 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT1-contrast Enhanced MRI Generation from Multi-parametric MRI for Glioma Patients with Latent Tumor Conditioning
Sep 03, 2024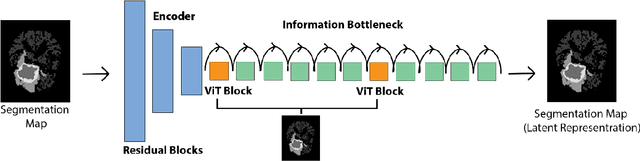
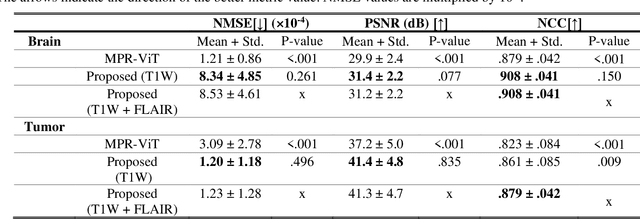
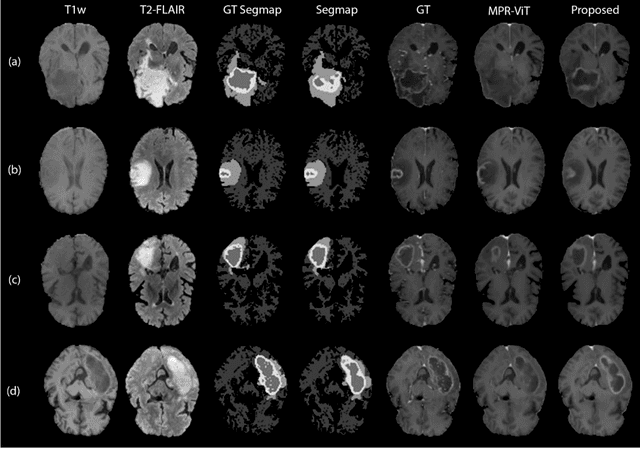
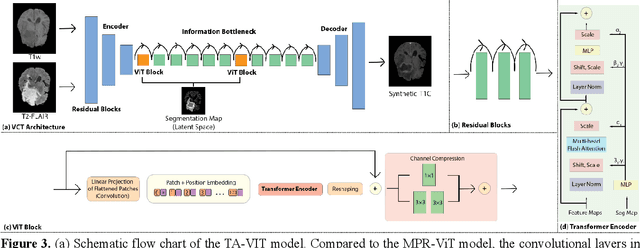
Objective: Gadolinium-based contrast agents (GBCAs) are commonly used in MRI scans of patients with gliomas to enhance brain tumor characterization using T1-weighted (T1W) MRI. However, there is growing concern about GBCA toxicity. This study develops a deep-learning framework to generate T1-postcontrast (T1C) from pre-contrast multiparametric MRI. Approach: We propose the tumor-aware vision transformer (TA-ViT) model that predicts high-quality T1C images. The predicted tumor region is significantly improved (P < .001) by conditioning the transformer layers from predicted segmentation maps through adaptive layer norm zero mechanism. The predicted segmentation maps were generated with the multi-parametric residual (MPR) ViT model and transformed into a latent space to produce compressed, feature-rich representations. The TA-ViT model predicted T1C MRI images of 501 glioma cases. Selected patients were split into training (N=400), validation (N=50), and test (N=51) sets. Main Results: Both qualitative and quantitative results demonstrate that the TA-ViT model performs superior against the benchmark MRP-ViT model. Our method produces synthetic T1C MRI with high soft tissue contrast and more accurately reconstructs both the tumor and whole brain volumes. The synthesized T1C images achieved remarkable improvements in both tumor and healthy tissue regions compared to the MRP-ViT model. For healthy tissue and tumor regions, the results were as follows: NMSE: 8.53 +/- 4.61E-4; PSNR: 31.2 +/- 2.2; NCC: 0.908 +/- .041 and NMSE: 1.22 +/- 1.27E-4, PSNR: 41.3 +/- 4.7, and NCC: 0.879 +/- 0.042, respectively. Significance: The proposed method generates synthetic T1C images that closely resemble real T1C images. Future development and application of this approach may enable contrast-agent-free MRI for brain tumor patients, eliminating the risk of GBCA toxicity and simplifying the MRI scan protocol.
