 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning modularity
Jan 05, 2026Based on a transformer based sequence-to-sequence architecture combined with a dynamic batching algorithm, this work introduces a machine learning framework for automatically simplifying complex expressions involving multiple elliptic Gamma functions, including the $q$-$θ$ function and the elliptic Gamma function. The model learns to apply algebraic identities, particularly the SL$(2,\mathbb{Z})$ and SL$(3,\mathbb{Z})$ modular transformations, to reduce heavily scrambled expressions to their canonical forms. Experimental results show that the model achieves over 99\% accuracy on in-distribution tests and maintains robust performance (exceeding 90\% accuracy) under significant extrapolation, such as with deeper scrambling depths. This demonstrates that the model has internalized the underlying algebraic rules of modular transformations rather than merely memorizing training patterns. Our work presents the first successful application of machine learning to perform symbolic simplification using modular identities, offering a new automated tool for computations with special functions in quantum field theory and the string theory.
Weakly Supervised Spatial Implicit Neural Representation Learning for 3D MRI-Ultrasound Deformable Image Registration in HDR Prostate Brachytherapy
Mar 18, 2025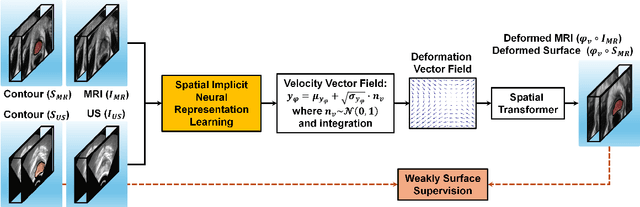



Purpose: Accurate 3D MRI-ultrasound (US) deformable registration is critical for real-time guidance in high-dose-rate (HDR) prostate brachytherapy. We present a weakly supervised spatial implicit neural representation (SINR) method to address modality differences and pelvic anatomy challenges. Methods: The framework uses sparse surface supervision from MRI/US segmentations instead of dense intensity matching. SINR models deformations as continuous spatial functions, with patient-specific surface priors guiding a stationary velocity field for biologically plausible deformations. Validation included 20 public Prostate-MRI-US-Biopsy cases and 10 institutional HDR cases, evaluated via Dice similarity coefficient (DSC), mean surface distance (MSD), and 95% Hausdorff distance (HD95). Results: The proposed method achieved robust registration. For the public dataset, prostate DSC was $0.93 \pm 0.05$, MSD $0.87 \pm 0.10$ mm, and HD95 $1.58 \pm 0.37$ mm. For the institutional dataset, prostate CTV achieved DSC $0.88 \pm 0.09$, MSD $1.21 \pm 0.38$ mm, and HD95 $2.09 \pm 1.48$ mm. Bladder and rectum performance was lower due to ultrasound's limited field of view. Visual assessments confirmed accurate alignment with minimal discrepancies. Conclusion: This study introduces a novel weakly supervised SINR-based approach for 3D MRI-US deformable registration. By leveraging sparse surface supervision and spatial priors, it achieves accurate, robust, and computationally efficient registration, enhancing real-time image guidance in HDR prostate brachytherapy and improving treatment precision.
Diffeomorphic Transformer-based Abdomen MRI-CT Deformable Image Registration
May 04, 2024



This paper aims to create a deep learning framework that can estimate the deformation vector field (DVF) for directly registering abdominal MRI-CT images. The proposed method assumed a diffeomorphic deformation. By using topology-preserved deformation features extracted from the probabilistic diffeomorphic registration model, abdominal motion can be accurately obtained and utilized for DVF estimation. The model integrated Swin transformers, which have demonstrated superior performance in motion tracking, into the convolutional neural network (CNN) for deformation feature extraction. The model was optimized using a cross-modality image similarity loss and a surface matching loss. To compute the image loss, a modality-independent neighborhood descriptor (MIND) was used between the deformed MRI and CT images. The surface matching loss was determined by measuring the distance between the warped coordinates of the surfaces of contoured structures on the MRI and CT images. The deformed MRI image was assessed against the CT image using the target registration error (TRE), Dice similarity coefficient (DSC), and mean surface distance (MSD) between the deformed contours of the MRI image and manual contours of the CT image. When compared to only rigid registration, DIR with the proposed method resulted in an increase of the mean DSC values of the liver and portal vein from 0.850 and 0.628 to 0.903 and 0.763, a decrease of the mean MSD of the liver from 7.216 mm to 3.232 mm, and a decrease of the TRE from 26.238 mm to 8.492 mm. The proposed deformable image registration method based on a diffeomorphic transformer provides an effective and efficient way to generate an accurate DVF from an MRI-CT image pair of the abdomen. It could be utilized in the current treatment planning workflow for liver radiotherapy.
