 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen, Reliable, and Collective: A Community-Driven Framework for Tool-Using AI Agents
Mar 31, 2026Tool-integrated LLMs can retrieve, compute, and take real-world actions via external tools, but reliability remains a key bottleneck. We argue that failures stem from both tool-use accuracy (how well an agent invokes a tool) and intrinsic tool accuracy (the tool's own correctness), while most prior work emphasizes the former. We introduce OpenTools, a community-driven toolbox that standardizes tool schemas, provides lightweight plug-and-play wrappers, and evaluates tools with automated test suites and continuous monitoring. We also release a public web demo where users can run predefined agents and tools and contribute test cases, enabling reliability reports to evolve as tools change. OpenTools includes the core framework, an initial tool set, evaluation pipelines, and a contribution protocol. Experiments and evaluations show improved end-to-end reproducibility and task performance; community-contributed, higher-quality task-specific tools deliver 6%-22% relative gains over an existing toolbox across multiple agent architectures on downstream tasks and benchmarks, highlighting the importance of intrinsic tool accuracy.
Optimizing Decomposition for Optimal Claim Verification
Mar 19, 2025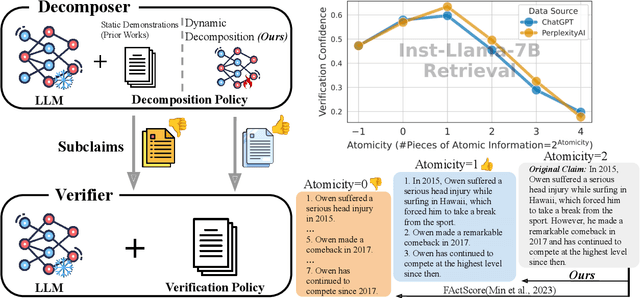
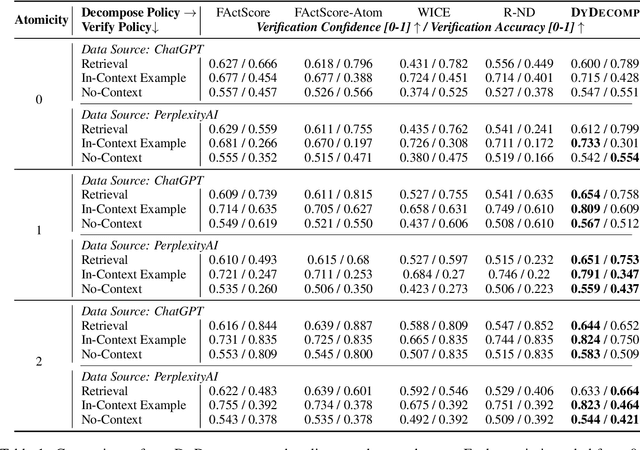
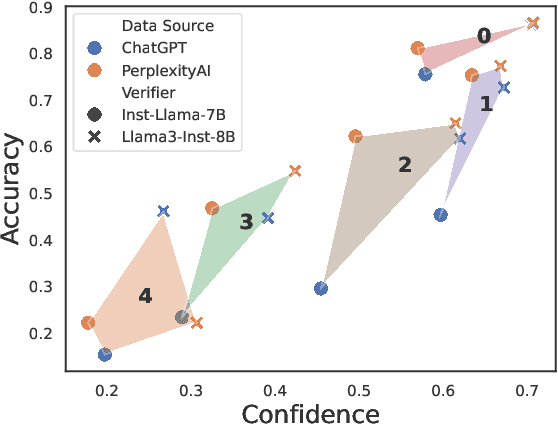
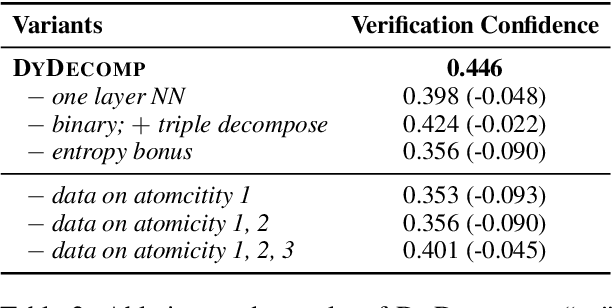
Current research on the \textit{Decompose-Then-Verify} paradigm for evaluating the factuality of long-form text typically treats decomposition and verification in isolation, overlooking their interactions and potential misalignment. We find that existing decomposition policies, typically hand-crafted demonstrations, do not align well with downstream verifiers in terms of atomicity -- a novel metric quantifying information density -- leading to suboptimal verification results. We formulate finding the optimal decomposition policy for optimal verification as a bilevel optimization problem. To approximate a solution for this strongly NP-hard problem, we propose dynamic decomposition, a reinforcement learning framework that leverages verifier feedback to learn a policy for dynamically decomposing claims to verifier-preferred atomicity. Experimental results show that dynamic decomposition outperforms existing decomposition policies, improving verification confidence by 0.07 and accuracy by 0.12 (on a 0-1 scale) on average across varying verifiers, datasets, and atomcities of input claims.
