 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Vision Mamba for MRI Super-Resolution via Hybrid Selective Scanning
Dec 22, 2025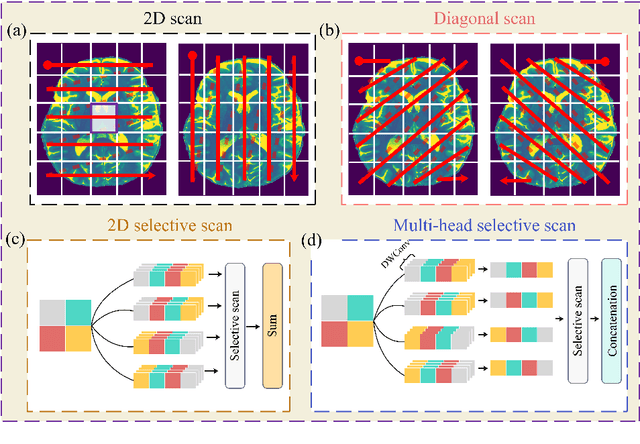
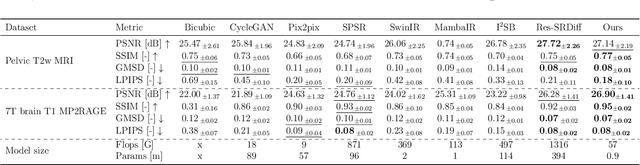
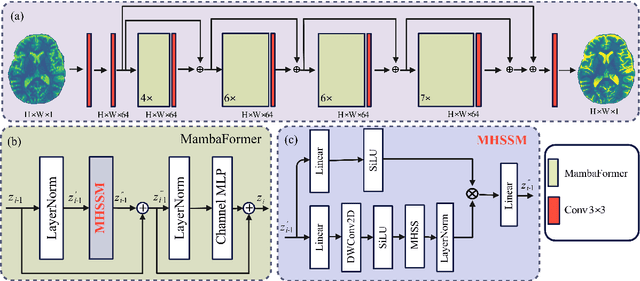

Background: High-resolution MRI is critical for diagnosis, but long acquisition times limit clinical use. Super-resolution (SR) can enhance resolution post-scan, yet existing deep learning methods face fidelity-efficiency trade-offs. Purpose: To develop a computationally efficient and accurate deep learning framework for MRI SR that preserves anatomical detail for clinical integration. Materials and Methods: We propose a novel SR framework combining multi-head selective state-space models (MHSSM) with a lightweight channel MLP. The model uses 2D patch extraction with hybrid scanning to capture long-range dependencies. Each MambaFormer block integrates MHSSM, depthwise convolutions, and gated channel mixing. Evaluation used 7T brain T1 MP2RAGE maps (n=142) and 1.5T prostate T2w MRI (n=334). Comparisons included Bicubic interpolation, GANs (CycleGAN, Pix2pix, SPSR), transformers (SwinIR), Mamba (MambaIR), and diffusion models (I2SB, Res-SRDiff). Results: Our model achieved superior performance with exceptional efficiency. For 7T brain data: SSIM=0.951+-0.021, PSNR=26.90+-1.41 dB, LPIPS=0.076+-0.022, GMSD=0.083+-0.017, significantly outperforming all baselines (p<0.001). For prostate data: SSIM=0.770+-0.049, PSNR=27.15+-2.19 dB, LPIPS=0.190+-0.095, GMSD=0.087+-0.013. The framework used only 0.9M parameters and 57 GFLOPs, reducing parameters by 99.8% and computation by 97.5% versus Res-SRDiff, while outperforming SwinIR and MambaIR in accuracy and efficiency. Conclusion: The proposed framework provides an efficient, accurate MRI SR solution, delivering enhanced anatomical detail across datasets. Its low computational demand and state-of-the-art performance show strong potential for clinical translation.