RotaTR: Detection Transformer for Dense and Rotated Object
Dec 05, 2023



Detecting the objects in dense and rotated scenes is a challenging task. Recent works on this topic are mostly based on Faster RCNN or Retinanet. As they are highly dependent on the pre-set dense anchors and the NMS operation, the approach is indirect and suboptimal.The end-to-end DETR-based detectors have achieved great success in horizontal object detection and many other areas like segmentation, tracking, action recognition and etc.However, the DETR-based detectors perform poorly on dense rotated target tasks and perform worse than most modern CNN-based detectors. In this paper, we find the most significant reason for the poor performance is that the original attention can not accurately focus on the oriented targets. Accordingly, we propose Rotated object detection TRansformer (RotaTR) as an extension of DETR to oriented detection. Specifically, we design Rotation Sensitive deformable (RSDeform) attention to enhance the DETR's ability to detect oriented targets. It is used to build the feature alignment module and rotation-sensitive decoder for our model. We test RotaTR on four challenging-oriented benchmarks. It shows a great advantage in detecting dense and oriented objects compared to the original DETR. It also achieves competitive results when compared to the state-of-the-art.
CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
Nov 10, 2023



Large language models (LLMs) have demonstrated great potential in the financial domain. Thus, it becomes important to assess the performance of LLMs in the financial tasks. In this work, we introduce CFBenchmark, to evaluate the performance of LLMs for Chinese financial assistant. The basic version of CFBenchmark is designed to evaluate the basic ability in Chinese financial text processing from three aspects~(\emph{i.e.} recognition, classification, and generation) including eight tasks, and includes financial texts ranging in length from 50 to over 1,800 characters. We conduct experiments on several LLMs available in the literature with CFBenchmark-Basic, and the experimental results indicate that while some LLMs show outstanding performance in specific tasks, overall, there is still significant room for improvement in basic tasks of financial text processing with existing models. In the future, we plan to explore the advanced version of CFBenchmark, aiming to further explore the extensive capabilities of language models in more profound dimensions as a financial assistant in Chinese. Our codes are released at https://github.com/TongjiFinLab/CFBenchmark.
CFGPT: Chinese Financial Assistant with Large Language Model
Sep 22, 2023



Large language models (LLMs) have demonstrated great potential in natural language processing tasks within the financial domain. In this work, we present a Chinese Financial Generative Pre-trained Transformer framework, named CFGPT, which includes a dataset~(CFData) for pre-training and supervised fine-tuning, a financial LLM~(CFLLM) to adeptly manage financial texts, and a deployment framework~(CFAPP) designed to navigate real-world financial applications. The CFData comprising both a pre-training dataset and a supervised fine-tuning dataset, where the pre-training dataset collates Chinese financial data and analytics, alongside a smaller subset of general-purpose text with 584M documents and 141B tokens in total, and the supervised fine-tuning dataset is tailored for six distinct financial tasks, embodying various facets of financial analysis and decision-making with 1.5M instruction pairs and 1.5B tokens in total. The CFLLM, which is based on InternLM-7B to balance the model capability and size, is trained on CFData in two stage, continued pre-training and supervised fine-tuning. The CFAPP is centered on large language models (LLMs) and augmented with additional modules to ensure multifaceted functionality in real-world application. Our codes are released at https://github.com/TongjiFinLab/CFGPT.