Embedding Mental Health Discourse for Community Recommendation
Jul 08, 2023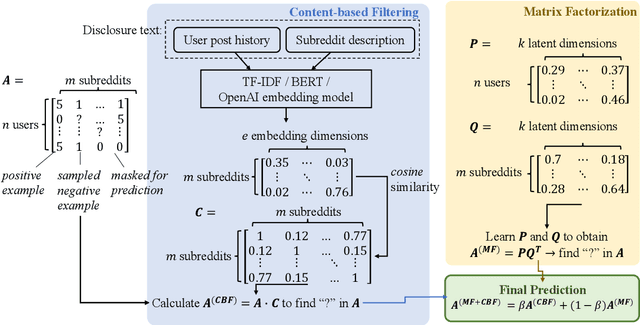
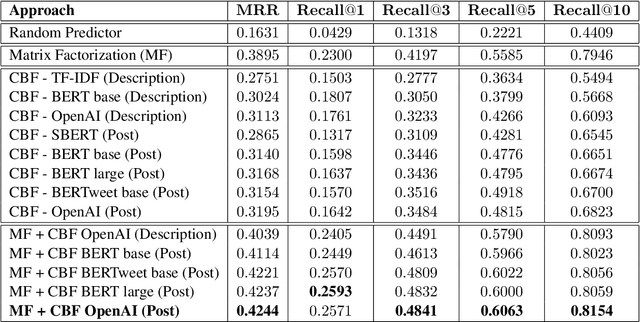
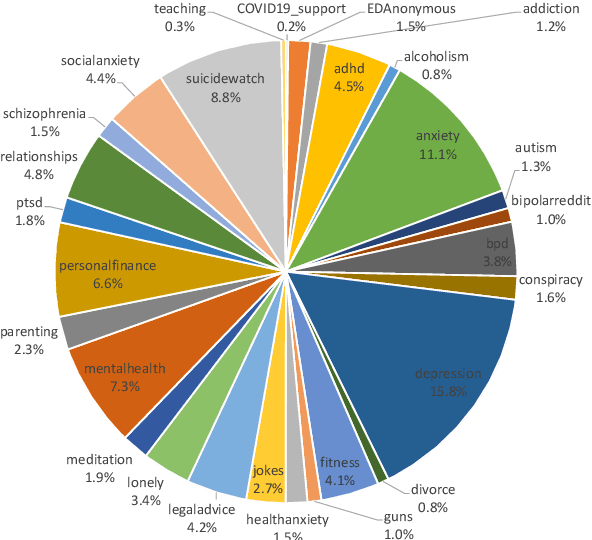
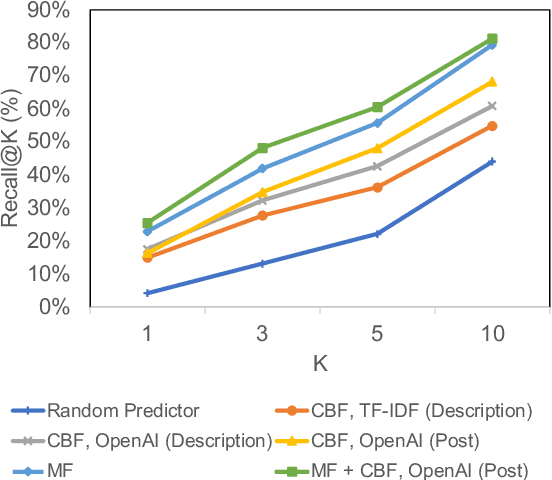
Our paper investigates the use of discourse embedding techniques to develop a community recommendation system that focuses on mental health support groups on social media. Social media platforms provide a means for users to anonymously connect with communities that cater to their specific interests. However, with the vast number of online communities available, users may face difficulties in identifying relevant groups to address their mental health concerns. To address this challenge, we explore the integration of discourse information from various subreddit communities using embedding techniques to develop an effective recommendation system. Our approach involves the use of content-based and collaborative filtering techniques to enhance the performance of the recommendation system. Our findings indicate that the proposed approach outperforms the use of each technique separately and provides interpretability in the recommendation process.