DINOv3 with Test-Time Training for Medical Image Registration
Aug 20, 2025Prior medical image registration approaches, particularly learning-based methods, often require large amounts of training data, which constrains clinical adoption. To overcome this limitation, we propose a training-free pipeline that relies on a frozen DINOv3 encoder and test-time optimization of the deformation field in feature space. Across two representative benchmarks, the method is accurate and yields regular deformations. On Abdomen MR-CT, it attained the best mean Dice score (DSC) of 0.790 together with the lowest 95th percentile Hausdorff Distance (HD95) of 4.9+-5.0 and the lowest standard deviation of Log-Jacobian (SDLogJ) of 0.08+-0.02. On ACDC cardiac MRI, it improves mean DSC to 0.769 and reduces SDLogJ to 0.11 and HD95 to 4.8, a marked gain over the initial alignment. The results indicate that operating in a compact foundation feature space at test time offers a practical and general solution for clinical registration without additional training.
Limited-Angle CBCT Reconstruction via Geometry-Integrated Cycle-domain Denoising Diffusion Probabilistic Models
Jun 16, 2025



Cone-beam CT (CBCT) is widely used in clinical radiotherapy for image-guided treatment, improving setup accuracy, adaptive planning, and motion management. However, slow gantry rotation limits performance by introducing motion artifacts, blurring, and increased dose. This work aims to develop a clinically feasible method for reconstructing high-quality CBCT volumes from consecutive limited-angle acquisitions, addressing imaging challenges in time- or dose-constrained settings. We propose a limited-angle (LA) geometry-integrated cycle-domain (LA-GICD) framework for CBCT reconstruction, comprising two denoising diffusion probabilistic models (DDPMs) connected via analytic cone-beam forward and back projectors. A Projection-DDPM completes missing projections, followed by back-projection, and an Image-DDPM refines the volume. This dual-domain design leverages complementary priors from projection and image spaces to achieve high-quality reconstructions from limited-angle (<= 90 degrees) scans. Performance was evaluated against full-angle reconstruction. Four board-certified medical physicists conducted assessments. A total of 78 planning CTs in common CBCT geometries were used for training and evaluation. The method achieved a mean absolute error of 35.5 HU, SSIM of 0.84, and PSNR of 29.8 dB, with visibly reduced artifacts and improved soft-tissue clarity. LA-GICD's geometry-aware dual-domain learning, embedded in analytic forward/backward operators, enabled artifact-free, high-contrast reconstructions from a single 90-degree scan, reducing acquisition time and dose four-fold. LA-GICD improves limited-angle CBCT reconstruction with strong data fidelity and anatomical realism. It offers a practical solution for short-arc acquisitions, enhancing CBCT use in radiotherapy by providing clinically applicable images with reduced scan time and dose for more accurate, personalized treatments.
MRI motion correction via efficient residual-guided denoising diffusion probabilistic models
May 06, 2025Purpose: Motion artifacts in magnetic resonance imaging (MRI) significantly degrade image quality and impair quantitative analysis. Conventional mitigation strategies, such as repeated acquisitions or motion tracking, are costly and workflow-intensive. This study introduces Res-MoCoDiff, an efficient denoising diffusion probabilistic model tailored for MRI motion artifact correction. Methods: Res-MoCoDiff incorporates a novel residual error shifting mechanism in the forward diffusion process, aligning the noise distribution with motion-corrupted data and enabling an efficient four-step reverse diffusion. A U-net backbone enhanced with Swin-Transformer blocks conventional attention layers, improving adaptability across resolutions. Training employs a combined l1+l2 loss, which promotes image sharpness and reduces pixel-level errors. Res-MoCoDiff was evaluated on synthetic dataset generated using a realistic motion simulation framework and on an in-vivo dataset. Comparative analyses were conducted against established methods, including CycleGAN, Pix2pix, and MT-DDPM using quantitative metrics such as peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and normalized mean squared error (NMSE). Results: The proposed method demonstrated superior performance in removing motion artifacts across all motion severity levels. Res-MoCoDiff consistently achieved the highest SSIM and the lowest NMSE values, with a PSNR of up to 41.91+-2.94 dB for minor distortions. Notably, the average sampling time was reduced to 0.37 seconds per batch of two image slices, compared with 101.74 seconds for conventional approaches.