Landmark Tracking in Liver US images Using Cascade Convolutional Neural Networks with Long Short-Term Memory
Sep 14, 2022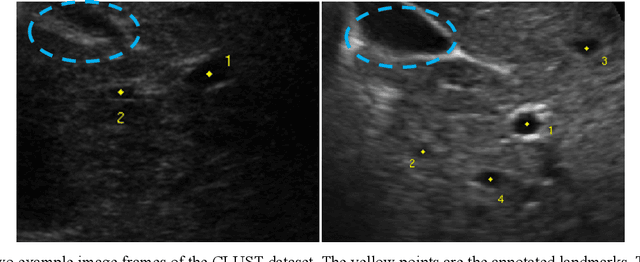
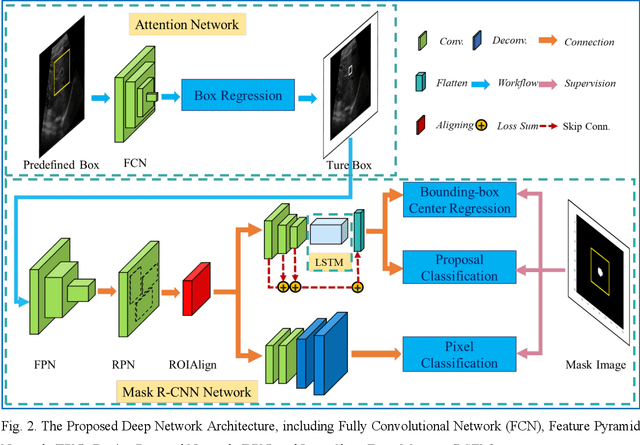
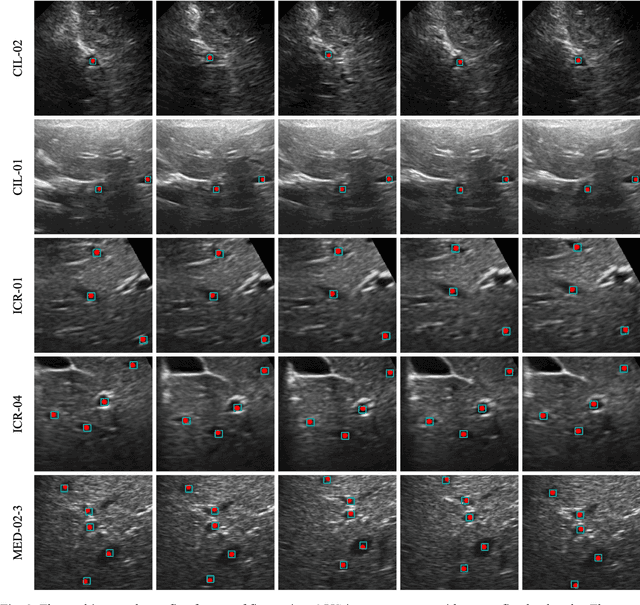
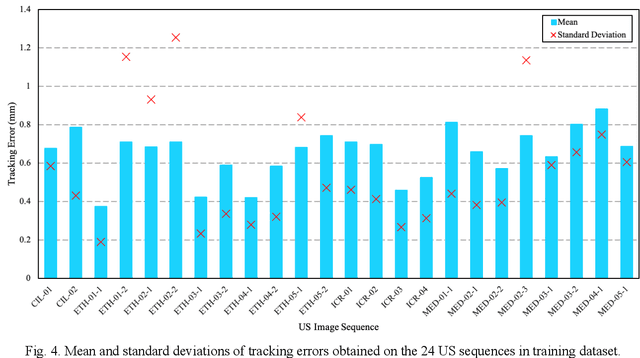
This study proposed a deep learning-based tracking method for ultrasound (US) image-guided radiation therapy. The proposed cascade deep learning model is composed of an attention network, a mask region-based convolutional neural network (mask R-CNN), and a long short-term memory (LSTM) network. The attention network learns a mapping from a US image to a suspected area of landmark motion in order to reduce the search region. The mask R-CNN then produces multiple region-of-interest (ROI) proposals in the reduced region and identifies the proposed landmark via three network heads: bounding box regression, proposal classification, and landmark segmentation. The LSTM network models the temporal relationship among the successive image frames for bounding box regression and proposal classification. To consolidate the final proposal, a selection method is designed according to the similarities between sequential frames. The proposed method was tested on the liver US tracking datasets used in the Medical Image Computing and Computer Assisted Interventions (MICCAI) 2015 challenges, where the landmarks were annotated by three experienced observers to obtain their mean positions. Five-fold cross-validation on the 24 given US sequences with ground truths shows that the mean tracking error for all landmarks is 0.65+/-0.56 mm, and the errors of all landmarks are within 2 mm. We further tested the proposed model on 69 landmarks from the testing dataset that has a similar image pattern to the training pattern, resulting in a mean tracking error of 0.94+/-0.83 mm. Our experimental results have demonstrated the feasibility and accuracy of our proposed method in tracking liver anatomic landmarks using US images, providing a potential solution for real-time liver tracking for active motion management during radiation therapy.
