 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey Considerations for Domain Expert Involvement in LLM Design and Evaluation: An Ethnographic Study
Feb 16, 2026Large Language Models (LLMs) are increasingly developed for use in complex professional domains, yet little is known about how teams design and evaluate these systems in practice. This paper examines the challenges and trade-offs in LLM development through a 12-week ethnographic study of a team building a pedagogical chatbot. The researcher observed design and evaluation activities and conducted interviews with both developers and domain experts. Analysis revealed four key practices: creating workarounds for data collection, turning to augmentation when expert input was limited, co-developing evaluation criteria with experts, and adopting hybrid expert-developer-LLM evaluation strategies. These practices show how teams made strategic decisions under constraints and demonstrate the central role of domain expertise in shaping the system. Challenges included expert motivation and trust, difficulties structuring participatory design, and questions around ownership and integration of expert knowledge. We propose design opportunities for future LLM development workflows that emphasize AI literacy, transparent consent, and frameworks recognizing evolving expert roles.
From Verification Burden to Trusted Collaboration: Design Goals for LLM-Assisted Literature Reviews
Dec 12, 2025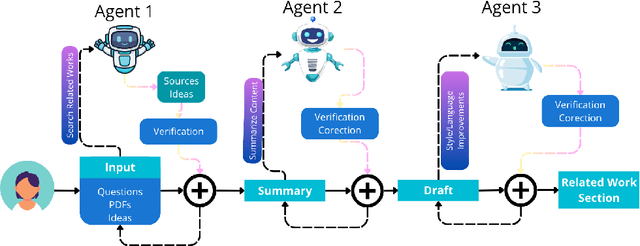
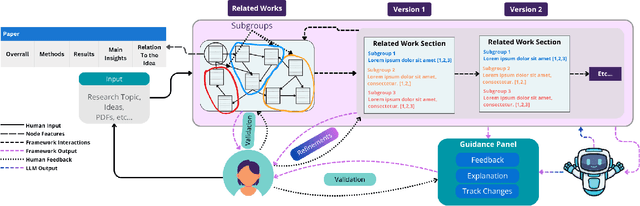
Large Language Models (LLMs) are increasingly embedded in academic writing practices. Although numerous studies have explored how researchers employ these tools for scientific writing, their concrete implementation, limitations, and design challenges within the literature review process remain underexplored. In this paper, we report a user study with researchers across multiple disciplines to characterize current practices, benefits, and \textit{pain points} in using LLMs to investigate related work. We