Triad: Vision Foundation Model for 3D Magnetic Resonance Imaging
Feb 23, 2025Vision foundation models (VFMs) are pre-trained on extensive image datasets to learn general representations for diverse types of data. These models can subsequently be fine-tuned for specific downstream tasks, significantly boosting performance across a broad range of applications. However, existing vision foundation models that claim to be applicable to various clinical tasks are mostly pre-trained on 3D computed tomography (CT), which benefits from the availability of extensive 3D CT databases. Significant differences between CT and magnetic resonance imaging (MRI) in imaging principles, signal characteristics, and data distribution may hinder their practical performance and versatility in MRI-specific applications. Here, we propose Triad, a vision foundation model for 3D MRI. Triad adopts a widely used autoencoder architecture to learn robust representations from 131,170 3D MRI volumes and uses organ-independent imaging descriptions to constrain the semantic distribution of the visual modality. The above pre-training dataset is called Triad-131K, which is currently the largest 3D MRI pre-training dataset. We evaluate Triad across three tasks, namely, organ/tumor segmentation, organ/cancer classification, and medical image registration, in two data modalities (within-domain and out-of-domain) settings using 25 downstream datasets. By initializing models with Triad's pre-trained weights, nnUNet-Triad improves segmentation performance by 2.51% compared to nnUNet-Scratch across 17 datasets. Swin-B-Triad achieves a 3.97% improvement over Swin-B-Scratch in classification tasks across five datasets. SwinUNETR-Triad improves by 4.00% compared to SwinUNETR-Scratch in registration tasks across two datasets. Our study demonstrates that pre-training can improve performance when the data modalities and organs of upstream and downstream tasks are consistent.
A Physics-Informed Deep Learning Model for MRI Brain Motion Correction
Feb 13, 2025Background: MRI is crucial for brain imaging but is highly susceptible to motion artifacts due to long acquisition times. This study introduces PI-MoCoNet, a physics-informed motion correction network that integrates spatial and k-space information to remove motion artifacts without explicit motion parameter estimation, enhancing image fidelity and diagnostic reliability. Materials and Methods: PI-MoCoNet consists of a motion detection network (U-net with spatial averaging) to identify corrupted k-space lines and a motion correction network (U-net with Swin Transformer blocks) to reconstruct motion-free images. The correction is guided by three loss functions: reconstruction (L1), perceptual (LPIPS), and data consistency (Ldc). Motion artifacts were simulated via rigid phase encoding perturbations and evaluated on IXI and MR-ART datasets against Pix2Pix, CycleGAN, and U-net using PSNR, SSIM, and NMSE. Results: PI-MoCoNet significantly improved image quality. On IXI, for minor artifacts, PSNR increased from 34.15 dB to 45.95 dB, SSIM from 0.87 to 1.00, and NMSE reduced from 0.55% to 0.04%. For moderate artifacts, PSNR improved from 30.23 dB to 42.16 dB, SSIM from 0.80 to 0.99, and NMSE from 1.32% to 0.09%. For heavy artifacts, PSNR rose from 27.99 dB to 36.01 dB, SSIM from 0.75 to 0.97, and NMSE decreased from 2.21% to 0.36%. On MR-ART, PI-MoCoNet achieved PSNR gains of ~10 dB and SSIM improvements of up to 0.20, with NMSE reductions of ~6%. Ablation studies confirmed the importance of data consistency and perceptual losses, yielding a 1 dB PSNR gain and 0.17% NMSE reduction. Conclusions: PI-MoCoNet effectively mitigates motion artifacts in brain MRI, outperforming existing methods. Its ability to integrate spatial and k-space information makes it a promising tool for clinical use in motion-prone settings. Code: https://github.com/mosaf/PI-MoCoNet.git.