Deep Learning Based Apparent Diffusion Coefficient Map Generation1 from Multi-parametric MR Images for Patients with Diffuse Gliomas
Jul 02, 2024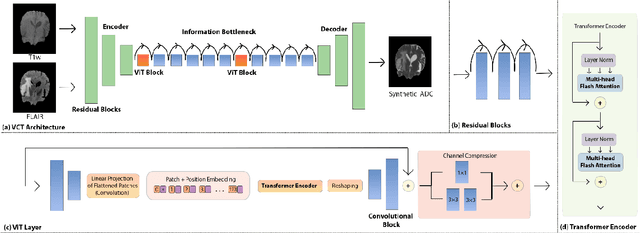
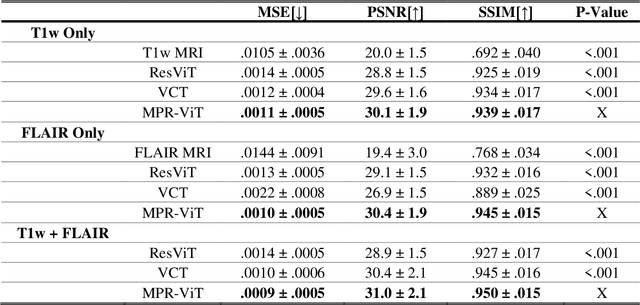
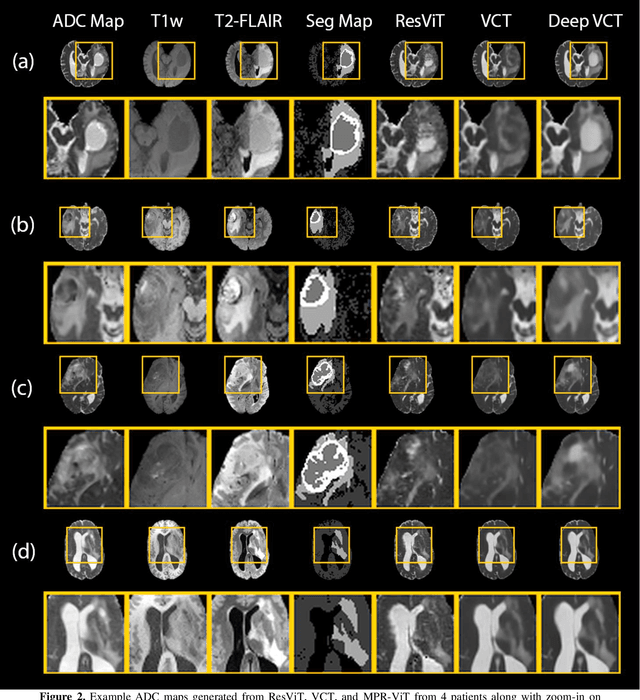
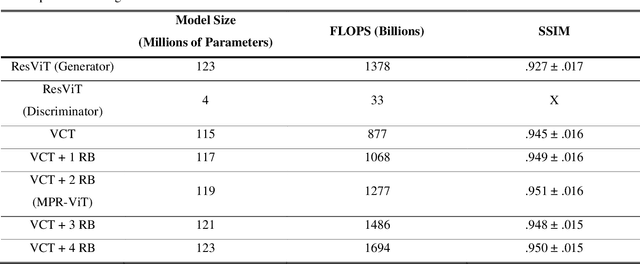
Purpose: Apparent diffusion coefficient (ADC) maps derived from diffusion weighted (DWI) MRI provides functional measurements about the water molecules in tissues. However, DWI is time consuming and very susceptible to image artifacts, leading to inaccurate ADC measurements. This study aims to develop a deep learning framework to synthesize ADC maps from multi-parametric MR images. Methods: We proposed the multiparametric residual vision transformer model (MPR-ViT) that leverages the long-range context of ViT layers along with the precision of convolutional operators. Residual blocks throughout the network significantly increasing the representational power of the model. The MPR-ViT model was applied to T1w and T2- fluid attenuated inversion recovery images of 501 glioma cases from a publicly available dataset including preprocessed ADC maps. Selected patients were divided into training (N=400), validation (N=50) and test (N=51) sets, respectively. Using the preprocessed ADC maps as ground truth, model performance was evaluated and compared against the Vision Convolutional Transformer (VCT) and residual vision transformer (ResViT) models. Results: The results are as follows using T1w + T2-FLAIR MRI as inputs: MPR-ViT - PSNR: 31.0 +/- 2.1, MSE: 0.009 +/- 0.0005, SSIM: 0.950 +/- 0.015. In addition, ablation studies showed the relative impact on performance of each input sequence. Both qualitative and quantitative results indicate that the proposed MR- ViT model performs favorably against the ground truth data. Conclusion: We show that high-quality ADC maps can be synthesized from structural MRI using a MPR- VCT model. Our predicted images show better conformality to the ground truth volume than ResViT and VCT predictions. These high-quality synthetic ADC maps would be particularly useful for disease diagnosis and intervention, especially when ADC maps have artifacts or are unavailable.