 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Physics-Informed Deep Learning Model for MRI Brain Motion Correction
Feb 13, 2025Background: MRI is crucial for brain imaging but is highly susceptible to motion artifacts due to long acquisition times. This study introduces PI-MoCoNet, a physics-informed motion correction network that integrates spatial and k-space information to remove motion artifacts without explicit motion parameter estimation, enhancing image fidelity and diagnostic reliability. Materials and Methods: PI-MoCoNet consists of a motion detection network (U-net with spatial averaging) to identify corrupted k-space lines and a motion correction network (U-net with Swin Transformer blocks) to reconstruct motion-free images. The correction is guided by three loss functions: reconstruction (L1), perceptual (LPIPS), and data consistency (Ldc). Motion artifacts were simulated via rigid phase encoding perturbations and evaluated on IXI and MR-ART datasets against Pix2Pix, CycleGAN, and U-net using PSNR, SSIM, and NMSE. Results: PI-MoCoNet significantly improved image quality. On IXI, for minor artifacts, PSNR increased from 34.15 dB to 45.95 dB, SSIM from 0.87 to 1.00, and NMSE reduced from 0.55% to 0.04%. For moderate artifacts, PSNR improved from 30.23 dB to 42.16 dB, SSIM from 0.80 to 0.99, and NMSE from 1.32% to 0.09%. For heavy artifacts, PSNR rose from 27.99 dB to 36.01 dB, SSIM from 0.75 to 0.97, and NMSE decreased from 2.21% to 0.36%. On MR-ART, PI-MoCoNet achieved PSNR gains of ~10 dB and SSIM improvements of up to 0.20, with NMSE reductions of ~6%. Ablation studies confirmed the importance of data consistency and perceptual losses, yielding a 1 dB PSNR gain and 0.17% NMSE reduction. Conclusions: PI-MoCoNet effectively mitigates motion artifacts in brain MRI, outperforming existing methods. Its ability to integrate spatial and k-space information makes it a promising tool for clinical use in motion-prone settings. Code: https://github.com/mosaf/PI-MoCoNet.git.
Understanding and Mitigating Extrapolation Failures in Physics-Informed Neural Networks
Jun 15, 2023Physics-informed Neural Networks (PINNs) have recently gained popularity in the scientific community due to their effective approximation of partial differential equations (PDEs) using deep neural networks. However, their application has been generally limited to interpolation scenarios, where predictions rely on inputs within the support of the training set. In real-world applications, extrapolation is often required, but the out of domain behavior of PINNs is understudied. In this paper, we provide a detailed investigation of PINNs' extrapolation behavior and provide evidence against several previously held assumptions: we study the effects of different model choices on extrapolation and find that once the model can achieve zero interpolation error, further increases in architecture size or in the number of points sampled have no effect on extrapolation behavior. We also show that for some PDEs, PINNs perform nearly as well in extrapolation as in interpolation. By analyzing the Fourier spectra of the solution functions, we characterize the PDEs that yield favorable extrapolation behavior, and show that the presence of high frequencies in the solution function is not to blame for poor extrapolation behavior. Finally, we propose a transfer learning-based strategy based on our Fourier results, which decreases extrapolation errors in PINNs by up to $82 \%$.
Automatic Fake News Detection: Are current models "fact-checking" or "gut-checking"?
Apr 14, 2022
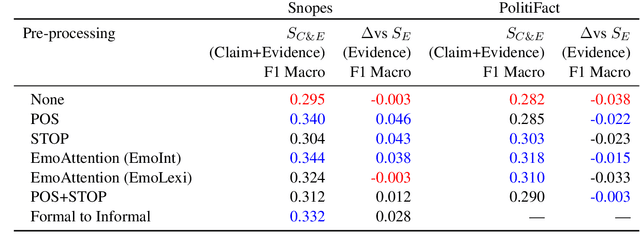
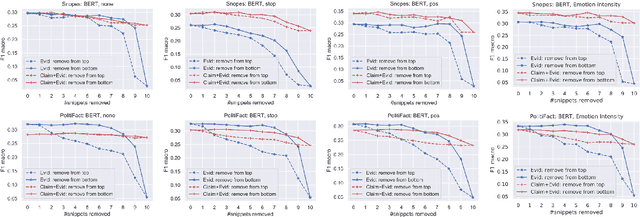
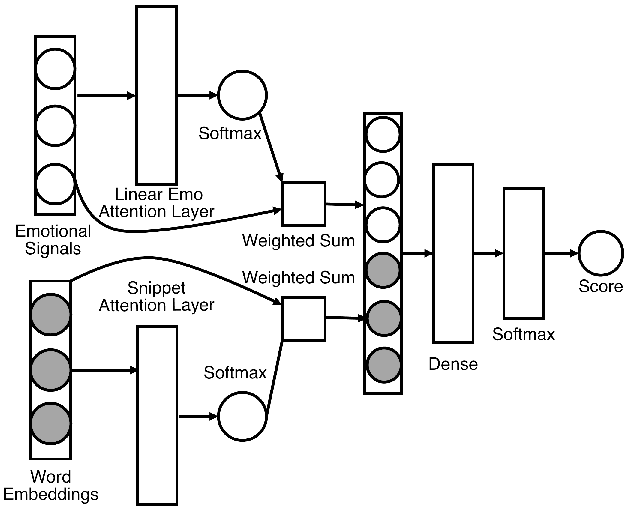
Automatic fake news detection models are ostensibly based on logic, where the truth of a claim made in a headline can be determined by supporting or refuting evidence found in a resulting web query. These models are believed to be reasoning in some way; however, it has been shown that these same results, or better, can be achieved without considering the claim at all -- only the evidence. This implies that other signals are contained within the examined evidence, and could be based on manipulable factors such as emotion, sentiment, or part-of-speech (POS) frequencies, which are vulnerable to adversarial inputs. We neutralize some of these signals through multiple forms of both neural and non-neural pre-processing and style transfer, and find that this flattening of extraneous indicators can induce the models to actually require both claims and evidence to perform well. We conclude with the construction of a model using emotion vectors built off a lexicon and passed through an "emotional attention" mechanism to appropriately weight certain emotions. We provide quantifiable results that prove our hypothesis that manipulable features are being used for fact-checking.