 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Decomposition for Optimal Claim Verification
Mar 19, 2025Current research on the \textit{Decompose-Then-Verify} paradigm for evaluating the factuality of long-form text typically treats decomposition and verification in isolation, overlooking their interactions and potential misalignment. We find that existing decomposition policies, typically hand-crafted demonstrations, do not align well with downstream verifiers in terms of atomicity -- a novel metric quantifying information density -- leading to suboptimal verification results. We formulate finding the optimal decomposition policy for optimal verification as a bilevel optimization problem. To approximate a solution for this strongly NP-hard problem, we propose dynamic decomposition, a reinforcement learning framework that leverages verifier feedback to learn a policy for dynamically decomposing claims to verifier-preferred atomicity. Experimental results show that dynamic decomposition outperforms existing decomposition policies, improving verification confidence by 0.07 and accuracy by 0.12 (on a 0-1 scale) on average across varying verifiers, datasets, and atomcities of input claims.
RATIONALYST: Pre-training Process-Supervision for Improving Reasoning
Oct 01, 2024The reasoning steps generated by LLMs might be incomplete, as they mimic logical leaps common in everyday communication found in their pre-training data: underlying rationales are frequently left implicit (unstated). To address this challenge, we introduce RATIONALYST, a model for process-supervision of reasoning based on pre-training on a vast collection of rationale annotations extracted from unlabeled data. We extract 79k rationales from web-scale unlabelled dataset (the Pile) and a combination of reasoning datasets with minimal human intervention. This web-scale pre-training for reasoning allows RATIONALYST to consistently generalize across diverse reasoning tasks, including mathematical, commonsense, scientific, and logical reasoning. Fine-tuned from LLaMa-3-8B, RATIONALYST improves the accuracy of reasoning by an average of 3.9% on 7 representative reasoning benchmarks. It also demonstrates superior performance compared to significantly larger verifiers like GPT-4 and similarly sized models fine-tuned on matching training sets.
Benchmarking Language Model Creativity: A Case Study on Code Generation
Jul 12, 2024As LLMs become increasingly prevalent, it is interesting to consider how ``creative'' these models can be. From cognitive science, creativity consists of at least two key characteristics: \emph{convergent} thinking (purposefulness to achieve a given goal) and \emph{divergent} thinking (adaptability to new environments or constraints) \citep{runco2003critical}. In this work, we introduce a framework for quantifying LLM creativity that incorporates the two characteristics. This is achieved by (1) Denial Prompting pushes LLMs to come up with more creative solutions to a given problem by incrementally imposing new constraints on the previous solution, compelling LLMs to adopt new strategies, and (2) defining and computing the NeoGauge metric which examines both convergent and divergent thinking in the generated creative responses by LLMs. We apply the proposed framework on Codeforces problems, a natural data source for collecting human coding solutions. We quantify NeoGauge for various proprietary and open-source models and find that even the most creative model, GPT-4, still falls short of demonstrating human-like creativity. We also experiment with advanced reasoning strategies (MCTS, self-correction, etc.) and observe no significant improvement in creativity. As a by-product of our analysis, we release NeoCoder dataset for reproducing our results on future models.
RORA: Robust Free-Text Rationale Evaluation
Mar 01, 2024Free-text rationales play a pivotal role in explainable NLP, bridging the knowledge and reasoning gaps behind a model's decision-making. However, due to the diversity of potential reasoning paths and a corresponding lack of definitive ground truth, their evaluation remains a challenge. Existing evaluation metrics rely on the degree to which a rationale supports a target label, but we find these fall short in evaluating rationales that inadvertently leak the labels. To address this problem, we propose RORA, a Robust free-text Rationale evaluation against label leakage. RORA quantifies the new information supplied by a rationale to justify the label. This is achieved by assessing the conditional V-information \citep{hewitt-etal-2021-conditional} with a predictive family robust against leaky features that can be exploited by a small model. RORA consistently outperforms existing approaches in evaluating human-written, synthetic, or model-generated rationales, particularly demonstrating robustness against label leakage. We also show that RORA aligns well with human judgment, providing a more reliable and accurate measurement across diverse free-text rationales.
AnaloBench: Benchmarking the Identification of Abstract and Long-context Analogies
Feb 19, 2024Humans regularly engage in analogical thinking, relating personal experiences to current situations ($X$ is analogous to $Y$ because of $Z$). Analogical thinking allows humans to solve problems in creative ways, grasp difficult concepts, and articulate ideas more effectively. Can language models (LMs) do the same? To answer this question, we propose ANALOBENCH, a benchmark to determine analogical reasoning ability in LMs. Our benchmarking approach focuses on aspects of this ability that are common among humans: (i) recalling related experiences from a large amount of information, and (ii) applying analogical reasoning to complex and lengthy scenarios. We test a broad collection of proprietary models (e.g., GPT family, Claude V2) and open source models such as LLaMA2. As in prior results, scaling up LMs results in some performance boosts. Surprisingly, scale offers minimal gains when, (i) analogies involve lengthy scenarios, or (ii) recalling relevant scenarios from a large pool of information, a process analogous to finding a needle in a haystack. We hope these observations encourage further research in this field.