Deformable Image Registration using Unsupervised Deep Learning for CBCT-guided Abdominal Radiotherapy
Aug 29, 2022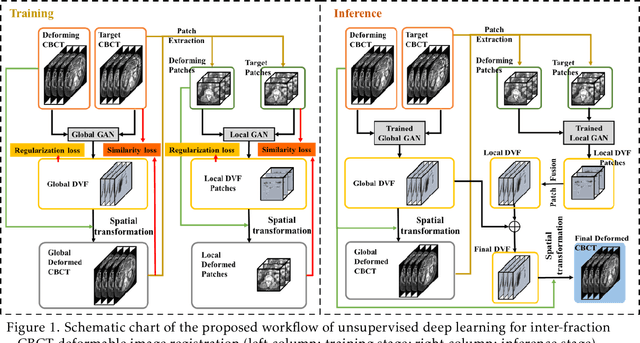
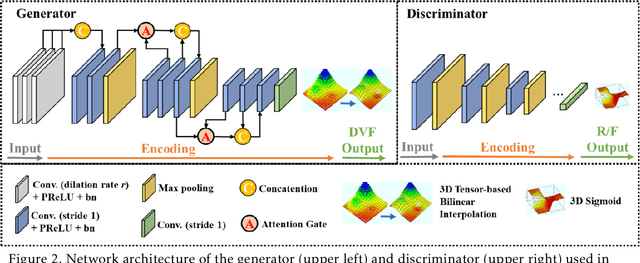
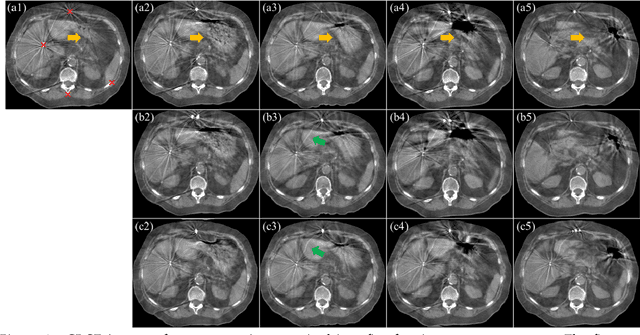
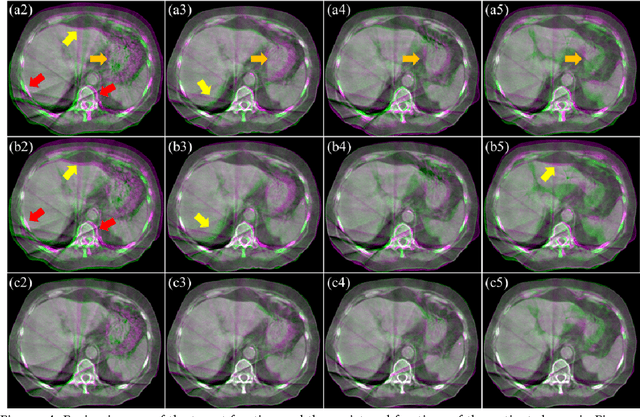
CBCTs in image-guided radiotherapy provide crucial anatomy information for patient setup and plan evaluation. Longitudinal CBCT image registration could quantify the inter-fractional anatomic changes. The purpose of this study is to propose an unsupervised deep learning based CBCT-CBCT deformable image registration. The proposed deformable registration workflow consists of training and inference stages that share the same feed-forward path through a spatial transformation-based network (STN). The STN consists of a global generative adversarial network (GlobalGAN) and a local GAN (LocalGAN) to predict the coarse- and fine-scale motions, respectively. The network was trained by minimizing the image similarity loss and the deformable vector field (DVF) regularization loss without the supervision of ground truth DVFs. During the inference stage, patches of local DVF were predicted by the trained LocalGAN and fused to form a whole-image DVF. The local whole-image DVF was subsequently combined with the GlobalGAN generated DVF to obtain final DVF. The proposed method was evaluated using 100 fractional CBCTs from 20 abdominal cancer patients in the experiments and 105 fractional CBCTs from a cohort of 21 different