 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHashtag Re-Appropriation for Audience Control on Recommendation-Driven Social Media Xiaohongshu (rednote)
Jan 30, 2025



Algorithms have played a central role in personalized recommendations on social media. However, they also present significant obstacles for content creators trying to predict and manage their audience reach. This issue is particularly challenging for marginalized groups seeking to maintain safe spaces. Our study explores how women on Xiaohongshu (rednote), a recommendation-driven social platform, proactively re-appropriate hashtags (e.g., #Baby Supplemental Food) by using them in posts unrelated to their literal meaning. The hashtags were strategically chosen from topics that would be uninteresting to the male audience they wanted to block. Through a mixed-methods approach, we analyzed the practice of hashtag re-appropriation based on 5,800 collected posts and interviewed 24 active users from diverse backgrounds to uncover users' motivations and reactions towards the re-appropriation. This practice highlights how users can reclaim agency over content distribution on recommendation-driven platforms, offering insights into self-governance within algorithmic-centered power structures.
A Quantitative Review on Language Model Efficiency Research
May 28, 2023



Language models (LMs) are being scaled and becoming powerful. Improving their efficiency is one of the core research topics in neural information processing systems. Tay et al. (2022) provided a comprehensive overview of efficient Transformers that have become an indispensable staple in the field of NLP. However, in the section of "On Evaluation", they left an open question "which fundamental efficient Transformer one should consider," answered by "still a mystery" because "many research papers select their own benchmarks." Unfortunately, there was not quantitative analysis about the performances of Transformers on any benchmarks. Moreover, state space models (SSMs) have demonstrated their abilities of modeling long-range sequences with non-attention mechanisms, which were not discussed in the prior review. This article makes a meta analysis on the results from a set of papers on efficient Transformers as well as those on SSMs. It provides a quantitative review on LM efficiency research and gives suggestions for future research.
Multi-Round Parsing-based Multiword Rules for Scientific OpenIE
Aug 04, 2021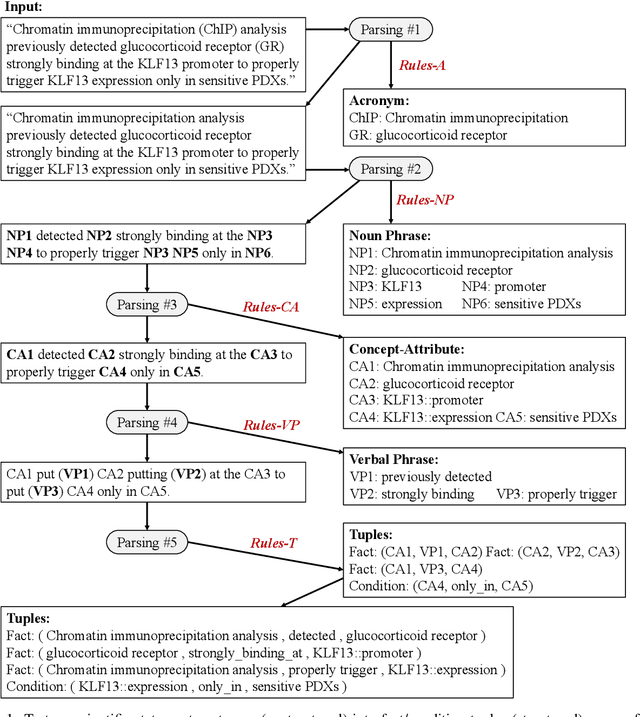
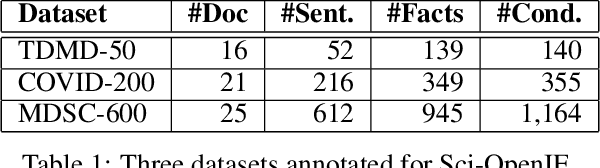

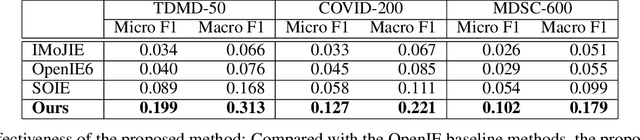
Information extraction (IE) in scientific literature has facilitated many down-stream tasks. OpenIE, which does not require any relation schema but identifies a relational phrase to describe the relationship between a subject and an object, is being a trending topic of IE in sciences. The subjects, objects, and relations are often multiword expressions, which brings challenges for methods to identify the boundaries of the expressions given very limited or even no training data. In this work, we present a set of rules for extracting structured information based on dependency parsing that can be applied to any scientific dataset requiring no expert's annotation. Results on novel datasets show the effectiveness of the proposed method. We discuss negative results as well.