GEAR: Augmenting Language Models with Generalizable and Efficient Tool Resolution
Jul 17, 2023Augmenting large language models (LLM) to use external tools enhances their performance across a variety of tasks. However, prior works over-rely on task-specific demonstration of tool use that limits their generalizability and computational cost due to making many calls to large-scale LLMs. We introduce GEAR, a computationally efficient query-tool grounding algorithm that is generalizable to various tasks that require tool use while not relying on task-specific demonstrations. GEAR achieves better efficiency by delegating tool grounding and execution to small language models (SLM) and LLM, respectively; while leveraging semantic and pattern-based evaluation at both question and answer levels for generalizable tool grounding. We evaluate GEAR on 14 datasets across 6 downstream tasks, demonstrating its strong generalizability to novel tasks, tools and different SLMs. Despite offering more efficiency, GEAR achieves higher precision in tool grounding compared to prior strategies using LLM prompting, thus improving downstream accuracy at a reduced computational cost. For example, we demonstrate that GEAR-augmented GPT-J and GPT-3 outperform counterpart tool-augmented baselines because of better tool use.
ProtSi: Prototypical Siamese Network with Data Augmentation for Few-Shot Subjective Answer Evaluation
Nov 17, 2022Subjective answer evaluation is a time-consuming and tedious task, and the quality of the evaluation is heavily influenced by a variety of subjective personal characteristics. Instead, machine evaluation can effectively assist educators in saving time while also ensuring that evaluations are fair and realistic. However, most existing methods using regular machine learning and natural language processing techniques are generally hampered by a lack of annotated answers and poor model interpretability, making them unsuitable for real-world use. To solve these challenges, we propose ProtSi Network, a unique semi-supervised architecture that for the first time uses few-shot learning to subjective answer evaluation. To evaluate students' answers by similarity prototypes, ProtSi Network simulates the natural process of evaluator scoring answers by combining Siamese Network which consists of BERT and encoder layers with Prototypical Network. We employed an unsupervised diverse paraphrasing model ProtAugment, in order to prevent overfitting for effective few-shot text classification. By integrating contrastive learning, the discriminative text issue can be mitigated. Experiments on the Kaggle Short Scoring Dataset demonstrate that the ProtSi Network outperforms the most recent baseline models in terms of accuracy and quadratic weighted kappa.
Functional Optimization Reinforcement Learning for Real-Time Bidding
Jul 03, 2022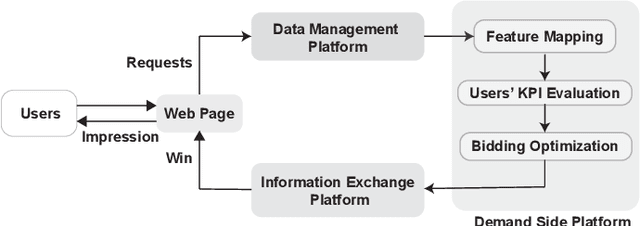
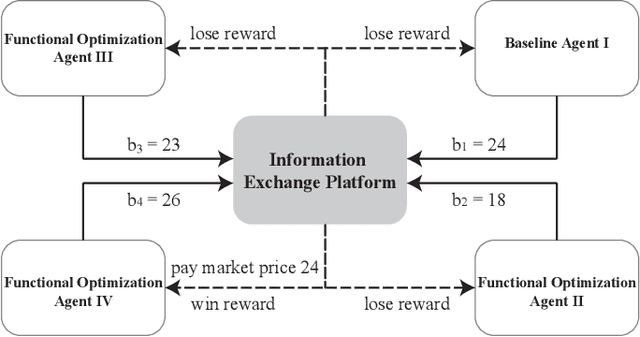
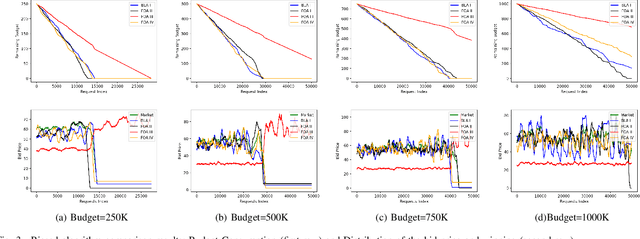
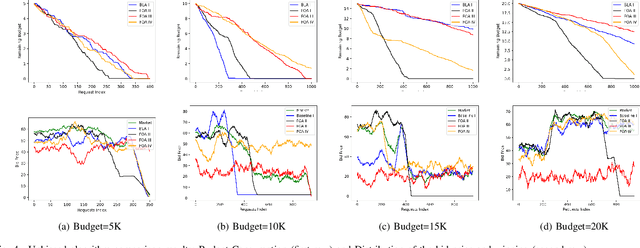
Real-time bidding is the new paradigm of programmatic advertising. An advertiser wants to make the intelligent choice of utilizing a \textbf{Demand-Side Platform} to improve the performance of their ad campaigns. Existing approaches are struggling to provide a satisfactory solution for bidding optimization due to stochastic bidding behavior. In this paper, we proposed a multi-agent reinforcement learning architecture for RTB with functional optimization. We designed four agents bidding environment: three Lagrange-multiplier based functional optimization agents and one baseline agent (without any attribute of functional optimization) First, numerous attributes have been assigned to each agent, including biased or unbiased win probability, Lagrange multiplier, and click-through rate. In order to evaluate the proposed RTB strategy's performance, we demonstrate the results on ten sequential simulated auction campaigns. The results show that agents with functional actions and rewards had the most significant average winning rate and winning surplus, given biased and unbiased winning information respectively. The experimental evaluations show that our approach significantly improve the campaign's efficacy and profitability.