abdominal cancer patients in a holdout test. Qualitatively, the registration results show great alignment between the deformed CBCT images and the target CBCT image. Quantitatively, the average target registration error (TRE) calculated on the fiducial markers and manually identified landmarks was 1.91+-1.11 mm. The average mean absolute error (MAE), normalized cross correlation (NCC) between the deformed CBCT and target CBCT were 33.42+-7.48 HU, 0.94+-0.04, respectively. This promising registration method could provide fast and accurate longitudinal CBCT alignment to facilitate inter-fractional anatomic changes analysis and prediction.
Artificial Intelligence in Tumor Subregion Analysis Based on Medical Imaging: A Review
Mar 25, 2021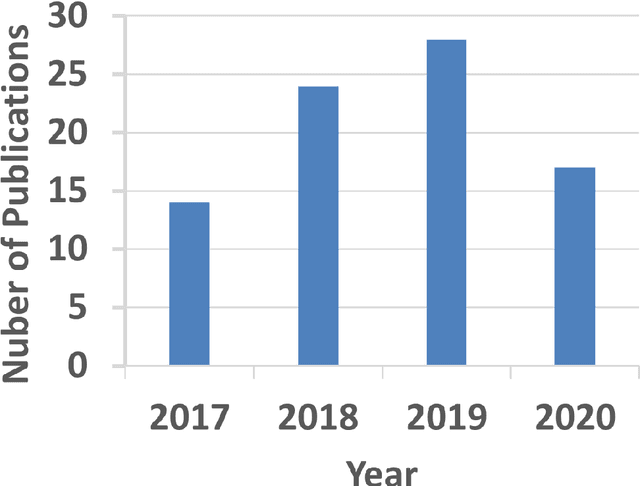
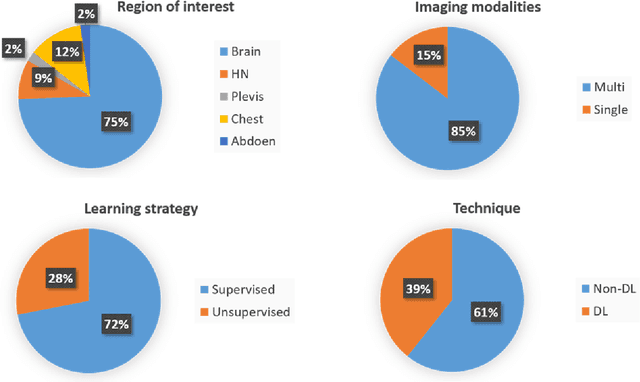

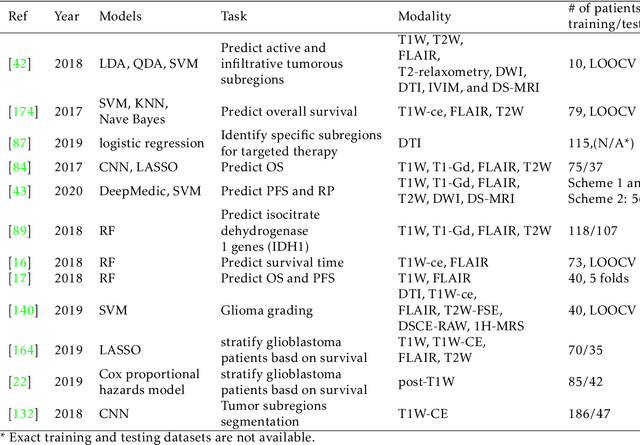
Medical imaging is widely used in cancer diagnosis and treatment, and artificial intelligence (AI) has achieved tremendous success in various tasks of medical image analysis. This paper reviews AI-based tumor subregion analysis in medical imaging. We summarize the latest AI-based methods for tumor subregion analysis and their applications. Specifically, we categorize the AI-based methods by training strategy: supervised and unsupervised. A detailed review of each category is presented, highlighting important contributions and achievements. Specific challenges and potential AI applications in tumor subregion analysis are discussed.