Advancing MRI Reconstruction: A Systematic Review of Deep Learning and Compressed Sensing Integration
Jan 24, 2025
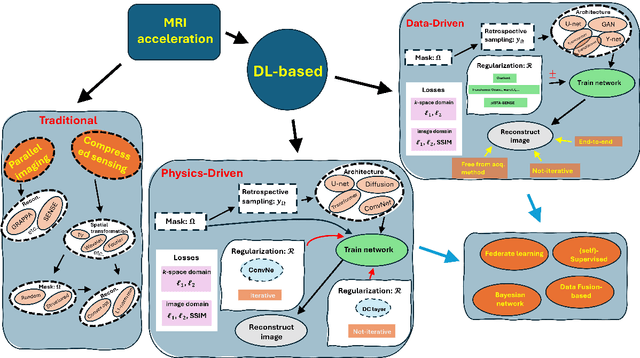

Magnetic resonance imaging (MRI) is a non-invasive imaging modality and provides comprehensive anatomical and functional insights into the human body. However, its long acquisition times can lead to patient discomfort, motion artifacts, and limiting real-time applications. To address these challenges, strategies such as parallel imaging have been applied, which utilize multiple receiver coils to speed up the data acquisition process. Additionally, compressed sensing (CS) is a method that facilitates image reconstruction from sparse data, significantly reducing image acquisition time by minimizing the amount of data collection needed. Recently, deep learning (DL) has emerged as a powerful tool for improving MRI reconstruction. It has been integrated with parallel imaging and CS principles to achieve faster and more accurate MRI reconstructions. This review comprehensively examines DL-based techniques for MRI reconstruction. We categorize and discuss various DL-based methods, including end-to-end approaches, unrolled optimization, and federated learning, highlighting their potential benefits. Our systematic review highlights significant contributions and underscores the potential of DL in MRI reconstruction. Additionally, we summarize key results and trends in DL-based MRI reconstruction, including quantitative metrics, the dataset, acceleration factors, and the progress of and research interest in DL techniques over time. Finally, we discuss potential future directions and the importance of DL-based MRI reconstruction in advancing medical imaging. To facilitate further research in this area, we provide a GitHub repository that includes up-to-date DL-based MRI reconstruction publications and public datasets-https://github.com/mosaf/Awesome-DL-based-CS-MRI.
Image-Domain Material Decomposition for Dual-energy CT using Unsupervised Learning with Data-fidelity Loss
Nov 17, 2023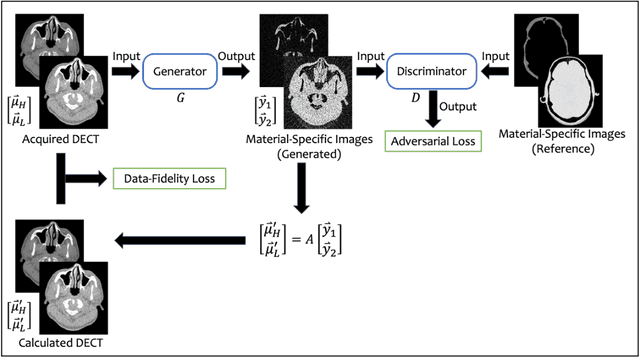
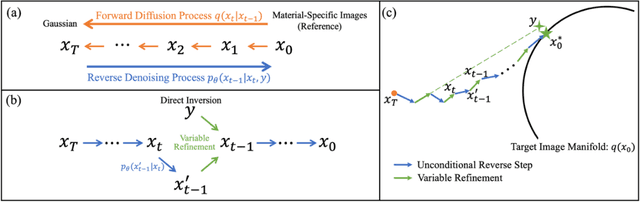
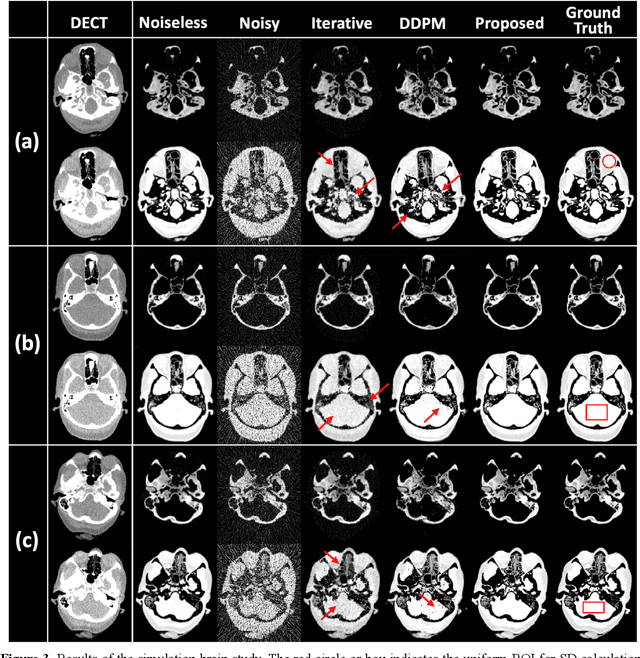
Background: Dual-energy CT (DECT) and material decomposition play vital roles in quantitative medical imaging. However, the decomposition process may suffer from significant noise amplification, leading to severely degraded image signal-to-noise ratios (SNRs). While existing iterative algorithms perform noise suppression using different image priors, these heuristic image priors cannot accurately represent the features of the target image manifold. Although deep learning-based decomposition methods have been reported, these methods are in the supervised-learning framework requiring paired data for training, which is not readily available in clinical settings. Purpose: This work aims to develop an unsupervised-learning framework with data-measurement consistency for image-domain material decomposition in DECT.