A Quantitative Review on Language Model Efficiency Research
May 28, 2023



Language models (LMs) are being scaled and becoming powerful. Improving their efficiency is one of the core research topics in neural information processing systems. Tay et al. (2022) provided a comprehensive overview of efficient Transformers that have become an indispensable staple in the field of NLP. However, in the section of "On Evaluation", they left an open question "which fundamental efficient Transformer one should consider," answered by "still a mystery" because "many research papers select their own benchmarks." Unfortunately, there was not quantitative analysis about the performances of Transformers on any benchmarks. Moreover, state space models (SSMs) have demonstrated their abilities of modeling long-range sequences with non-attention mechanisms, which were not discussed in the prior review. This article makes a meta analysis on the results from a set of papers on efficient Transformers as well as those on SSMs. It provides a quantitative review on LM efficiency research and gives suggestions for future research.
Wound Healing Modeling Using Partial Differential Equation and Deep Learning
Nov 27, 2021



The process of wound healing has been an active area of research around the world. The problem is the wounds of different patients heal differently. For example, patients with a background of diabetes may have difficulties in healing [1]. By clearly understanding this process, we can determine the type and quantity of medicine to give to patients with varying types of wounds. In this research, we use a variation of the Alternating Direction Implicit method to solve a partial differential equation that models part of the wound healing process. Wound images are used as the dataset that we analyze. To segment the image's wound, we implement deep learning-based models. We show that the combination of a variant of the Alternating Direction Implicit method and Deep Learning provides a reasonably accurate model for the process of wound healing. To the best of our knowledge, this is the first attempt to combine both numerical PDE and deep learning techniques in an automated system to capture the long-term behavior of wound healing.
Image-based Vehicle Re-identification Model with Adaptive Attention Modules and Metadata Re-ranking
Jul 03, 2020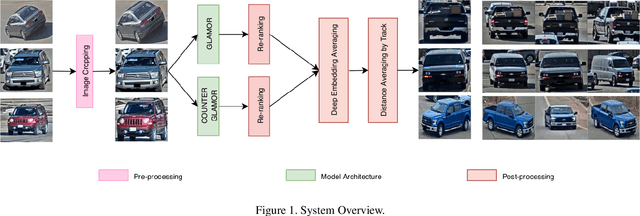
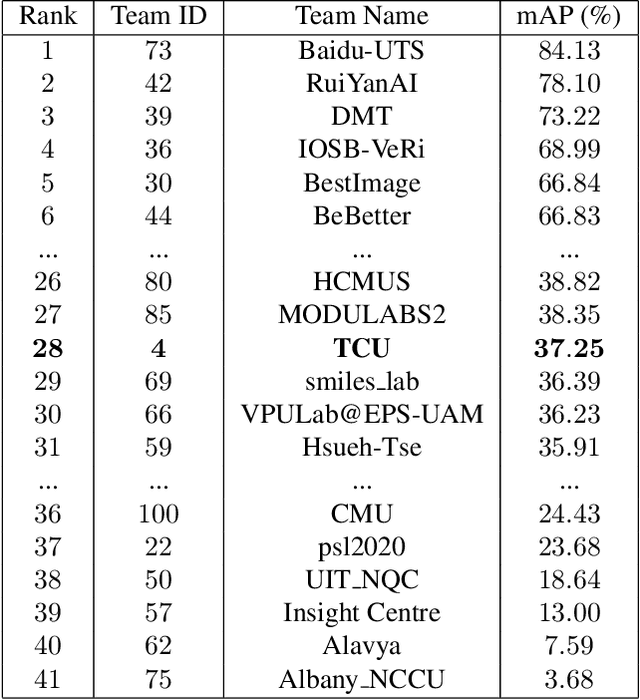

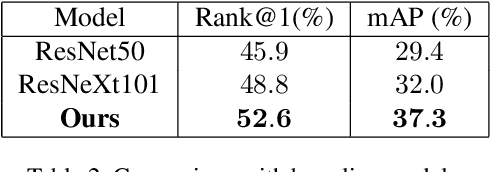
Vehicle Re-identification is a challenging task due to intra-class variability and inter-class similarity across non-overlapping cameras. To tackle these problems, recently proposed methods require additional annotation to extract more features for false positive image exclusion. In this paper, we propose a model powered by adaptive attention modules that requires fewer label annotations but still out-performs the previous models. We also include a re-ranking method that takes account of the importance of metadata feature embeddings in our paper. The proposed method is evaluated on CVPR AI City Challenge 2020 dataset and achieves mAP of 37.25% in Track 2.