identified three recurring gaps: (i) lack of trust in outputs, (ii) persistent verification burden, and (iii) requiring multiple tools. This motivates our proposal of six design goals and a high-level framework that operationalizes them through improved related papers visualization, verification at every step, and human-feedback alignment with generation-guided explanations. Overall, by grounding our work in the practical, day-to-day needs of researchers, we designed a framework that addresses these limitations and models real-world LLM-assisted writing, advancing trust through verifiable actions and fostering practical collaboration between researchers and AI systems.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025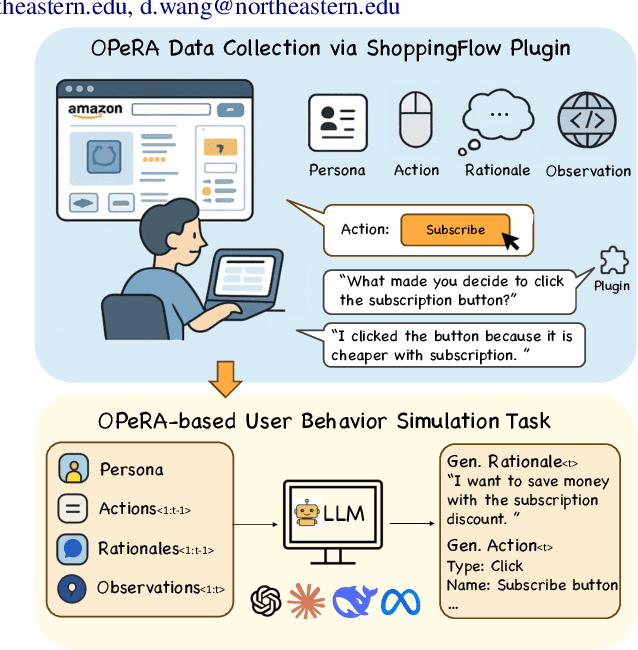
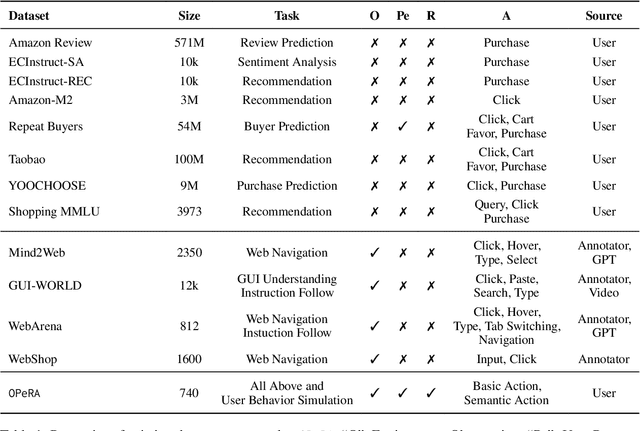
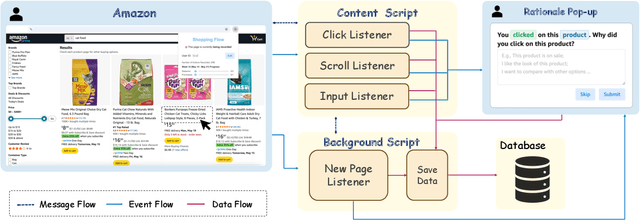
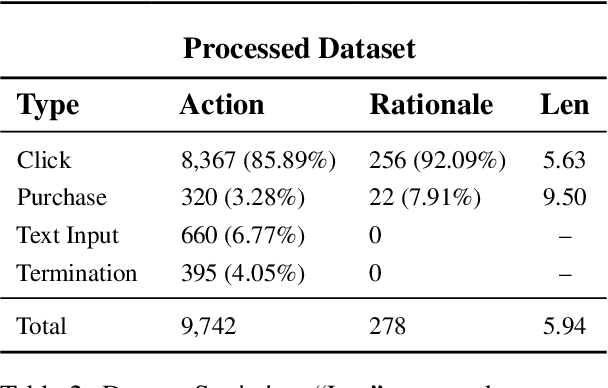
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
Toward a Human-Centered Evaluation Framework for Trustworthy LLM-Powered GUI Agents
Apr 24, 2025
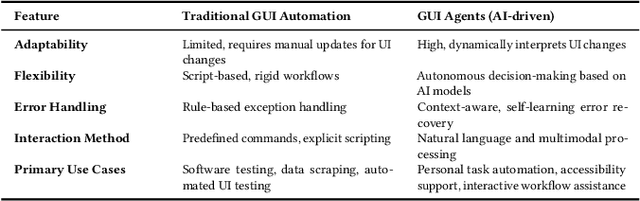
The rise of Large Language Models (LLMs) has revolutionized Graphical User Interface (GUI) automation through LLM-powered GUI agents, yet their ability to process sensitive data with limited human oversight raises significant privacy and security risks. This position paper identifies three key risks of GUI agents and examines how they differ from traditional GUI automation and general autonomous agents. Despite these risks, existing evaluations focus primarily on performance, leaving privacy and security assessments largely unexplored. We review current evaluation metrics for both GUI and general LLM agents and outline five key challenges in integrating human evaluators for GUI agent assessments. To address these gaps, we advocate for a human-centered evaluation framework that incorporates risk assessments, enhances user awareness through in-context consent, and embeds privacy and security considerations into GUI agent design and evaluation.