Full-dose PET Synthesis from Low-dose PET Using High-efficiency Diffusion Denoising Probabilistic Model
Aug 24, 2023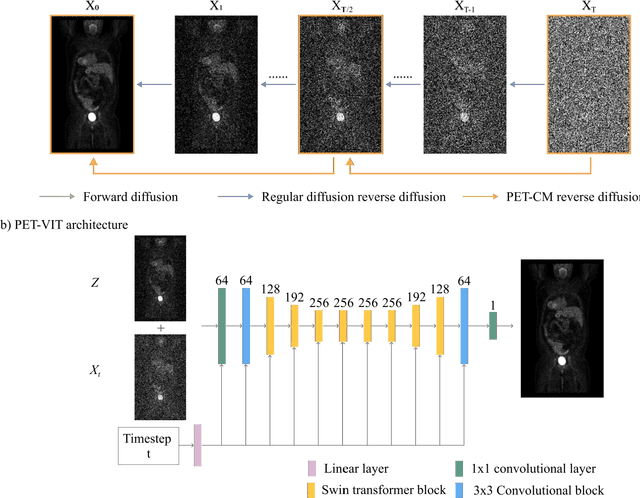


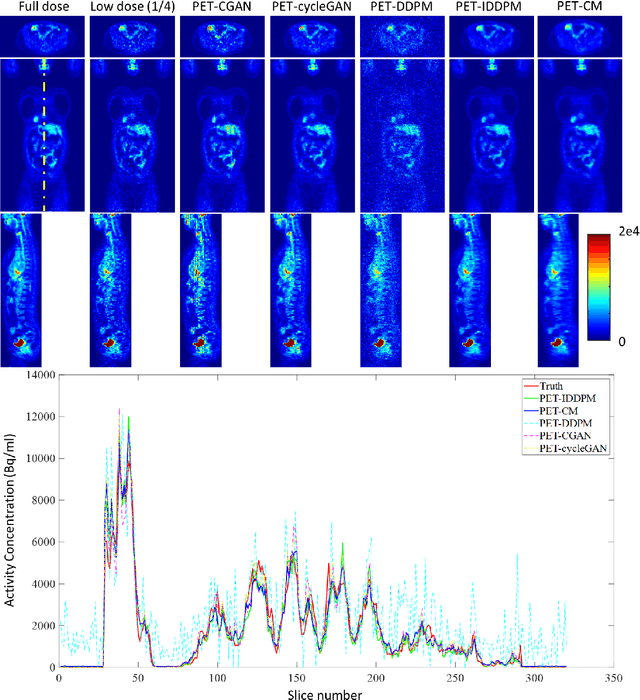
To reduce the risks associated with ionizing radiation, a reduction of radiation exposure in PET imaging is needed. However, this leads to a detrimental effect on image contrast and quantification. High-quality PET images synthesized from low-dose data offer a solution to reduce radiation exposure. We introduce a diffusion-model-based approach for estimating full-dose PET images from low-dose ones: the PET Consistency Model (PET-CM) yielding synthetic quality comparable to state-of-the-art diffusion-based synthesis models, but with greater efficiency. There are two steps: a forward process that adds Gaussian noise to a full dose PET image at multiple timesteps, and a reverse diffusion process that employs a PET Shifted-window Vision Transformer (PET-VIT) network to learn the denoising procedure conditioned on the corresponding low-dose PETs. In PET-CM, the reverse process learns a consistency function for direct denoising of Gaussian noise to a clean full-dose PET. We evaluated the PET-CM in generating full-dose images using only 1/8 and 1/4 of the standard PET dose. Comparing 1/8 dose to full-dose images, PET-CM demonstrated impressive performance with normalized mean absolute error (NMAE) of 1.233+/-0.131%, peak signal-to-noise ratio (PSNR) of 33.915+/-0.933dB, structural similarity index (SSIM) of 0.964+/-0.009, and normalized cross-correlation (NCC) of 0.968+/-0.011, with an average generation time of 62 seconds per patient. This is a significant improvement compared to the state-of-the-art diffusion-based model with PET-CM reaching this result 12x faster. In the 1/4 dose to full-dose image experiments, PET-CM is also competitive, achieving an NMAE 1.058+/-0.092%, PSNR of 35.548+/-0.805dB, SSIM of 0.978+/-0.005, and NCC 0.981+/-0.007 The results indicate promising low-dose PET image quality improvements for clinical applications.
