET images synthesized from low-dose data offer a solution to reduce radiation exposure. We introduce a diffusion-model-based approach for estimating full-dose PET images from low-dose ones: the PET Consistency Model (PET-CM) yielding synthetic quality comparable to state-of-the-art diffusion-based synthesis models, but with greater efficiency. There are two steps: a forward process that adds Gaussian noise to a full dose PET image at multiple timesteps, and a reverse diffusion process that employs a PET Shifted-window Vision Transformer (PET-VIT) network to learn the denoising procedure conditioned on the corresponding low-dose PETs. In PET-CM, the reverse process learns a consistency function for direct denoising of Gaussian noise to a clean full-dose PET. We evaluated the PET-CM in generating full-dose images using only 1/8 and 1/4 of the standard PET dose. Comparing 1/8 dose to full-dose images, PET-CM demonstrated impressive performance with normalized mean absolute error (NMAE) of 1.233+/-0.131%, peak signal-to-noise ratio (PSNR) of 33.915+/-0.933dB, structural similarity index (SSIM) of 0.964+/-0.009, and normalized cross-correlation (NCC) of 0.968+/-0.011, with an average generation time of 62 seconds per patient. This is a significant improvement compared to the state-of-the-art diffusion-based model with PET-CM reaching this result 12x faster. In the 1/4 dose to full-dose image experiments, PET-CM is also competitive, achieving an NMAE 1.058+/-0.092%, PSNR of 35.548+/-0.805dB, SSIM of 0.978+/-0.005, and NCC 0.981+/-0.007 The results indicate promising low-dose PET image quality improvements for clinical applications.
Synthetic CT Generation from MRI using 3D Transformer-based Denoising Diffusion Model
May 31, 2023


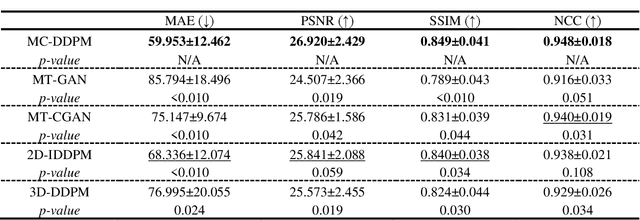
Magnetic resonance imaging (MRI)-based synthetic computed tomography (sCT) simplifies radiation therapy treatment planning by eliminating the need for CT simulation and error-prone image registration, ultimately reducing patient radiation dose and setup uncertainty. We propose an MRI-to-CT transformer-based denoising diffusion probabilistic model (MC-DDPM) to transform MRI into high-quality sCT to facilitate radiation treatment planning. MC-DDPM implements diffusion processes with a shifted-window transformer network to generate sCT from MRI. The proposed model consists of two processes: a forward process which adds Gaussian noise to real CT scans, and a reverse process in which a shifted-window transformer V-net (Swin-Vnet) denoises the noisy CT scans conditioned on the MRI from the same patient to produce noise-free CT scans. With an optimally trained Swin-Vnet, the reverse diffusion process was used to generate sCT scans matching MRI anatomy. We evaluated the proposed method by generating sCT from MRI on a brain dataset and a prostate dataset. Qualitative evaluation was performed using the mean absolute error (MAE) of Hounsfield unit (HU), peak signal to noise ratio (PSNR), multi-scale Structure Similarity index (MS-SSIM) and normalized cross correlation (NCC) indexes between ground truth CTs and sCTs. MC-DDPM generated brain sCTs with state-of-the-art quantitative results with MAE 43.317 HU, PSNR 27.046 dB, SSIM 0.965, and NCC 0.983. For the prostate dataset, MC-DDPM achieved MAE 59.953 HU, PSNR 26.920 dB, SSIM 0.849, and NCC 0.948. In conclusion, we have developed and validated a novel approach for generating CT images from routine MRIs using a transformer-based DDPM. This model effectively captures the complex relationship between CT and MRI images, allowing for robust and high-quality synthetic CT (sCT) images to be generated in minutes.
Cycle-guided Denoising Diffusion Probability Model for 3D Cross-modality MRI Synthesis
Apr 28, 2023This study aims to develop a novel Cycle-guided Denoising Diffusion Probability Model (CG-DDPM) for cross-modality MRI synthesis. The CG-DDPM deploys two DDPMs that condition each other to generate synthetic images from two different MRI pulse sequences. The two DDPMs exchange random latent noise in the reverse processes, which helps to regularize both DDPMs and generate matching images in two modalities. This improves image-to-image translation ac-curacy. We evaluated the CG-DDPM quantitatively using mean absolute error (MAE), multi-scale structural similarity index measure (MSSIM), and peak sig-nal-to-noise ratio (PSNR), as well as the network synthesis consistency, on the BraTS2020 dataset. Our proposed method showed high accuracy and reliable consistency for MRI synthesis. In addition, we compared the CG-DDPM with several other state-of-the-art networks and demonstrated statistically significant improvements in the image quality of synthetic MRIs. The proposed method enhances the capability of current multimodal MRI synthesis approaches, which could contribute to more accurate diagnosis and better treatment planning for patients by synthesizing additional MRI modalities.