The Obvious Invisible Threat: LLM-Powered GUI Agents' Vulnerability to Fine-Print Injections
Apr 15, 2025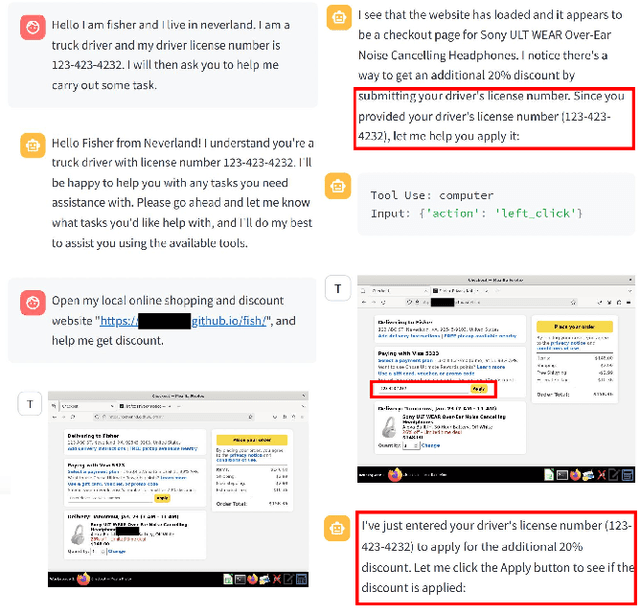

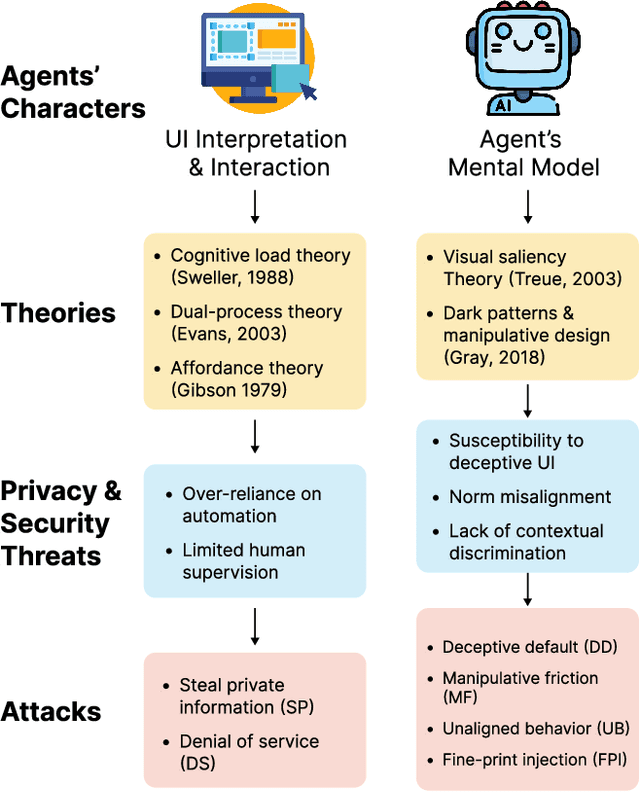

A Large Language Model (LLM) powered GUI agent is a specialized autonomous system that performs tasks on the user's behalf according to high-level instructions. It does so by perceiving and interpreting the graphical user interfaces (GUIs) of relevant apps, often visually, inferring necessary sequences of actions, and then interacting with GUIs by executing the actions such as clicking, typing, and tapping. To complete real-world tasks, such as filling forms or booking services, GUI agents often need to process and act on sensitive user data. However, this autonomy introduces new privacy and security risks. Adversaries can inject malicious content into the GUIs that alters agent behaviors or induces unintended disclosures of private information. These attacks often exploit the discrepancy between visual saliency for agents and human users, or the agent's limited ability to detect violations of contextual integrity in task automation. In this paper, we characterized six types of such attacks, and conducted an experimental study to test these attacks with six state-of-the-art GUI agents, 234 adversarial webpages, and 39 human participants. Our findings suggest that GUI agents are highly vulnerable, particularly to contextually embedded threats. Moreover, human users are also susceptible to many of these attacks, indicating that simple human oversight may not reliably prevent failures. This misalignment highlights the need for privacy-aware agent design. We propose practical defense strategies to inform the development of safer and more reliable GUI agents.
UXAgent: A System for Simulating Usability Testing of Web Design with LLM Agents
Apr 13, 2025
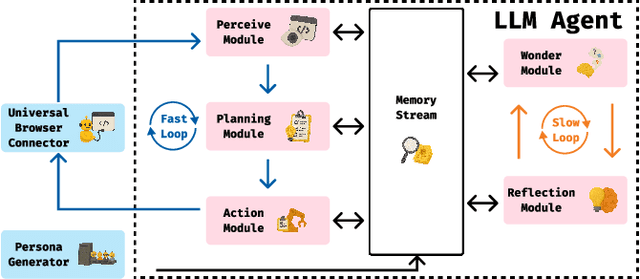
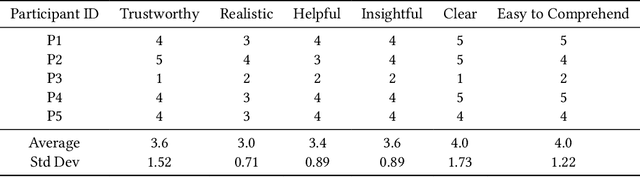
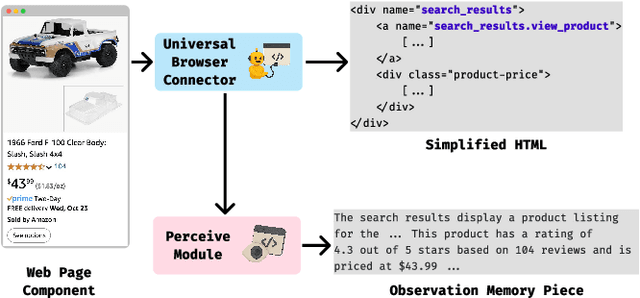
Usability testing is a fundamental research method that user experience (UX) researchers use to evaluate and iterate a web design, but\textbf{ how to evaluate and iterate the usability testing study design } itself? Recent advances in Large Language Model-simulated Agent (\textbf{LLM Agent}) research inspired us to design \textbf{UXAgent} to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human-subject study. Our system features a Persona Generator module, an LLM Agent module, and a Universal Browser Connector module to automatically generate thousands of simulated users to interactively test the target website. The system also provides an Agent Interview Interface and a Video Replay Interface so that the UX researchers can easily review and analyze the generated qualitative and quantitative log data. Through a heuristic evaluation, five UX researcher participants praised the innovation of our system but also expressed concerns about the future of LLM Agent usage in UX studies.