Synthetic CT Generation from MRI using 3D Transformer-based Denoising Diffusion Model
May 31, 2023


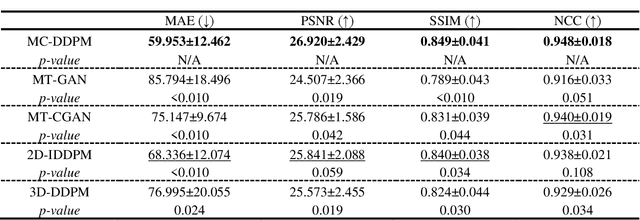
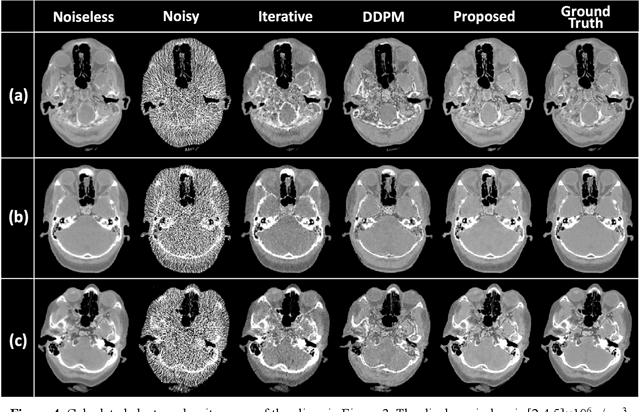
Magnetic resonance imaging (MRI)-based synthetic computed tomography (sCT) simplifies radiation therapy treatment planning by eliminating the need for CT simulation and error-prone image registration, ultimately reducing patient radiation dose and setup uncertainty. We propose an MRI-to-CT transformer-based denoising diffusion probabilistic model (MC-DDPM) to transform MRI into high-quality sCT to facilitate radiation treatment planning. MC-DDPM implements diffusion processes with a shifted-window transformer network to generate sCT from MRI. The proposed model consists of two processes: a forward process which adds Gaussian noise to real CT scans, and a reverse process in which a shifted-window transformer V-net (Swin-Vnet) denoises the noisy CT scans conditioned on the MRI from the same patient to produce noise-free CT scans. With an optimally trained Swin-Vnet, the reverse diffusion process was used to generate sCT scans matching MRI anatomy. We evaluated the proposed method by generating sCT from MRI on a brain dataset and a prostate dataset. Qualitative evaluation was performed using the mean absolute error (MAE) of Hounsfield unit (HU), peak signal to noise ratio (PSNR), multi-scale Structure Similarity index (MS-SSIM) and normalized cross correlation (NCC) indexes between ground truth CTs and sCTs. MC-DDPM generated brain sCTs with state-of-the-art quantitative results with MAE 43.317 HU, PSNR 27.046 dB, SSIM 0.965, and NCC 0.983. For the prostate dataset, MC-DDPM achieved MAE 59.953 HU, PSNR 26.920 dB, SSIM 0.849, and NCC 0.948. In conclusion, we have developed and validated a novel approach for generating CT images from routine MRIs using a transformer-based DDPM. This model effectively captures the complex relationship between CT and MRI images, allowing for robust and high-quality synthetic CT (sCT) images to be generated in minutes.