 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRATIONALYST: Pre-training Process-Supervision for Improving Reasoning
Oct 01, 2024



The reasoning steps generated by LLMs might be incomplete, as they mimic logical leaps common in everyday communication found in their pre-training data: underlying rationales are frequently left implicit (unstated). To address this challenge, we introduce RATIONALYST, a model for process-supervision of reasoning based on pre-training on a vast collection of rationale annotations extracted from unlabeled data. We extract 79k rationales from web-scale unlabelled dataset (the Pile) and a combination of reasoning datasets with minimal human intervention. This web-scale pre-training for reasoning allows RATIONALYST to consistently generalize across diverse reasoning tasks, including mathematical, commonsense, scientific, and logical reasoning. Fine-tuned from LLaMa-3-8B, RATIONALYST improves the accuracy of reasoning by an average of 3.9% on 7 representative reasoning benchmarks. It also demonstrates superior performance compared to significantly larger verifiers like GPT-4 and similarly sized models fine-tuned on matching training sets.
FinGPT-HPC: Efficient Pretraining and Finetuning Large Language Models for Financial Applications with High-Performance Computing
Feb 21, 2024Large language models (LLMs) are computationally intensive. The computation workload and the memory footprint grow quadratically with the dimension (layer width). Most of LLMs' parameters come from the linear layers of the transformer structure and are highly redundant. These linear layers contribute more than 80% of the computation workload and 99% of the model size. To pretrain and finetune LLMs efficiently, there are three major challenges to address: 1) reducing redundancy of the linear layers; 2) reducing GPU memory footprint; 3) improving GPU utilization when using distributed training. Prior methods, such as LoRA and QLoRA, utilized low-rank matrices and quantization to reduce the number of trainable parameters and model size, respectively. However, the resulting model still consumes a large amount of GPU memory. In this paper, we present high-performance GPU-based methods that exploit low-rank structures to pretrain and finetune LLMs for financial applications. We replace one conventional linear layer of the transformer structure with two narrower linear layers, which allows us to reduce the number of parameters by several orders of magnitude. By quantizing the parameters into low precision (8-bit and 4-bit), the memory consumption of the resulting model is further reduced. Compared with existing LLMs, our methods achieve a speedup of 1.3X and a model compression ratio of 2.64X for pretaining without accuracy drop. For finetuning, our methods achieve an average accuracy increase of 6.3% and 24.0% in general tasks and financial tasks, respectively, and GPU memory consumption ratio of 6.3X. The sizes of our models are smaller than 0.59 GB, allowing inference on a smartphone.
CFGPT: Chinese Financial Assistant with Large Language Model
Sep 22, 2023



Large language models (LLMs) have demonstrated great potential in natural language processing tasks within the financial domain. In this work, we present a Chinese Financial Generative Pre-trained Transformer framework, named CFGPT, which includes a dataset~(CFData) for pre-training and supervised fine-tuning, a financial LLM~(CFLLM) to adeptly manage financial texts, and a deployment framework~(CFAPP) designed to navigate real-world financial applications. The CFData comprising both a pre-training dataset and a supervised fine-tuning dataset, where the pre-training dataset collates Chinese financial data and analytics, alongside a smaller subset of general-purpose text with 584M documents and 141B tokens in total, and the supervised fine-tuning dataset is tailored for six distinct financial tasks, embodying various facets of financial analysis and decision-making with 1.5M instruction pairs and 1.5B tokens in total. The CFLLM, which is based on InternLM-7B to balance the model capability and size, is trained on CFData in two stage, continued pre-training and supervised fine-tuning. The CFAPP is centered on large language models (LLMs) and augmented with additional modules to ensure multifaceted functionality in real-world application. Our codes are released at https://github.com/TongjiFinLab/CFGPT.
FinGPT: Democratizing Internet-scale Data for Financial Large Language Models
Jul 19, 2023
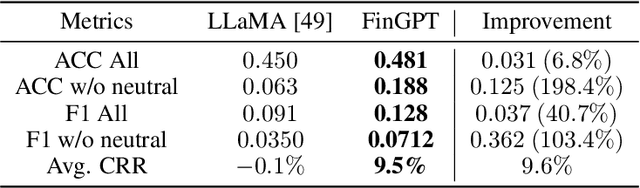


Large language models (LLMs) have demonstrated remarkable proficiency in understanding and generating human-like texts, which may potentially revolutionize the finance industry. However, existing LLMs often fall short in the financial field, which is mainly attributed to the disparities between general text data and financial text data. Unfortunately, there is only a limited number of financial text datasets available (quite small size), and BloombergGPT, the first financial LLM (FinLLM), is close-sourced (only the training logs were released). In light of this, we aim to democratize Internet-scale financial data for LLMs, which is an open challenge due to diverse data sources, low signal-to-noise ratio, and high time-validity. To address the challenges, we introduce an open-sourced and data-centric framework, \textit{Financial Generative Pre-trained Transformer (FinGPT)}, that automates the collection and curation of real-time financial data from >34 diverse sources on the Internet, providing researchers and practitioners with accessible and transparent resources to develop their FinLLMs. Additionally, we propose a simple yet effective strategy for fine-tuning FinLLM using the inherent feedback from the market, dubbed Reinforcement Learning with Stock Prices (RLSP). We also adopt the Low-rank Adaptation (LoRA, QLoRA) method that enables users to customize their own FinLLMs from open-source general-purpose LLMs at a low cost. Finally, we showcase several FinGPT applications, including robo-advisor, sentiment analysis for algorithmic trading, and low-code development. FinGPT aims to democratize FinLLMs, stimulate innovation, and unlock new opportunities in open finance. The codes are available at https://github.com/AI4Finance-Foundation/FinGPT and https://github.com/AI4Finance-Foundation/FinNLP