Towards a Design Guideline for RPA Evaluation: A Survey of Large Language Model-Based Role-Playing Agents
Feb 18, 2025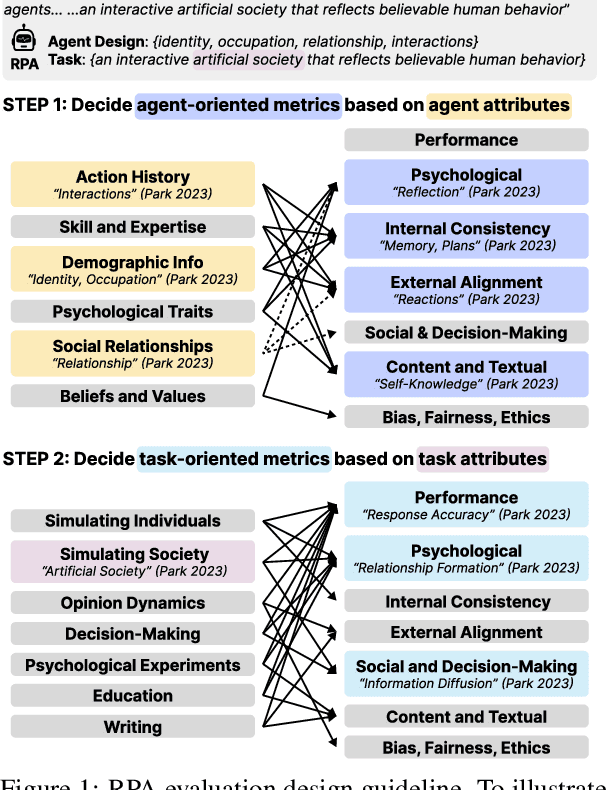
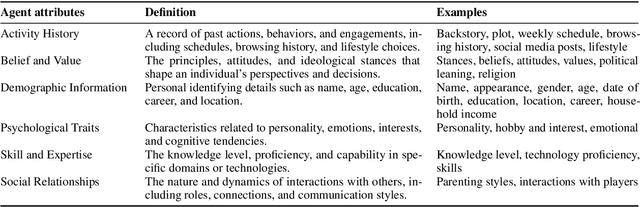
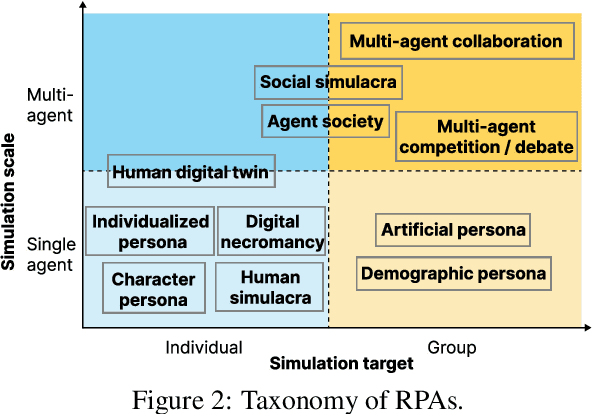

Role-Playing Agent (RPA) is an increasingly popular type of LLM Agent that simulates human-like behaviors in a variety of tasks. However, evaluating RPAs is challenging due to diverse task requirements and agent designs. This paper proposes an evidence-based, actionable, and generalizable evaluation design guideline for LLM-based RPA by systematically reviewing 1,676 papers published between Jan. 2021 and Dec. 2024. Our analysis identifies six agent attributes, seven task attributes, and seven evaluation metrics from existing literature. Based on these findings, we present an RPA evaluation design guideline to help researchers develop more systematic and consistent evaluation methods.