Generative Adversarial Network for Image Synthesis
Dec 31, 2020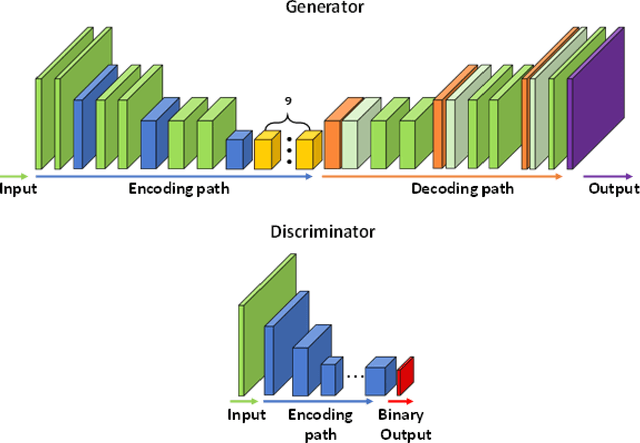
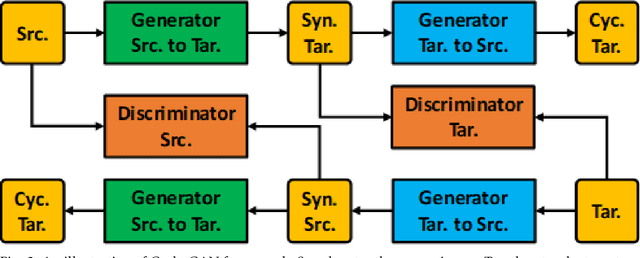
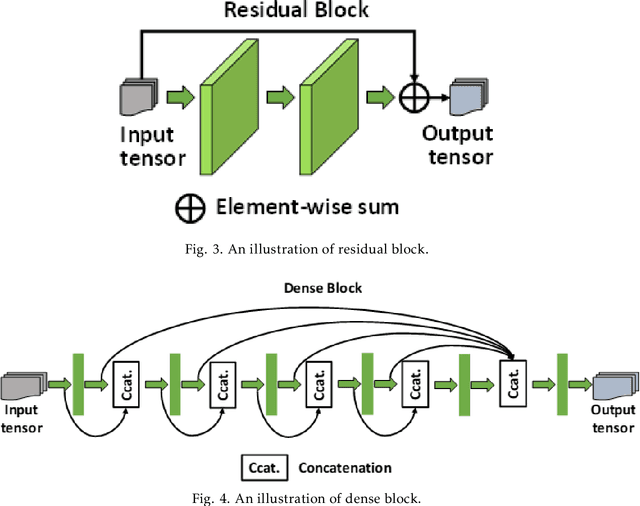
This chapter reviews recent developments of generative adversarial networks (GAN)-based methods for medical and biomedical image synthesis tasks. These methods are classified into conditional GAN and Cycle-GAN according to the network architecture designs. For each category, a literature survey is given, which covers discussions of the network architecture designs, highlights important contributions and identifies specific challenges.