Deep Learning-based Multi-Organ CT Segmentation with Adversarial Data Augmentation
Feb 25, 2023In this work, we propose an adversarial attack-based data augmentation method to improve the deep-learning-based segmentation algorithm for the delineation of Organs-At-Risk (OAR) in abdominal Computed Tomography (CT) to facilitate radiation therapy. We introduce Adversarial Feature Attack for Medical Image (AFA-MI) augmentation, which forces the segmentation network to learn out-of-distribution statistics and improve generalization and robustness to noises. AFA-MI augmentation consists of three steps: 1) generate adversarial noises by Fast Gradient Sign Method (FGSM) on the intermediate features of the segmentation network's encoder; 2) inject the generated adversarial noises into the network, intentionally compromising performance; 3) optimize the network with both clean and adversarial features. Experiments are conducted segmenting the heart, left and right kidney, liver, left and right lung, spinal cord, and stomach. We first evaluate the AFA-MI augmentation using nnUnet and TT-Vnet on the test data from a public abdominal dataset and an institutional dataset. In addition, we validate how AFA-MI affects the networks' robustness to the noisy data by evaluating the networks with added Gaussian noises of varying magnitudes to the institutional dataset. Network performance is quantitatively evaluated using Dice Similarity Coefficient (DSC) for volume-based accuracy. Also, Hausdorff Distance (HD) is applied for surface-based accuracy. On the public dataset, nnUnet with AFA-MI achieves DSC = 0.85 and HD = 6.16 millimeters (mm); and TT-Vnet achieves DSC = 0.86 and HD = 5.62 mm. AFA-MI augmentation further improves all contour accuracies up to 0.217 DSC score when tested on images with Gaussian noises. AFA-MI augmentation is therefore demonstrated to improve segmentation performance and robustness in CT multi-organ segmentation.
Deformable Image Registration using Unsupervised Deep Learning for CBCT-guided Abdominal Radiotherapy
Aug 29, 2022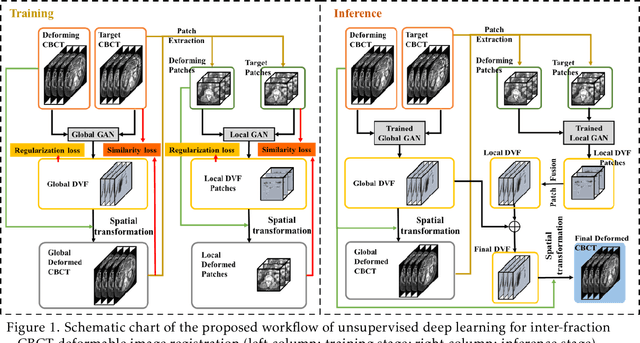
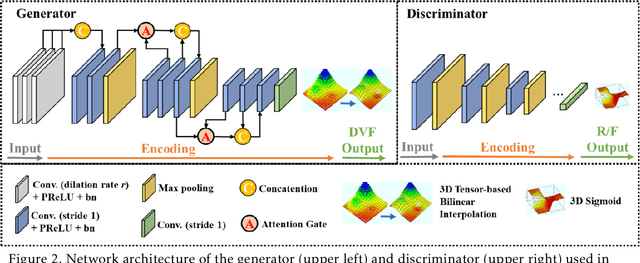
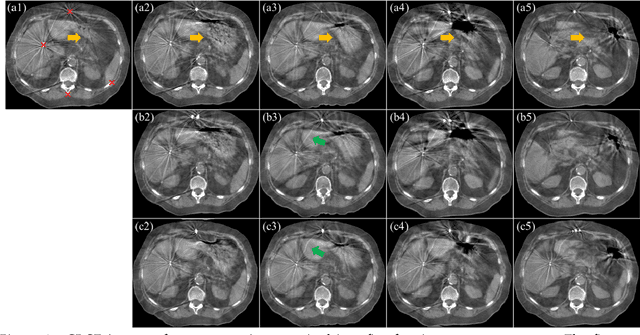
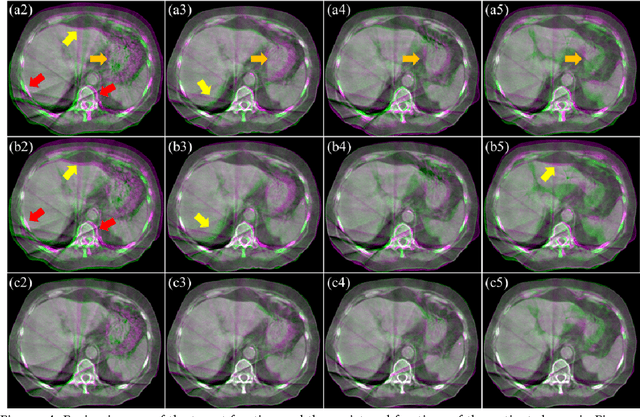
CBCTs in image-guided radiotherapy provide crucial anatomy information for patient setup and plan evaluation. Longitudinal CBCT image registration could quantify the inter-fractional anatomic changes. The purpose of this study is to propose an unsupervised deep learning based CBCT-CBCT deformable image registration. The proposed deformable registration workflow consists of training and inference stages that share the same feed-forward path through a spatial transformation-based network (STN). The STN consists of a global generative adversarial network (GlobalGAN) and a local GAN (LocalGAN) to predict the coarse- and fine-scale motions, respectively. The network was trained by minimizing the image similarity loss and the deformable vector field (DVF) regularization loss without the supervision of ground truth DVFs. During the inference stage, patches of local DVF were predicted by the trained LocalGAN and fused to form a whole-image DVF. The local whole-image DVF was subsequently combined with the GlobalGAN generated DVF to obtain final DVF. The proposed method was evaluated using 100 fractional CBCTs from 20 abdominal cancer patients in the experiments and 105 fractional CBCTs from a cohort of 21 different abdominal cancer patients in a holdout test. Qualitatively, the registration results show great alignment between the deformed CBCT images and the target CBCT image. Quantitatively, the average target registration error (TRE) calculated on the fiducial markers and manually identified landmarks was 1.91+-1.11 mm. The average mean absolute error (MAE), normalized cross correlation (NCC) between the deformed CBCT and target CBCT were 33.42+-7.48 HU, 0.94+-0.04, respectively. This promising registration method could provide fast and accurate longitudinal CBCT alignment to facilitate inter-fractional anatomic changes analysis and prediction.