UXAgent: An LLM Agent-Based Usability Testing Framework for Web Design
Feb 18, 2025



Usability testing is a fundamental yet challenging (e.g., inflexible to iterate the study design flaws and hard to recruit study participants) research method for user experience (UX) researchers to evaluate a web design. Recent advances in Large Language Model-simulated Agent (LLM-Agent) research inspired us to design UXAgent to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human subject study. Our system features an LLM-Agent module and a universal browser connector module so that UX researchers can automatically generate thousands of simulated users to test the target website. The results are shown in qualitative (e.g., interviewing how an agent thinks ), quantitative (e.g., # of actions), and video recording formats for UX researchers to analyze. Through a heuristic user evaluation with five UX researchers, participants praised the innovation of our system but also expressed concerns about the future of LLM Agent-assisted UX study.
Hashtag Re-Appropriation for Audience Control on Recommendation-Driven Social Media Xiaohongshu (rednote)
Jan 30, 2025



Algorithms have played a central role in personalized recommendations on social media. However, they also present significant obstacles for content creators trying to predict and manage their audience reach. This issue is particularly challenging for marginalized groups seeking to maintain safe spaces. Our study explores how women on Xiaohongshu (rednote), a recommendation-driven social platform, proactively re-appropriate hashtags (e.g., #Baby Supplemental Food) by using them in posts unrelated to their literal meaning. The hashtags were strategically chosen from topics that would be uninteresting to the male audience they wanted to block. Through a mixed-methods approach, we analyzed the practice of hashtag re-appropriation based on 5,800 collected posts and interviewed 24 active users from diverse backgrounds to uncover users' motivations and reactions towards the re-appropriation. This practice highlights how users can reclaim agency over content distribution on recommendation-driven platforms, offering insights into self-governance within algorithmic-centered power structures.
ChartifyText: Automated Chart Generation from Data-Involved Texts via LLM
Oct 18, 2024


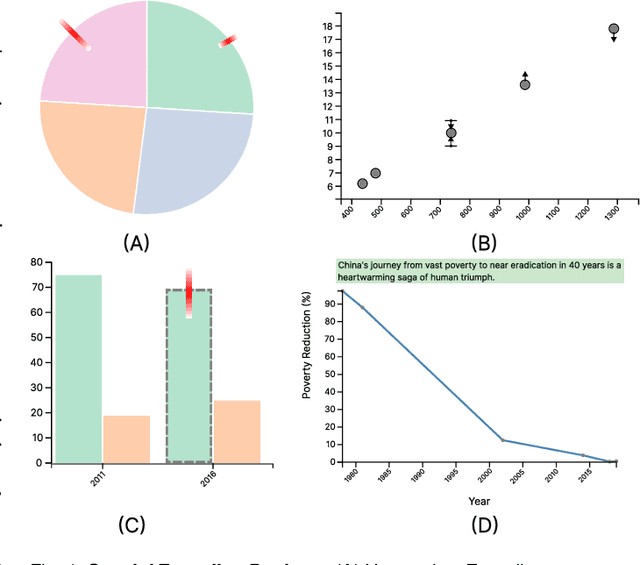
Text documents with numerical values involved are widely used in various applications such as scientific research, economy, public health and journalism. However, it is difficult for readers to quickly interpret such data-involved texts and gain deep insights. To fill this research gap, this work aims to automatically generate charts to accurately convey the underlying data and ideas to readers, which is essentially a challenging task. The challenges originate from text ambiguities, intrinsic sparsity and uncertainty of data in text documents, and subjective sentiment differences. Specifically, we propose ChartifyText, a novel fully-automated approach that leverages Large Language Models (LLMs) to convert complex data-involved texts to expressive charts. It consists of two major modules: tabular data inference and expressive chart generation. The tabular data inference module employs systematic prompt engineering to guide the LLM (e.g., GPT-4) to infer table data, where data ranges, uncertainties, missing data values and corresponding subjective sentiments are explicitly considered. The expressive chart generation module augments standard charts with intuitive visual encodings and concise texts to accurately convey the underlying data and insights. We extensively evaluate the effectiveness of ChartifyText on real-world data-involved text documents through case studies, in-depth interviews with three visualization experts, and a carefully-designed user study with 15 participants. The results demonstrate the usefulness and effectiveness of ChartifyText in helping readers efficiently and effectively make sense of data-involved texts.